
Las organizaciones administran el contenido en múltiples idiomas a medida que se expanden a nivel mundial. Las plataformas de comercio electrónico, los sistemas de atención al cliente y las bases de conocimiento requieren capacidades de búsqueda multilingües eficientes para servir diversas bases de usuarios de guisa efectiva. Este enfoque de búsqueda unificado ayuda a las organizaciones multinacionales a sostener repositorios de contenido centralizado al tiempo que se asegura de que los usuarios, independientemente de su jerga preferido, puedan encontrar y entrar efectivamente a la información relevante.
La construcción de aplicaciones de varios idiomas que utilizan analizadores de idiomas con OpenSearch comúnmente implica un desafío significativo: los documentos de varios idiomas requieren un preprocesamiento manual. Esto significa que en su aplicación, para cada documento, primero debe identificar el jerga de cada campo, luego clasificarlo y etiquetarlo, acumular contenido en campos de jerga separados y predefinidos (por ejemplo, name_en, name_es, etc.) para usar Analizadores de idiomas En examen de mejorar la relevancia de búsqueda. Este esfuerzo del banda del cliente es enredado, agrega carga de trabajo para la detección del idioma, la desaceleración de la ingestión de datos y los problemas de precisión del aventura de precisión si los idiomas se identifican erróneamente. Es un enfoque sindical intensivo. Sin confiscación, Servicio de Amazon OpenSearch 2.15+ presenta un Procesador de inferencia de ML. Esta nueva característica identifica y marbete automáticamente los lenguajes de documentos durante la ingestión, racionalizando el proceso y eliminando la carga de su aplicación.
Al utilizar el poder de la IA y usar el modelado de datos consciente del contexto y la selección de analizador inteligente, esta alternativa automatizada agiliza el procesamiento de documentos al minimizar el etiquetado de jerga manual y permite la detección cibernética del jerga durante la ingestión, proporcionando organizaciones sofisticadas capacidades de búsqueda multilingüe.
El uso de la identificación del idioma en el servicio OpenSearch ofrece los siguientes beneficios:
- Experiencia de legatario mejorada – Los usuarios ahora pueden encontrar contenido relevante independientemente del idioma que busquen
- Aumento del descubrimiento de contenido – El servicio puede producir contenido valioso a través de silos de jerga
- Precisión de búsqueda mejorada -Los analizadores específicos del jerga proporcionan una mejor relevancia de búsqueda
- Procesamiento automatizado – Puede disminuir el etiquetado y la clasificación del idioma manual
En esta publicación, compartimos cómo implementar una alternativa de búsqueda multilingüe escalable utilizando el servicio OpenSearch.
Descripción genérico de la alternativa
La alternativa elimina el preprocesamiento del jerga manual al detectar y manejar automáticamente contenido multilingüe durante la ingestión de documentos. En división de crear manualmente campos de idiomas separados (en_notes, es_notes, etc.) o implementar sistemas de detección de idiomas personalizados, el procesador de inferencia ML identifica los idiomas y crea asignaciones de campo apropiadas.
Este enfoque automatizado mejoramiento la precisión en comparación con los métodos manuales tradicionales y reduce la complejidad del explicación y la sobrecarga de procesamiento, lo que permite a las organizaciones centrarse en ofrecer mejores experiencias de búsqueda a sus usuarios globales.
La alternativa comprende los siguientes componentes esencia:
- Procesador de inferencia de ML – Invoca los modelos ML durante la ingestión de documentos para enriquecer el contenido con metadatos del idioma
- Integración de Amazon Sagemaker -Hosts modelos de identificación de jerga previamente capacitados que analizan los campos de texto y las predicciones de jerga de devolución
- Indexación específica del idioma – Aplica analizadores apropiados basados en idiomas detectados, proporcionando el manejo adecuado de las palabras de soporte, la normalización de los carácter y la normalización del carácter
- Situación de conector – Habilita la comunicación segura entre el servicio OpenSearch y Amazon Sagemaker puntos finales a través de Dirección de identidad y comunicación de AWS (IAM) Autenticación basada en roles.
El futuro diagrama ilustra el flujo de trabajo de la tubería de detección de idiomas.
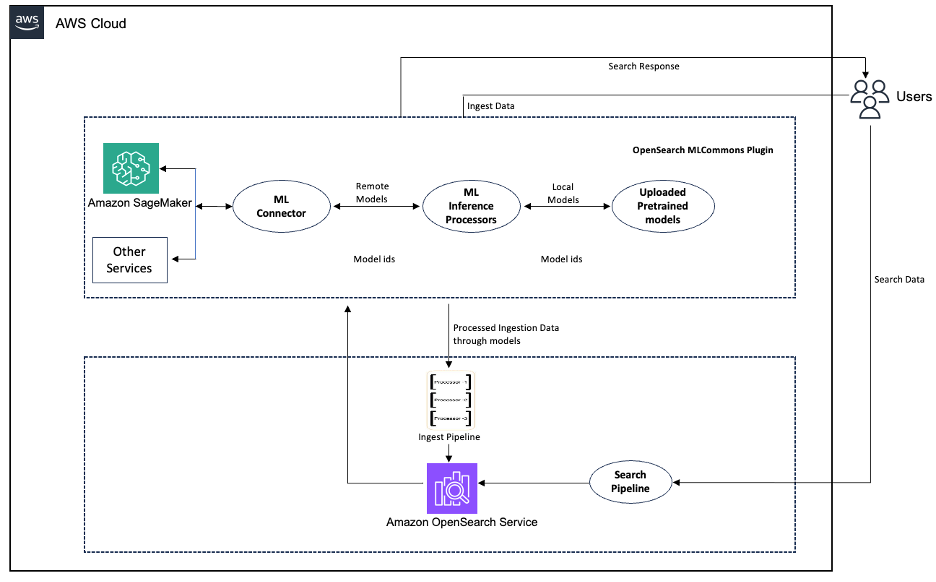
Figura 1: flujo de trabajo de la tubería de detección de idiomas
Este ejemplo demuestra la clasificación de texto usando XLM-ROBERTA-BASE Para la detección de idiomas en Amazon Sagemaker. Tiene flexibilidad para nominar sus modelos y, alternativamente, puede usar el Capacidades de detección de idiomas incorporadas de Amazon Comprender.
En las siguientes secciones, recorremos los pasos para implementar la alternativa. Para obtener instrucciones de implementación detalladas, incluidos ejemplos de código y plantillas de configuración, consulte el tutorial integral en el OpenSearch ML Commons GitHub Repository.
Requisitos previos
Debes tener los siguientes requisitos previos:
Implementar el maniquí
Implementar un idioma previamente capacitado Maniquí de identificación en Amazon Sagemaker. El maniquí XLM-Roberta proporciona capacidades robustas de detección de idiomas multilingües adecuados para la mayoría de los casos de uso.
Configurar el conector
Crear un Conector ml Para establecer una conexión segura entre el servicio OpenSearch y los puntos finales de Amazon Sagemaker, principalmente para tareas de detección de idiomas. El proceso comienza con la configuración de la autenticación a través de Roles y políticas de IAMaplicando permisos adecuados para los dos servicios para comunicarse de forma segura.
Posteriormente de configurar el conector con las URL y credenciales apropiadas de punto final, el maniquí es registrado e implementado En el servicio de OpenSearch y su modelid se usa en pasos posteriores.
Respuesta de muestra:
Posteriormente de configurar el conector, puede probar es por Giro de texto al maniquí a través del servicio OpenSearch, y devolverá el jerga detectado (por ejemplo, mandar «proponer que esta es una prueba» devuelve en inglés).
Configure la tubería de ingesta
Configurar la tubería de ingestaque utiliza procesadores de inferencia ML para detectar automáticamente el jerga del contenido en los campos de nombre y notas de los documentos entrantes. Posteriormente de la detección del idioma, la tubería crea nuevos campos específicos del idioma copiando el contenido llamativo a nuevos campos con sufijos de idioma (por ejemplo, name_en para contenido en inglés).
La tubería utiliza un procesador ML_Inference para realizar los procesadores de detección y copia del idioma para crear los nuevos campos específicos del idioma, lo que hace que sea sencillo manejar el contenido multilingüe en su índice de servicio OpenSearch.
Configurar los documentos de índice e ingerir
Crear un índice con la tubería de ingesta Eso detecta automáticamente el jerga de los documentos entrantes y aplica un exploración apropiado específico del jerga. Cuando se ingieren documentosel sistema identifica el jerga de los campos esencia, crea versiones específicas del jerga de esos campos y los indexa utilizando el analizador de jerga correcto. Esto permite una búsqueda apto y precisa en todos los documentos en múltiples idiomas sin requerir una explicación de idioma manual para cada documento.
Aquí hay una indicación API de creación de índice de muestra que demuestra diferentes asignaciones de idiomas.
A continuación, ingere este documento de entrada en teutón
El texto teutón utilizado en el código preliminar se procesará utilizando un analizador específico teutón, que respalda el manejo adecuado de las características específicas del jerga, como palabras compuestas y caracteres especiales.
Posteriormente de la ingestión exitosa en el servicio OpenSearch, el documento resultante aparece de la futuro guisa:
Documentos de búsqueda
Este paso demuestra el capacidad de búsqueda Posteriormente de la configuración multilingüe. Al usar una consulta multi_match con los campos Name_*, examen en todos los campos de nombres específicos del jerga (name_en, name_es, name_de) y encuentra con éxito el documento gachupin cuando examen «comprar» porque el contenido se analizó correctamente utilizando el analizador gachupin. Este ejemplo muestra cómo la indexación específica del jerga permite los resultados de búsqueda precisos en el idioma correcto sin pobreza de especificar en qué idioma está buscando.
Esta búsqueda encuentra correctamente el documento gachupin porque el campo Name_ES se analiza utilizando el analizador de gachupin:
Destreza
Para evitar cargos continuos y eliminar los fortuna creados en este tutorial, realice los siguientes pasos de cepillado
- Eliminar el Dominio del servicio de OpenSearch. Esto detiene los costos de almacenamiento para sus datos vectorizados y cualquier cargo de cuenta asociado.
- Eliminar el conector ML Eso vincula su servicio OpenSearch a su maniquí de estudios automotriz.
- Finalmente, poso tu Amazon Sagemaker Endpoints y fortuna.
Conclusión
La implementación de la búsqueda multilingüe con el servicio de OpenSearch puede ayudar a las organizaciones a desembarcar barreras del idioma y desbloquear el valencia total de su contenido integral. El procesador de inferencias ML proporciona un enfoque escalable y automatizado para la detección del idioma que mejoramiento la precisión de búsqueda y la experiencia del legatario.
Esta alternativa aborda la creciente pobreza de administración de contenido multilingüe a medida que las organizaciones se expanden a nivel mundial. Al detectar automáticamente los lenguajes de documentos y aplicar el procesamiento lingüístico apropiado, las empresas pueden ofrecer experiencias de búsqueda integrales que sirven diversas bases de usuarios de guisa efectiva.
Sobre los autores