
Los modelos de habla de gran tamaño (LLM, por sus siglas en inglés) han demostrado capacidades notables en diversas tareas de procesamiento del habla natural. Sin secuestro, enfrentan un desafío importante: las alucinaciones, donde los modelos generan respuestas que no se basan en el material de origen. Este problema socava la confiabilidad de los LLM y hace que la detección de alucinaciones sea un campo de acción crítica de investigación. Si acertadamente los métodos convencionales como los modelos de clasificación y ranking han sido efectivos, a menudo carecen de interpretabilidad, lo cual es crucial para la confianza del legatario y las estrategias de mitigación. La apadrinamiento generalizada de los LLM ha llevado a los investigadores a explorar el uso de estos mismos modelos para la detección de alucinaciones. Sin secuestro, este enfoque presenta nuevos desafíos, particularmente en relación con la latencia, oportuno al enorme tamaño de los LLM y la sobrecarga computacional requerida para procesar textos fuente largos. Esto crea un obstáculo significativo para las aplicaciones en tiempo vivo que requieren tiempos de respuesta rápidos.
Los investigadores de Microsoft Responsible AI presentan un flujo de trabajo sólido para invadir los desafíos de la detección de alucinaciones en los LLM. Este enfoque tiene como objetivo equilibrar la latencia y la interpretabilidad mediante la combinación de un maniquí de clasificación pequeño, específicamente un maniquí de habla pequeño (SLM), con un módulo LLM posterior llamado «razonador restringido». El SLM realiza la detección auténtico de alucinaciones, mientras que el módulo LLM explica las alucinaciones detectadas. Este método aprovecha la ocurrencia relativamente infrecuente de alucinaciones en el uso práctico, lo que hace que el costo de tiempo promedio de usar LLM para razonar sobre textos alucinados sea manejable. Adicionalmente, el enfoque capitaliza las capacidades de razonamiento y explicación preexistentes de los LLM, eliminando la aprieto de datos extensos específicos del dominio y el costo computacional significativo asociado con el ajuste fino.
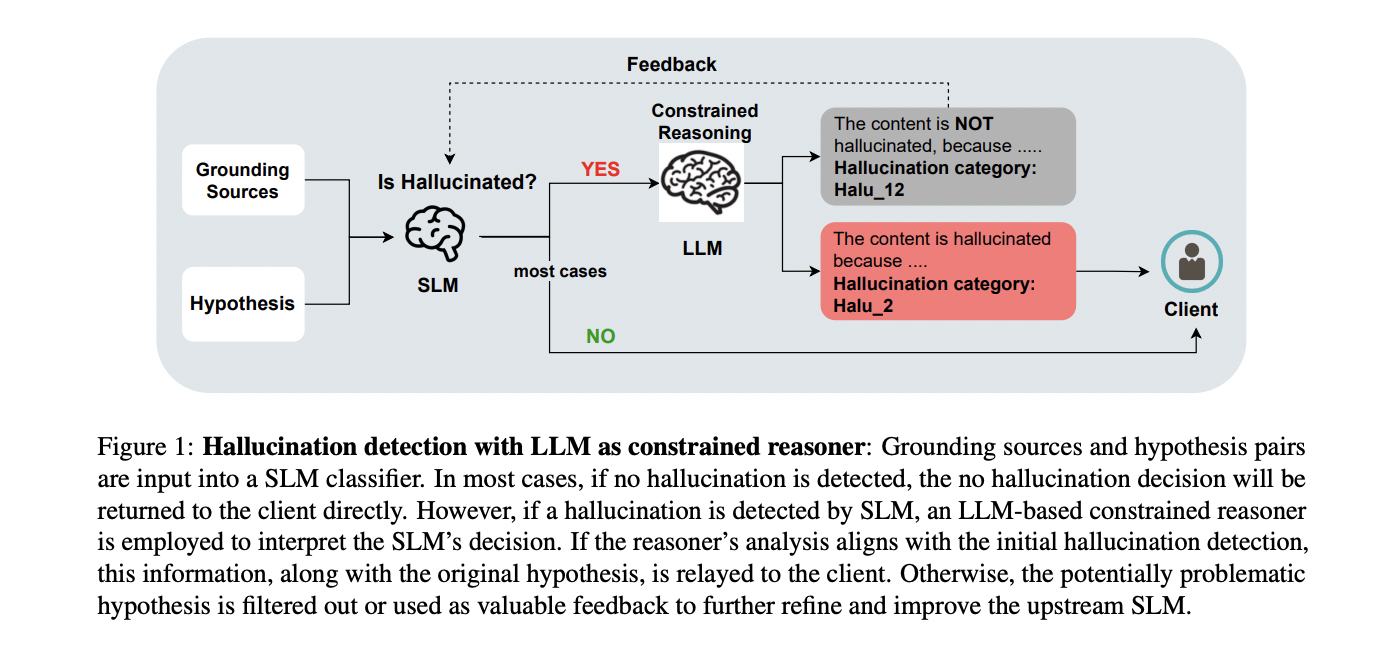
Este situación mitiga un problema potencial en la combinación de SLM y LLM: la inconsistencia entre las decisiones de SLM y las explicaciones de LLM. Este problema es particularmente relevante en la detección de alucinaciones, donde la afiliación entre detección y explicación es crucial. El estudio se centra en resolver este problema en el interior del situación de detección de alucinaciones de dos etapas. Adicionalmente, los investigadores analizan los razonamientos de LLM sobre las decisiones de SLM y las etiquetas de verdad fundamental, explorando el potencial de LLM como mecanismos de feedback para mejorar los procesos de detección. El estudio hace dos contribuciones principales: presenta un razonador restringido para la detección de alucinaciones que equilibra la latencia y la interpretabilidad y proporciona un investigación integral de la coherencia subido y descendente, adyacente con soluciones prácticas para mejorar la afiliación entre la detección y la explicación. La efectividad de este enfoque se demuestra en múltiples conjuntos de datos de código extenso.
El situación propuesto aborda los desafíos duales de latencia e interpretabilidad en la detección de alucinaciones para LLM. Consta de dos componentes principales: un SLM para la detección auténtico y un razonador restringido basado en un LLM para la explicación.
El SLM funciona como un clasificador ligero y valioso, capacitado para identificar posibles alucinaciones en el texto. Este paso auténtico permite una rápida selección de la información de entrada, lo que reduce significativamente la carga computacional del sistema. Cuando el SLM identifica un fragmento de texto como potencialmente sorprendente, activa la segunda etapa del proceso.
El razonador restringido, impulsado por un LLM, se encarga entonces de proporcionar una explicación detallada de la fantasía detectada. Este componente aprovecha las capacidades avanzadas de razonamiento del LLM para analizar el texto afectado en contexto, ofreciendo información sobre por qué se identificó como una fantasía. El razonador está «restringido» en el sentido de que se centra solamente en explicar la audacia del SLM, en ocupación de realizar un investigación extenso.
Para invadir las posibles inconsistencias entre las decisiones del SLM y las explicaciones del LLM, el situación incorpora mecanismos para mejorar la afiliación. Esto incluye una ingeniería rápida y cuidadosa para el LLM y posibles ciclos de feedback donde las explicaciones del LLM se pueden utilizar para refinar los criterios de detección del SLM con el tiempo.
La configuración positivo del situación de detección de alucinaciones propuesto está diseñada para estudiar la consistencia del razonamiento y explorar enfoques efectivos para filtrar inconsistencias. Los investigadores utilizan GPT4-turbo como el razonador restringido (R) para explicar las determinaciones de alucinaciones con configuraciones específicas de temperatura y top-p. Los experimentos se llevan a lengua en cuatro conjuntos de datos: NHNET, FEVER, HaluQA y HaluSum, y se aplica un muestreo para tener la llave de la despensa los tamaños de los conjuntos de datos y las limitaciones de bienes.
Para aparentar un clasificador SLM imperfecto, los investigadores toman muestras de respuestas alucinadas y no alucinadas de los conjuntos de datos, asumiendo que la rótulo inicial es una fantasía. Esto crea una mezcla de casos verdaderos positivos y falsos positivos para el investigación.
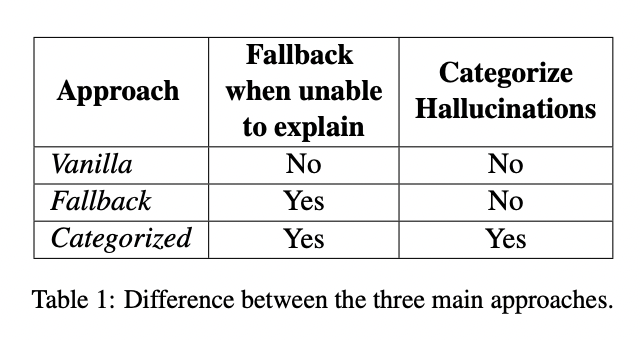
La metodología se centra en tres enfoques principales:
1. Vanilla: un enfoque de remisión donde R simplemente explica por qué el texto fue detectado como una fantasía sin invadir las inconsistencias.
2. Fallback: introduce una bandera “DESCONOCIDO” para indicar cuando R no puede proporcionar una explicación adecuada, señalando posibles inconsistencias.
3. Categorizado: refina el mecanismo de señalización incorporando categorías de alucinaciones granulares, incluida una categoría específica (hallu12) para señalar inconsistencias donde el texto no es una fantasía.
Se comparan estos enfoques para evaluar su efectividad en el manejo de inconsistencias entre las decisiones SLM y las explicaciones LLM para mejorar la confiabilidad genérico y la interpretabilidad del situación de detección de alucinaciones.
Los resultados experimentales demuestran la efectividad del situación de detección de alucinaciones propuesto, en particular el enfoque categorizado. Al identificar inconsistencias entre las decisiones de SLM y las explicaciones de LLM, el enfoque categorizado logró un desempeño casi valentísimo en todos los conjuntos de datos, con puntuaciones de precisión, recuperación y F1 consistentemente superiores a 0,998 en muchos conjuntos de datos.
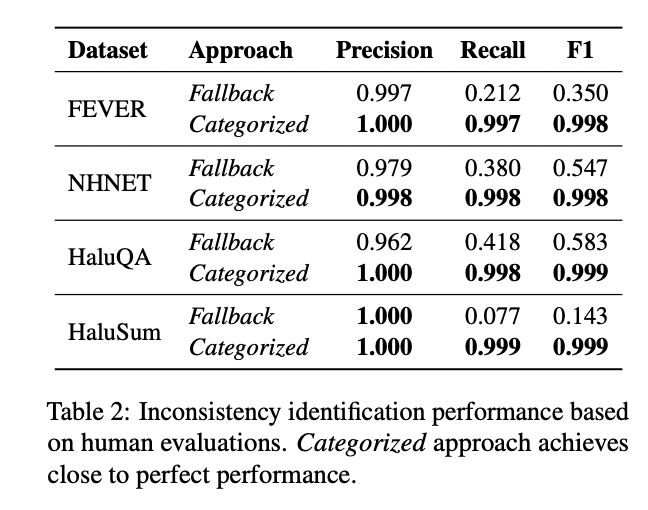
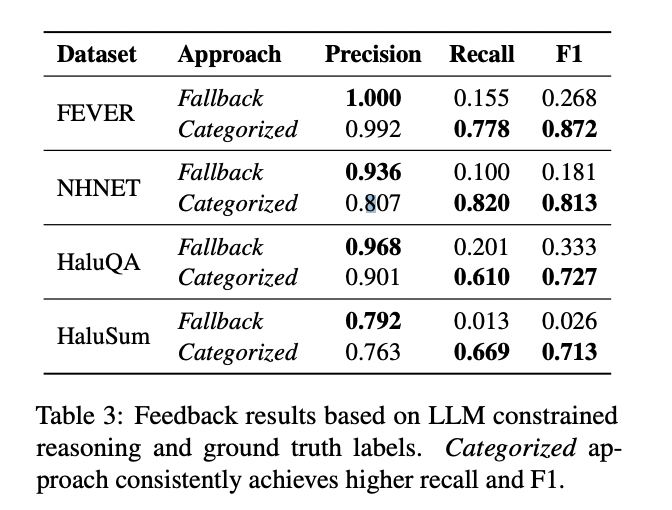
En comparación con el método de respaldo, que mostró una incorporación precisión pero una recuperación deficiente, el método categorizado se destacó en ambas métricas. Este desempeño superior se tradujo en un filtrado de inconsistencias más efectivo. Si acertadamente el método tradicional mostró tasas de inconsistencias altas y el método de respaldo mostró una mejoría limitada, el método categorizado redujo drásticamente las inconsistencias a un pequeño de 0,1-1 % en todos los conjuntos de datos a posteriori del filtrado.
El método categorizado igualmente demostró un gran potencial como mecanismo de feedback para mejorar el SLM en la período auténtico. Superó sistemáticamente al método de respaldo en la identificación de falsos positivos, logrando una puntuación F1 macropromedio de 0,781. Esto indica su capacidad para evaluar con precisión las decisiones del SLM en relación con la sinceridad del dominio, lo que lo convierte en una utensilio prometedora para refinar el proceso de detección.
Estos resultados resaltan la capacidad del enfoque categorizado para mejorar la consistencia entre la detección y la explicación en el situación de detección de alucinaciones, al tiempo que proporciona feedback valiosa para la mejoría del sistema.
Este estudio presenta un situación práctico para la detección valioso e interpretable de alucinaciones mediante la integración de un SLM para la detección con un LLM para el razonamiento restringido. La organización de filtrado y de incitación categorizada propuesta por los investigadores alinea de modo efectiva las explicaciones del LLM con las decisiones del SLM, demostrando un éxito empírico en cuatro conjuntos de datos de alucinaciones y consistencia factual. Adicionalmente, este enfoque tiene potencial como mecanismo de feedback para refinar los SLM, allanando el camino para sistemas más robustos y adaptativos. Los hallazgos ofrecen implicaciones más amplias para mejorar los sistemas de clasificación y mejorar los SLM a través de la interpretación restringida impulsada por el LLM.
Echa un vistazo a la Papel. Todo el crédito por esta investigación corresponde a los investigadores de este tesina. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de Telegram y LinkedIn Gr¡Hacia lo alto!. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro Subreddit con más de 50 000 millones de usuarios
A continuación se muestra un seminario web muy recomendado por nuestro patrocinador: ‘Expansión de aplicaciones de IA de detención rendimiento con NVIDIA NIM y Haystack’
Asjad es asesor en prácticas en Marktechpost. Está cursando la carrera en ingeniería mecánica en el Instituto Indio de Tecnología de Kharagpur. Asjad es un entusiasta del formación instintivo y del formación profundo que siempre está investigando las aplicaciones del formación instintivo en el ámbito de la atención médica.