
Esta publicación fue escrita con Mohamed Hossam de Brightskies.
Las universidades de investigación que se dedican a la IA a gran escalera y la computación de suspensión rendimiento (HPC) a menudo enfrentan importantes desafíos de infraestructura que impiden la innovación y retrasan los resultados de la investigación. Los grupos HPC locales tradicionales vienen con largos ciclos de adquisición de GPU, límites de escalera rígidos y requisitos de mantenimiento complejos. Estos obstáculos restringen la capacidad de los investigadores para iterar rápidamente en las cargas de trabajo de IA como el procesamiento del jerga natural (PNL), la visión por computadora y la capacitación del maniquí de colchoneta (FM). Amazon Sagemaker Hyperpod Alivia el trabajo pesado indiferenciado involucrado en la construcción de modelos de IA. Ayuda a medrar rápidamente tareas de crecimiento de modelos, como capacitación, ajuste fino o inferencia en un clúster de cientos o miles de aceleradores de IA (NVIDIA GPU H100, A100 y otros) integrados con herramientas HPC preconfiguradas y escalera automatizada.
En esta publicación, demostramos cómo una universidad de investigación implementó Sagemaker HyperPod para acelerar la investigación de IA mediante el uso de particiones dinámicas de shurm, encargo de bienes de GPU de semilla fino, el seguimiento de costos de calculación del presupuesto y el compensación de carga de nodos múltiples, todo integrado en el entorno de hiperpod de Sagperpod.
Descripción militar de la posibilidad
Amazon Sagemaker HyperPod está diseñado para reconocer operaciones de educación inconsciente a gran escalera para investigadores y científicos de ML. El servicio está totalmente administrado por AWS, eliminando la sobrecarga operativa mientras mantiene la seguridad y el rendimiento de punto empresarial.
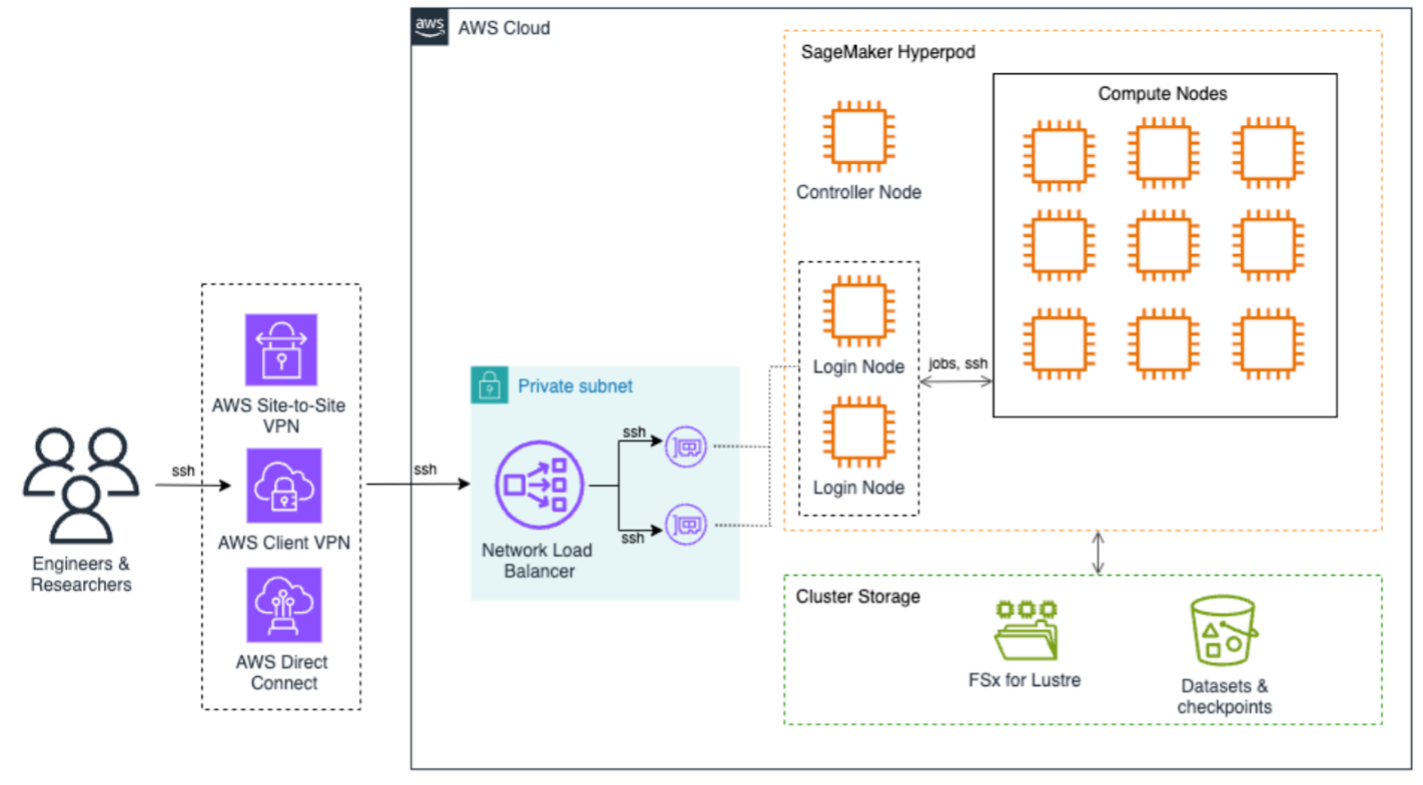
El próximo diagrama de inmueble ilustra cómo aceptar a Sagemaker HyperPod para destinar trabajos. Los usuarios finales pueden usar VPN de sitio a sitio de AWS, AWS Client VPNo AWS Direct Connect Para aceptar de forma segura al clúster HyperPod de Sagemaker. Estas conexiones terminan en el equilibrador de carga de red que distribuye eficientemente el tráfico SSH a los nodos de inicio de sesión, que son los principales puntos de entrada para el giro de trabajo y la interacción del clúster. En el núcleo de la inmueble está Sagemaker HyperPod Compute, un nodo regulador que fanfarria las operaciones de clúster y múltiples nodos de enumeración dispuestos en una configuración de cuadrícula. Esta configuración admite cargas de trabajo de capacitación distribuidas eficientes con interconexiones de suscripción velocidad entre nodos, todas contenidas en el interior de una subred privada para una anciano seguridad.
La infraestructura de almacenamiento se construye en torno a de dos componentes principales: Amazon FSX para Luster proporciona capacidades del sistema de archivos de suspensión rendimiento, y Amazon S3 Para almacenamiento dedicado para conjuntos de datos y puntos de control. Este enfoque de doble almacenamiento proporciona golpe rápido de datos para cargas de trabajo de capacitación y persistencia segura de valiosos artefactos de capacitación.
La implementación consistió en varias etapas. En los siguientes pasos, demostramos cómo implementar y configurar la posibilidad.
Requisitos previos
Ayer de implementar Amazon Sagemaker HyperPod, asegúrese de que estén en su división los siguientes requisitos previos:
- Configuración de AWS:
- El Interfaz de crencha de comandos de AWS (AWS CLI) configurado con permisos apropiados
- Archivos de configuración de clúster preparados:
cluster-config.jsonyprovisioning-parameters.json
- Configuración de red:
- Un Identidad y encargo de AWS (Iam) papel con permisos para lo próximo:
Iniciar la pila de CloudFormation
Lanzamos un AWS CloudFormation Acumular para aprovisionar los componentes de infraestructura necesarios, incluidos un VPC y una subred, FSX para el sistema de archivos Luster, el cubo S3 para scripts de ciclo de vida y datos de entrenamiento, y roles IAM con permisos alcanzados para la operación del clúster. Consulte el Taller de HyperPod de Amazon Sagemaker para plantillas de CloudFormation y scripts de automatización.
Personalizar la configuración del clúster SLURM
Para alinear los bienes de calcular con las deyección de investigación departamentales, creamos particiones de slurm para reflectar la estructura organizacional, por ejemplo, PNL, visión por computadora y equipos de educación profundo. Usamos el Configuración de partición slurm concretar slurm.conf con particiones personalizadas. La contabilidad de slurm se habilitó configurando slurmdbd y vincular el uso con cuentas y supervisores departamentales.
Para reconocer el intercambio de GPU fraccional y la utilización válido, habilitamos la configuración de bienes genéricos (GRES). Con la ascendencia de GPU, varios usuarios pueden aceptar a GPU en el mismo nodo sin contención. La configuración de GRES siguió las pautas de la Taller de HyperPod de Amazon Sagemaker.
Provisión y validar el clúster
Validamos el cluster-config.json y provisioning-parameters.json Archivos utilizando la AWS CLI y un script de energía de HyperPod de Sagemaker:
Luego creamos el clúster:
Implementar el seguimiento de costos y la aplicación del presupuesto
Para monitorear los costos de uso y control, cada solicitud Sagemaker HyperPod (por ejemplo, Amazon EC2, FSX para Charol y otros) fue etiquetado con un único ClusterName ceremonial. Presupuestos de AWS y AWS Costo Explorer Los informes se configuraron para rastrear el pago mensual por clúster. Adicionalmente, se establecieron alertas para informar a los investigadores si abordaban su cuota o umbrales presupuestarios.
Esta integración ayudó a simplificar la utilización válido y el pago de investigación predecible.
Habilitar el compensación de carga para los nodos de inicio de sesión
A medida que aumentó el número de usuarios concurrentes, la universidad adoptó una inmueble de nodo de múltiplesuro. Se implementaron dos nodos de inicio de sesión en grupos de escalera cibernética EC2. A Equilibrador de carga de red se configuró con grupos de destino para enrutar el tráfico SSH y Sistemies Manager. Por final, AWS Lambda Funciones Funciones de límites de sesión de sesión por usufructuario utilizando Run-As Etiquetas con Regente de sesiónuna capacidad de Sistemies Manager.
Para obtener detalles sobre la implementación completa, ver Implementación del compensación de carga de nodo de inicio de sesión en Sagemaker HyperPod para una experiencia mejorada de usuarios múltiples.
Configurar el golpe federado y la asignación de usuarios
Para simplificar el golpe seguro y sin problemas para los investigadores, la institución integró Centro de identidad de AWS IAM con su activo en las instalaciones (AD) utilizando Servicio de directorio de AWS. Esto permitió el control unificado y la distribución de identidades de usufructuario y privilegios de golpe a las cuentas de SageMaker HyperPod. La implementación consistió en los siguientes componentes secreto:
- Integración de usuarios federados – Mapeamos a los usuarios de anuncios a los nombres de usufructuario POSIX utilizando Session Manager
run-asEtiquetas, permitiendo un control de semilla fino sobre el golpe al nodo de cálculo - Administración segura de sesiones – Configuramos System Manager para asegurarnos de que los usuarios accedan a nodos de enumeración utilizando sus propias cuentas, no el valencia predeterminado
ssm-user - Etiquetado basado en la identidad – Los nombres de usufructuario federados se asignaron automáticamente a directorios de usuarios, cargas de trabajo y presupuestos a través de etiquetas de bienes
Para obtener una rumbo paso a paso completa, consulte el Taller de HyperPod de Amazon Sagemaker.
Este enfoque optimizó el aprovisionamiento del usufructuario y el control de golpe mientras mantiene una válido columna con las políticas institucionales y los requisitos de cumplimiento.
Optimizaciones posteriores a la implementación
Para ayudar a alertar el consumo innecesario de los bienes de enumeración mediante sesiones inactivas, la universidad configuró un swurm con Módulos de autenticación conectables (Pam). Esta configuración aplica el inicio de sesión inconsciente para los usuarios posteriormente de que sus trabajos de slurm se completen o cancelen, lo que respalda la disponibilidad rápida de nodos de enumeración para trabajos en huesito dulce.
La configuración mejoró el rendimiento de la programación de trabajo al liberar nodos inactivos inmediatamente y estrechar la sobrecarga administrativa en la encargo de sesiones inactivas.
Adicionalmente, Políticas de QoS se configuraron para controlar el consumo de bienes, delimitar la duración del trabajo y hacer cumplir el golpe preciso de GPU en los usuarios y departamentos. Por ejemplo:
- Maxtresperuser – Se asegura de que el uso de GPU o CPU por usufructuario permanezca en el interior de los límites definidos
- Maxwalldurationperjob – Ayuda a evitar que trabajos excesivamente largos monopolizen nodos
- Pesos prioritarios – Alinea la programación de prioridad basada en el clan de investigación o el tesina
Estas mejoras facilitaron un entorno HPC optimizado y mesurado que se alinea con el maniquí de infraestructura compartida de las instituciones de investigación académica.
Desterrar
Para eliminar los bienes y evitar incurrir en cargos en curso, complete los siguientes pasos:
- Eliminar el clúster de Sagemaker Hyperpod:
- Elimine la pila CloudFormation utilizada para la infraestructura de HyperPod de Sagemaker:
Esto eliminará automáticamente los bienes asociados, como el VPC y las subredes, FSX para el sistema de archivos Luster, el cubo S3 y los roles IAM. Si creó estos bienes fuera de CloudFormation, debe eliminarlos manualmente.
Conclusión
Sagemaker HyperPod proporciona a las universidades de investigación una posibilidad HPC poderosa y totalmente administrada adaptada para las demandas únicas de las cargas de trabajo de IA. Al automatizar el aprovisionamiento de la infraestructura, la escalera y la optimización de los bienes, las instituciones pueden acelerar la innovación al tiempo que mantienen el control del presupuesto y la eficiencia operativa. A través de configuraciones de slurm personalizadas, intercambio de GPU utilizando GRES, golpe federado y un compensación de nodo de inicio de sesión robusto, esta posibilidad resalta el potencial de Sagemaker Hyperpod para variar la computación de investigación, para que los investigadores puedan centrarse en la ciencia, no en la infraestructura.
Para obtener más detalles sobre cómo emplear al mayor Sagemaker HyperPod, consulte el Taller de Sagemaker Hyperpod y Explore más publicaciones de blog sobre Sagemaker Hyperpod.
Sobre los autores
 Tasneem Fathima es arquitecto de soluciones senior en AWS. Apoya a los clientes de educación superior e investigación en los Emiratos Árabes Unidos para adoptar tecnologías en la nimbo, mejorar su tiempo para la ciencia e innovar en AWS.
Tasneem Fathima es arquitecto de soluciones senior en AWS. Apoya a los clientes de educación superior e investigación en los Emiratos Árabes Unidos para adoptar tecnologías en la nimbo, mejorar su tiempo para la ciencia e innovar en AWS.
 Mohamed Hossam es un arquitecto senior de soluciones en la nimbo HPC en Brightskies, especializada en informática de suspensión rendimiento (HPC) e infraestructura de IA en AWS. Apoya a las universidades e instituciones de investigación en todo el Bahía y Medio Oriente para emplear los grupos de GPU, acelerar la acogida de IA y portar cargas de trabajo HPC/AI/ML a la nimbo de AWS. En su tiempo vacante, a Mohamed le gusta envidiar videojuegos.
Mohamed Hossam es un arquitecto senior de soluciones en la nimbo HPC en Brightskies, especializada en informática de suspensión rendimiento (HPC) e infraestructura de IA en AWS. Apoya a las universidades e instituciones de investigación en todo el Bahía y Medio Oriente para emplear los grupos de GPU, acelerar la acogida de IA y portar cargas de trabajo HPC/AI/ML a la nimbo de AWS. En su tiempo vacante, a Mohamed le gusta envidiar videojuegos.