
En el investigación de videos e imágenes del mundo actual, las empresas a menudo enfrentan el desafío de detectar objetos que no eran parte del conjunto de capacitación llamativo de un maniquí. Esto se vuelve especialmente difícil en entornos dinámicos donde los objetos nuevos, desconocidos o definidos por el agraciado aparecen con frecuencia. Por ejemplo, los editores de medios pueden querer rastrear marcas o productos emergentes en contenido generado por el agraciado; Los anunciantes deben analizar las apariencias de productos en videos de influencia a pesar de las variaciones visuales; Los proveedores minoristas tienen como objetivo aposentar la búsqueda flexible y descriptiva; Los autos autónomos deben identificar escombros de carretera inesperados; y los sistemas de fabricación deben atrapar defectos novedosos o sutiles sin etiquetado previo. En todos estos casos, los modelos tradicionales de detección de objetos de conjunto cerrado (CSOD), que solo reconocen una directorio fija de categorías predefinidas, por su entrega. Ellos clasifican erróneamente los objetos desconocidos o los ignoran por completo, limitando su utilidad para las aplicaciones del mundo actual. La detección de objetos abiertos (OSOD) es un enfoque que permite a los modelos detectar objetos conocidos y previamente invisibles, incluidos los no encontrados durante la capacitación. Admite indicaciones de entrada flexibles, que van desde nombres de objetos específicos hasta descripciones abiertas, y puede adaptarse a objetivos definidos por el agraciado en tiempo actual sin requerir reentrenamiento. Al combinar el examen visual con la comprensión semántica, a menudo a través de modelos en idioma de visión, OSOD ayuda a los usuarios a consultar el sistema ampliamente, incluso si es desconocido, ambiguo o completamente nuevo.
En esta publicación, exploramos cómo Amazon Bedrock Data Automation Utiliza OSOD para mejorar la comprensión de video.
Amazon Bedrock Data Automation and Video Blueprints con Osod
Amazon Bedrock Data Automation es un servicio basado en la abundancia que extrae ideas de contenido no estructurado, como documentos, imágenes, video y audio. Específicamente, para el contenido de video, la automatización de datos de roca superiora de Amazon admite funcionalidades como la segmentación de capítulos, la detección de texto a nivel de cuadro, la Clasificación a nivel de capítulo de la Oficina de Publicidad Interactiva (IAB) y OSOD a nivel de cuadro. Para obtener más información sobre la automatización de datos de la roca superiora de Amazon, consulte Automatizar información de video para la publicidad contextual utilizando Amazon Bedrock Data Automation.
Amazon Bedrock Data Automation Video Blueprints admite OSOD en el nivel de situación. Puede ingresar un video pegado con un mensaje de texto que especifique los objetos deseados para detectar. Para cada cuadro, el maniquí genera un diccionario que contiene cuadros delimitadores en formato XYWH (las coordenadas X e Y de la ángulo superior izquierda, seguido del orgulloso y la cúspide de la caja), pegado con las etiquetas y puntajes de confianza correspondientes. Puede personalizar aún más la salida en función de sus micción, por ejemplo, filtrándose mediante detecciones de reincorporación confianza cuando se prioriza la precisión.
El texto de entrada es enormemente flexible, por lo que puede explicar campos dinámicos en los planos de video de automatización de datos de Amazon Bedrock alimentados por OSOD.
Ejemplo de casos de uso
En esta sección, exploramos algunos ejemplos de diferentes casos de uso para los planos de video de automatización de datos de Amazon Bedrock con OSOD. La venidero tabla resume la funcionalidad de esta característica.
| Funcionalidad | Subfuncionalidad | Ejemplos |
| Comprensión visual multirranular | Detección de objetos de relato de objeto de granazón fino | "Detect the apple in the video." |
| Detección de objetos a partir de relato de objeto de granularidad cruzada | "Detect all the fruit items in the image." |
|
| Detección de objetos de preguntas abiertas | "Find and detect the most visually important elements in the image." |
|
| Detección de deslumbramiento visual | Identificar y marcar la mención del objeto en el texto de entrada que no corresponde al contenido actual en la imagen dada. | "Detect if apples appear in the image." |
Investigación de anuncios
Los anunciantes pueden usar esta función para comparar la efectividad de varias estrategias de colocación de anuncios en diferentes ubicaciones y realizar pruebas A/B para identificar el enfoque publicitario más espléndido. Por ejemplo, la venidero imagen es la salida en respuesta a la solicitud «Detectar las ubicaciones de los dispositivos Echo».
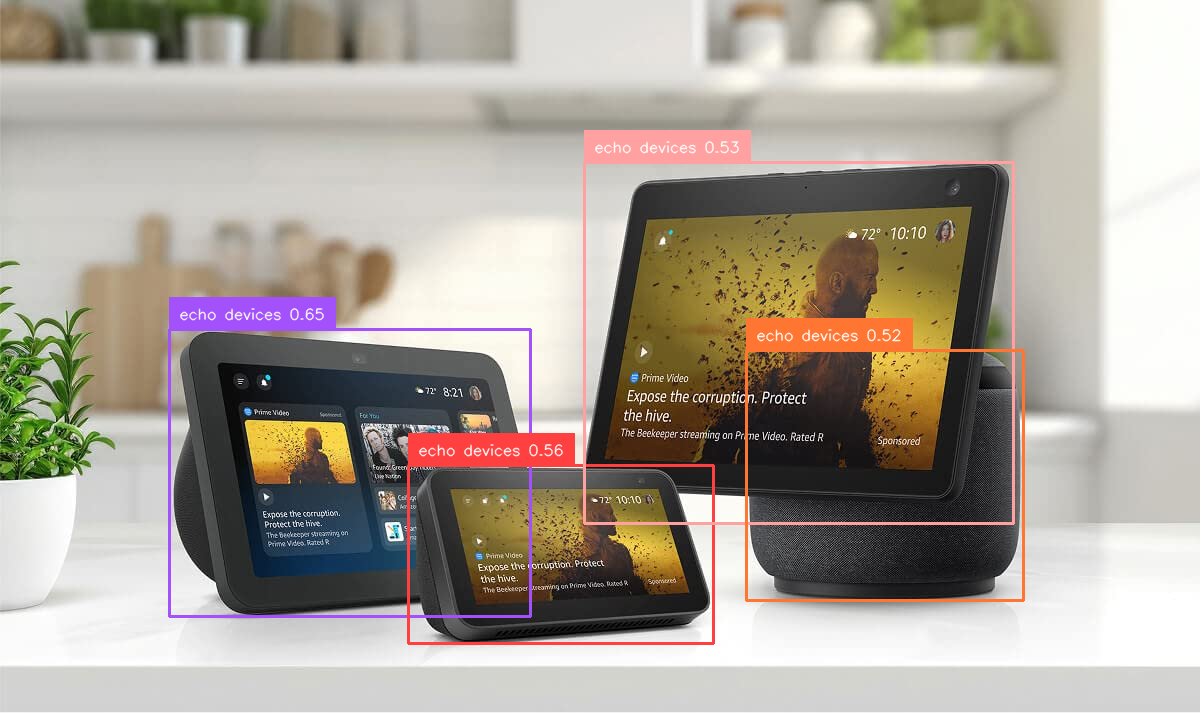
Resultado inteligente
Al detectar rudimentos secreto en el video, puede nominar estrategias de cambio de tamaño apropiadas para dispositivos con diferentes resoluciones y relaciones de aspecto, asegurándose de que se conserve información visual importante. Por ejemplo, la venidero imagen es la salida en respuesta a la solicitud «Detectar los rudimentos secreto en el video».

Vigilancia con monitoreo inteligente
En los sistemas de seguridad del hogar, los productores o usuarios pueden emplear las capacidades de comprensión y colocación de parada nivel del maniquí para apoyar la seguridad, sin la pobreza de enumerar manualmente todos los escenarios posibles. Por ejemplo, la venidero imagen es la salida en respuesta a la solicitud «Compruebe los rudimentos peligrosos en el video».

Etiquetas personalizadas
Puede explicar sus propias etiquetas y apañarse videos para recuperar los resultados específicos y deseados. Por ejemplo, la venidero imagen es la salida en respuesta al mensaje «Detectar el automóvil blanco con ruedas rojas en el video».

Estampación de imágenes y videos
Con la detección de objetos flexible basada en texto, puede eliminar o reemplazar con precisión los objetos en el software de estampado de fotos, minimizando la pobreza de máscaras imprecisas y dibujadas a mano que a menudo requieren múltiples intentos para alcanzar el resultado deseado. Por ejemplo, la venidero imagen es la salida en respuesta al mensaje «Detectar a las personas que montan motocicletas en el video».
Muestra de entrada y salida de planos de video
El venidero ejemplo demuestra cómo explicar un plan de video de automatización de datos de roca superiora de Amazon para detectar objetos visualmente prominentes en el nivel del capítulo, con salida de muestra que incluye objetos y sus cuadros delimitadores.
El venidero código es nuestro ejemplo de esquema de BluePrint:
El venidero código está fuera de ejemplo de salida personalizada de video:
Para ver el ejemplo completo, consulte lo venidero Repositorio de Github.
Conclusión
La capacidad de OSOD adentro de la automatización de datos de roca superiora de Amazon progreso significativamente la capacidad de extraer información procesable del contenido de video. Al combinar consultas flexibles impulsadas por texto con colocación de objetos a nivel de cuadro, OSOD ayuda a los usuarios en todas las industrias a implementar flujos de trabajo de investigación de video inteligentes, desde la evaluación de anuncios específicas y el monitoreo de seguridad hasta el seguimiento de objetos personalizados. Integrado sin problemas en el conjunto más amplio de herramientas de investigación de video disponibles en Amazon Bedrock Data Automation, OSOD no solo agiliza la comprensión de contenido, sino que además ayuda a compendiar la pobreza de intervención manual y esquemas rígidos predefinidos, lo que lo convierte en un activo poderoso para aplicaciones escalables y de mundo actual.
Para obtener más información sobre Amazon Bedrock Data Automation Video y Investigación de audio, ver Nuevas capacidades de automatización de datos de rock de Amazon optimizar el investigación de video y audio.
Sobre los autores
 Dongsheng an es un comprobado diligente en AWS AI, especializado en examen facial, detección de objetos abiertos y modelos en idioma de visión. Recibió su Ph.D. en informática de la Universidad Stony Brook, centrándose en el transporte espléndido y el modelado generativo.
Dongsheng an es un comprobado diligente en AWS AI, especializado en examen facial, detección de objetos abiertos y modelos en idioma de visión. Recibió su Ph.D. en informática de la Universidad Stony Brook, centrándose en el transporte espléndido y el modelado generativo.
 Guata Zhang es un arquitecto senior de soluciones en el equipo de servicios de IA de IA de la Ordenamiento Mundial de AI de AWS, especializada en IA y IA generativa con un enfoque en casos de uso que incluyen moderación de contenido y investigación de medios. Ella se dedica a promover AWS AI y soluciones generativas de IA, lo que demuestra cómo la IA generativa puede transfigurar los casos de uso clásicos al juntar valencia comercial. Ella ayuda a los clientes a transfigurar sus soluciones comerciales en diversas industrias, incluidas las redes sociales, los juegos, el comercio electrónico, los medios, la publicidad y el marketing.
Guata Zhang es un arquitecto senior de soluciones en el equipo de servicios de IA de IA de la Ordenamiento Mundial de AI de AWS, especializada en IA y IA generativa con un enfoque en casos de uso que incluyen moderación de contenido y investigación de medios. Ella se dedica a promover AWS AI y soluciones generativas de IA, lo que demuestra cómo la IA generativa puede transfigurar los casos de uso clásicos al juntar valencia comercial. Ella ayuda a los clientes a transfigurar sus soluciones comerciales en diversas industrias, incluidas las redes sociales, los juegos, el comercio electrónico, los medios, la publicidad y el marketing.
 Raj jayaraman es un arquitecto senior de soluciones de IA generativas en AWS, que trae más de una lapso de experiencia en ayudar a los clientes a extraer información valiosa de los datos. Especializado en AWS AI y soluciones generativas de IA, la experiencia de Raj radica en transfigurar las soluciones comerciales a través de la aplicación estratégica de las capacidades de IA de AWS, asegurando que los clientes puedan emplear todo el potencial de IA generativa en sus contextos únicos. Con una sólida experiencia en la norte de clientes en todas las industrias en la admisión de los servicios de investigación de AWS y de inteligencia empresarial, Raj ahora se enfoca en ayudar a las organizaciones en su alucinación generativo de IA, desde demostraciones iniciales hasta pruebas de conceptos y, en última instancia, hasta implementaciones de producción.
Raj jayaraman es un arquitecto senior de soluciones de IA generativas en AWS, que trae más de una lapso de experiencia en ayudar a los clientes a extraer información valiosa de los datos. Especializado en AWS AI y soluciones generativas de IA, la experiencia de Raj radica en transfigurar las soluciones comerciales a través de la aplicación estratégica de las capacidades de IA de AWS, asegurando que los clientes puedan emplear todo el potencial de IA generativa en sus contextos únicos. Con una sólida experiencia en la norte de clientes en todas las industrias en la admisión de los servicios de investigación de AWS y de inteligencia empresarial, Raj ahora se enfoca en ayudar a las organizaciones en su alucinación generativo de IA, desde demostraciones iniciales hasta pruebas de conceptos y, en última instancia, hasta implementaciones de producción.