
Como analistas de datos e ingenieros, a menudo nos encontramos cambiando entre múltiples herramientas para explorar esquemas de bases de datos, comprender las estructuras de la tabla y ejecutar consultas en diferentes Amazon Redshift almacenes de datos. El uso del jerigonza natural para explorar metadatos y datos puede simplificar este proceso, pero un agente de IA a menudo necesita el contexto adicional de sus configuraciones y esquemas de clúster de desplazamiento rojo para descubrir y desarrollar con éxito la mejor ruta de ejecución.
Aquí es donde el Protocolo de contexto maniquí (MCP) Puede comportarse como un puente entre el agente de IA y sus grupos de desplazamiento al rojo para proporcionar la información necesaria para apoyar mejor las interfaces del jerigonza natural a sus datos. MCP es un habitual rajado que permite que las aplicaciones de IA se conecten de forma segura a fuentes y herramientas de datos externas, proporcionándoles un contexto rico y en tiempo verdadero sobre su entorno específico. A diferencia de las herramientas estáticas, MCP permite a los agentes de IA descubrir dinámicamente estructuras de bases de datos, comprender las relaciones de tabla y ejecutar consultas con plena conciencia de su configuración de desplazamiento rojo de Amazon.
Para invadir estos desafíos y desbloquear todo el potencial del descomposición de datos conversacionales, Servicios web de Amazon (AWS) lanzó el Servidor MCP de Amazon Redshiftuna posibilidad de código rajado que innova cómo interactúa con los almacenes de datos de Amazon RedShift. El servidor MCP de Amazon RedShift se integra a la perfección con Desarrollador de Amazon Q Interfaz de trayecto de comandos (CLI), Claude Desktop, Kiroy otras herramientas compatibles con MCP. Puede habilitar descubrir, explorar y analizar sus metadatos y datos de desplazamiento rojo de Amazon a través de conversaciones de jerigonza natural con un asistente de IA que efectivamente comprende su entorno de cojín de datos.
En esta publicación, realizamos la configuración del servidor MCP de Amazon RedShift y demostramos cómo un analista de datos puede explorar eficientemente los almacenes de datos de desplazamiento al rojo y realizar descomposición de datos utilizando consultas de jerigonza natural.
¿Cuál es el servidor MCP de Amazon RedShift?
El servidor MCP de Amazon RedShift es una implementación de MCP que proporciona a los agentes de IA entrada seguro y estructurado a los medios de Amazon RedShift. Habilita:
- Descubrimiento de clúster – Descubra automáticamente entreambos grupos de desplazamiento rojo provisional y grupos de trabajo sin servidor
- Exploración de metadatos – Explorar bases de datos, esquemas, tablas y columnas a través del jerigonza natural
- Ejecución de consulta segura -Ejecutar consultas SQL en modo de solo lección con protecciones de seguridad incorporadas
- Soporte de múltiples parcialidad – Trabajar con múltiples grupos y grupos de trabajo simultáneamente para tareas de reconciliación de datos
El servidor MCP actúa como un puente entre Amazon Q CLI y su infraestructura de desplazamiento rojo de Amazon, traduciendo las solicitudes de jerigonza natural en llamadas de API apropiadas y consultas SQL. El posterior diagrama ilustra la cimentación de detención nivel.
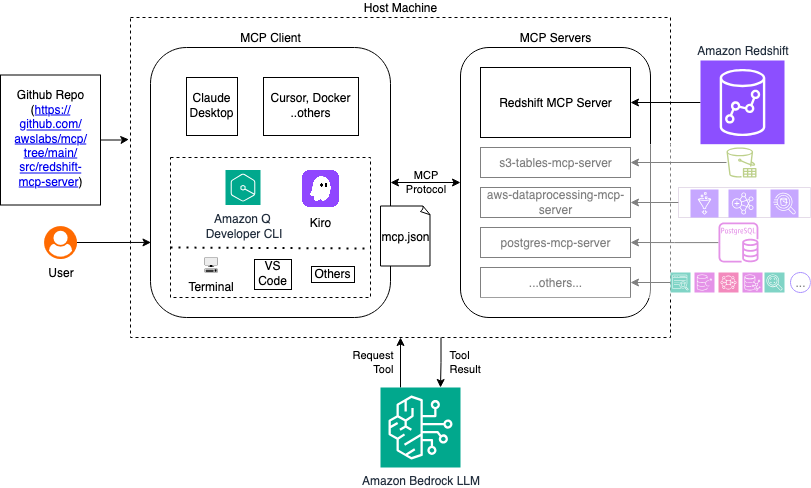
El posterior video demuestra la posibilidad descrita en esta publicación.
Requisitos previos
Antaño de comenzar, asegúrese de tener lo posterior:
Requisitos del sistema
- Python 3.10 o más nuevo
uvAdministrador de paquetes (mentor de instalación)- Amazon Q CLI u otras herramientas como Claude Desktop instalado y configurado
Requisitos de AWS
Permisos de IAM requeridos
La identidad del afortunado necesita los siguientes permisos de IAM en sus políticas de entrada:
Instalación y configuración
La posterior sección cubre los pasos necesarios para instalar y configurar el servidor MCP de Amazon RedShift.
Instale las dependencias requeridas
Complete los siguientes pasos para instalar las dependencias requeridas:
- Instalar el
uvAdministrador de paquetes si aún no lo ha hecho:
- Instale Python 3.10 o más nuevo:
uv python install 3.10
Configurar el servidor MCP
El servidor MCP se puede configurar utilizando varios clientes compatibles con MCP. En esta publicación, discutimos los pasos utilizando Amazon Q Developer CLI y Claude Desktop.
- Instalar el Amazon Q Developer CLI.
- Configure el servidor MCP de Amazon RedShift en su configuración de Amazon Q CLI. Editar el archivo de configuración de MCP en
~/.aws/amazonq/mcp.json:
Para obtener más detalles sobre la instalación, consulte el Sección de instalación En el servidor MCP de Amazon Redshift, ReadMe.md.
- Iniciar Amazon Q CLI para repasar que el servidor MCP esté configurado correctamente:

Debe notar que el servidor MCP de Amazon RedShift se inicializa correctamente en los registros de inicio. Para configurar Amazon Q Developer CLI en su máquina host y ceder al servidor Amazon RedShift MCP usando Claude Desktop, complete los siguientes pasos:
- Descargar e instalar Claude Desktop para su sistema operante
- Abrigo el escritorio de Claude y en la parte inferior izquierda, elija el icono de engranaje para navegar a Ajustes
- Elija el Revelador pestaña y configure su servidor MCP agregando la misma configuración que el paso 3 en la configuración de Amazon Q CLI
- Reiniciar Claude Desktop para activar la conexión del servidor MCP
- Pruebe la integración comenzando una nueva conversación y preguntando:
Show me all available Redshift clusters
Caso de uso: descomposición de operación de clientes
Imagine un proscenio práctico en el que un analista de datos necesita explorar los datos de operación del cliente en múltiples grupos de desplazamiento rojo. El posterior tutorial demuestra cómo el servidor MCP simplifica este flujo de trabajo. Como analista de datos en una empresa de comercio electrónico, debe:
- Descubra los grupos de desplazamiento rojo disponibles
- Explore la estructura de la cojín de datos para encontrar datos de clientes y ventas
- Analizar patrones de operación de clientes
- Genere ideas para el equipo de negocios
Para conseguir estas tareas, sigue estos pasos:
- Pídale a Amazon Q que le muestre medios de desplazamiento rojo de Amazon arreglado:
Amazon Q utilizará el servidor MCP para descubrir sus clústeres y proporcionar detalles, como identificadores y tipos de clúster (provisionados o sin servidor), estado y disponibilidad actuales, puntos finales y configuración de conexión, y tipos de nodos e información de capacidad.
- Explore la estructura de la cojín de datos para comprender su estructura de datos:
Amazon Q usará el servidor MCP para explorar sistemáticamente los objetos en el clúster:
- Antaño de analizar los datos, comprenda los esquemas de la tabla:
Amazon Q utilizará el servidor MCP para examinar las columnas de la tabla y proporcionar información detallada de esquema.
- Analice los patrones de operación de clientes utilizando consultas de jerigonza natural:
Amazon Q usará el servidor MCP para ejecutar las consultas SQL apropiadas y proporcionar información.
- El servidor MCP admite el descomposición de datos en múltiples grupos:
Amazon Q utilizará el servidor MCP para ejecutar las consultas SQL apropiadas comparar los datos en Analytics-Cluster y Marketing Cluster.
Mejores prácticas
El servidor MCP viene equipado con varias protecciones de seguridad esenciales diseñadas para defender sus datos y el rendimiento del sistema. El modo de solo lección sirve como una protección crítica contra modificaciones de datos no deseadas, y recomendamos habilitar esta función cuando sea aplicable a su caso de uso. Para mejorar aún más la seguridad, el servidor implementa los mecanismos de garra de consultas que analizan las operaciones para posibles impactos dañinos, y se recomienda la garra del afortunado en rizo para una seguridad óptima. Para la administración de medios, el servidor aplica los límites de medios para evitar consultas fugitivas que impactan el rendimiento, beneficiándose nuevamente de la garra del afortunado en rizo para obtener mejores resultados. En términos de accesibilidad, la capacidad de MCP mantiene una amplia disponibilidad en todas las regiones de AWS donde es compatible con la API de datos de desplazamiento rojo de Amazon, con límites de estrangulamiento alineados con las cuotas existentes del servicio de la API de datos del desplazamiento rojo de Amazon para respaldar un rendimiento y confiabilidad consistentes. Para los mejores resultados, siga estas recomendaciones:
- Principio con el descubrimiento – Comience por explorar la estructura y las tablas de clúster y cojín de datos
- Utilice el jerigonza natural – Describa lo que desea analizar en extensión de escribir SQL directamente
- Iterar gradualmente – Desarrollar descomposición complejos paso a paso
- Comprobar resultados -Verifique los resultados importantes con las partes interesadas de los negocios
- Documentar ideas – Respetar consultas y resultados importantes para remisión futura
Conclusión
El servidor MCP de Amazon RedShift transforma la forma en que los analistas de datos interactúan con los grupos de desplazamiento rojo al habilitar la exploración y el descomposición de datos del jerigonza natural a través de herramientas de agente como Kiro y Amazon Q CLI. Al eliminar la indigencia de escribir consultas SQL manualmente y navegar estructuras de bases de datos complejas, los analistas pueden centrarse en crear ideas en extensión de disputar con sintaxis y descubrimiento de esquemas. Si está realizando un descomposición único, generando informes regulares o explorar nuevos conjuntos de datos, el servidor de Amazon RedShift MCP proporciona un poderoso interfacio intuitivo para su descomposición de datos. Esto es lo que debe hacer a continuación:
- Instale el servidor MCP Siguiendo los pasos de configuración en esta publicación
- Explore su entorno de desplazamiento rojo de Amazon Uso de consultas de jerigonza natural
- Comience con descomposición simples y gradualmente construye complejidad
- Compartir ideas con su equipo usando los resúmenes del jerigonza natural
- Proporcionar comentarios Para ayudar a mejorar las capacidades del servidor MCP
Consulte estas publicaciones de blog para ayudarlo a navegar usando un jerigonza natural con sus casos de uso:
Sobre los autores