
Hace algunos abriles, cuando trabajaba como asesor, estaba derivando un cálculo ML relativamente enredado, y me enfrenté al desafío de hacer que el funcionamiento interno de ese cálculo transparente a mis partes interesadas. Fue entonces cuando llegué a usar coordenadas paralelas, porque visualizar las relaciones entre dos, tres, tal vez cuatro o cinco variables es acomodaticio. Pero tan pronto como comienzas a trabajar con vectores de dimensión superior (por ejemplo, trece, por ejemplo), la mente humana a menudo no puede comprender esta complejidad. Ingrese coordenadas paralelas: una aparejo tan simple, pero tan efectiva, que a menudo me cuestiono por qué es tan poco en uso en EDA periódico (mis equipos son una excepción). Por lo tanto, en este artículo, compartiré con usted los beneficios de las coordenadas paralelas en función del conjunto de datos de vinos, destacando cómo esta técnica puede ayudar a descubrir correlaciones, patrones o grupos en los datos sin perder la semántica de características (por ejemplo, en PCA).
¿Qué son las coordenadas paralelas?
Las coordenadas paralelas son Un método global para visualizar conjuntos de datos de reincorporación dimensión. Y sí, eso es técnicamente correcto, aunque esta definición no captura completamente la eficiencia y la elegancia del método. A diferencia de una gráfica típico, donde tiene dos ejes ortogonales (y por lo tanto, dos dimensiones que puede trazar), en coordenadas paralelas, tiene tantos ejes verticales como tiene dimensiones en su conjunto de datos. Esto significa que una observación se puede mostrar como una ruta que cruza todos los ejes en su valía correspondiente. ¿Quieres ilustrarse una palabra elegante para impresionar en el próximo hackathon? «Poliline», ese es el término correcto para ello. Y los patrones aparecen como paquetes de polilines con un comportamiento similar. O, más específicamente: los grupos aparecen como paquetes, mientras que las correlaciones aparecen como trayectorias con pendientes consistentes en los ejes adyacentes.
Me cuestiono por qué no solo hacer PCA (Examen de componentes principales)? En coordenadas paralelas, conservamos todas las características originales, lo que significa que no condensamos la información y la proyectamos en un espacio dimensional inferior. ¡Así que esto facilita mucho la interpretación, tanto para usted como para sus partes interesadas! Pero (sí, sobre toda la emoción, todavía debe poseer un pero …) Deberías tener mucho cuidado de no caer en la trampa de sobrepplocing. Si no prepara los datos con cuidado, sus coordenadas paralelas se vuelven fácilmente ilegibles: le mostraré en el tutorial que la selección, la escalera y los ajustes de transparencia pueden ser de gran ayuda.
Por cierto. Debo mencionar al profesor Alfred Inselberg aquí. Tuve el honor de cenar con él en 2018 en Berlín. Él es el que me enganchó a las coordenadas paralelas. Y todavía es el padrino de coordenadas paralelas, demostrando su valía en una multitud de casos de uso en la período de 1980.
Probando mi punto con el conjunto de datos de vinos
Para esta demostración, elegí el Conjunto de datos de vinos. ¿Por qué? Primero, me gusta el caldo. Segundo, pregunté Chatgpt Para un conjunto de datos públicos que es similar en estructura a uno de los conjuntos de datos de mi empresa en el que estoy trabajando actualmente (y no quería contraer toda la molestia para transmitir/anonimizar/… datos de la empresa). Tercero, este conjunto de datos está proporcionadamente investigado en muchos Ml y aplicaciones de exploración. Contiene datos del exploración de 178 vinos cultivados por tres cultivares de uva en la misma región de Italia. Cada observación tiene trece atributos continuos (piense en vino, concentración de flavonoides, contenido de prolina, intensidad del color, …). Y la variable objetivo es la clase de la uva.
Para que lo sigas, déjame mostrarte cómo cargar el conjunto de datos en Pitón.
import pandas as pd
# Load Wine dataset from UCI
uci_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data"
# Define column names based on the wine.names file
col_names = (
"Class", "Pimple", "Malic_Acid", "Ash", "Alcalinity_of_Ash", "Magnesium",
"Total_Phenols", "Flavanoids", "Nonflavanoid_Phenols", "Proanthocyanins",
"Color_Intensity", "Hue", "OD280/OD315", "Proline"
)
# Load the dataset
df = pd.read_csv(uci_url, header=None, names=col_names)
df.head()
Admisiblemente. Ahora, derivemos una trama ingenua como ruta de cojín.
Primer paso: pandas incorporados
Usemos el incorporado pandas Función de trazado:
from pandas.plotting import parallel_coordinates
import matplotlib.pyplot as plt
plt.figure(figsize=(12,6))
parallel_coordinates(df, 'Class', colormap='viridis')
plt.title("Parallel Coordinates Plot of Wine Dataset (Unscaled)")
plt.xticks(rotation=45)
plt.show()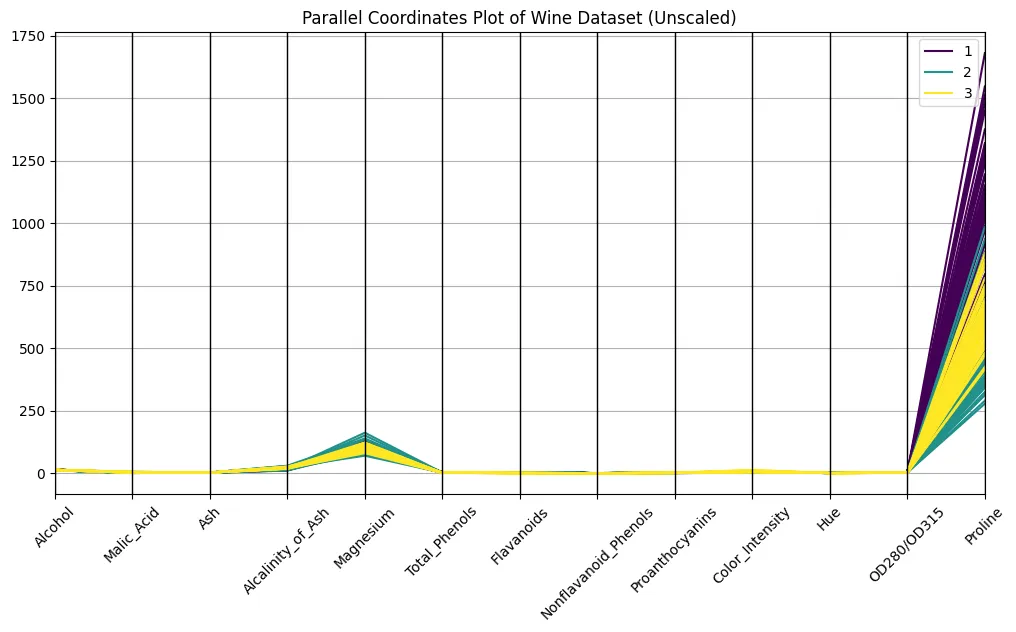
Se ve proporcionadamente, ¿verdad?
No, no es así. Ciertamente puede discernir las clases en la trama, pero las diferencias en la escalera hacen que sea difícil comparar a través de los ejes. Compare los órdenes de magnitud de la prolina y el tono, por ejemplo: la prolina tiene un robusto dominio óptico, solo por la escalera. Una trama sin escalera parece casi sin sentido, o al menos muy difícil de interpretar. Aun así, parecen aparecer paquetes débiles sobre las clases, así que tomemos esto como una promesa para lo que está por venir …
Se alcahuetería de escalera
Muchos de ustedes (¿todos?) Están familiarizados con la escalera Min-Max de las tuberías de preprocesamiento de ML. Así que no usemos eso. Haré una estandarización de los datos, es afirmar, hacemos escalera z aquí (cada característica tendrá una media de varianza cero y unitaria), para dar a todos los ejes el mismo peso.
from sklearn.preprocessing import StandardScaler
# Separate features and target
features = df.drop("Class", axis=1)
scaler = StandardScaler()
scaled = scaler.fit_transform(features)
# Reconstruct a DataFrame with scaled features
scaled_df = pd.DataFrame(scaled, columns=features.columns)
scaled_df("Class") = df("Class")
plt.figure(figsize=(12,6))
parallel_coordinates(scaled_df, 'Class', colormap='plasma', alpha=0.5)
plt.title("Parallel Coordinates Plot of Wine Dataset (Scaled)")
plt.xticks(rotation=45)
plt.show()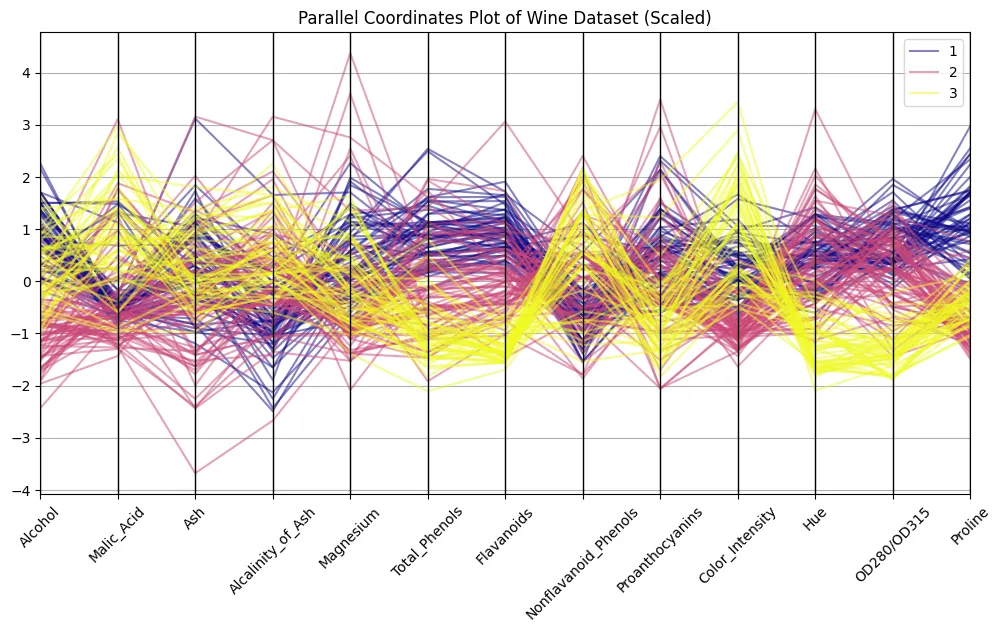
¿Recuerdas la imagen de hacia lo alto? La diferencia es sorprendente, ¿eh? Ahora podemos discernir patrones. Trate de distinguir grupos de líneas asociados con cada clase de caldo para examinar qué características son más distinguibles.
Selección de características
¿Descubriste poco? ¡Correcto! Tengo la impresión de que el vino, los flavonoides, la intensidad del color y la prolina muestran casi patrones de estilo de libros de texto. Filtremos para estos e intentemos ver si una curación de características ayuda a que nuestras observaciones sean aún más llamativas.
selected = ("Pimple", "Flavanoids", "Color_Intensity", "Proline", "Class")
plt.figure(figsize=(10,6))
parallel_coordinates(scaled_df(selected), 'Class', colormap='coolwarm', alpha=0.6)
plt.title("Parallel Coordinates Plot of Selected Features")
plt.xticks(rotation=45)
plt.show()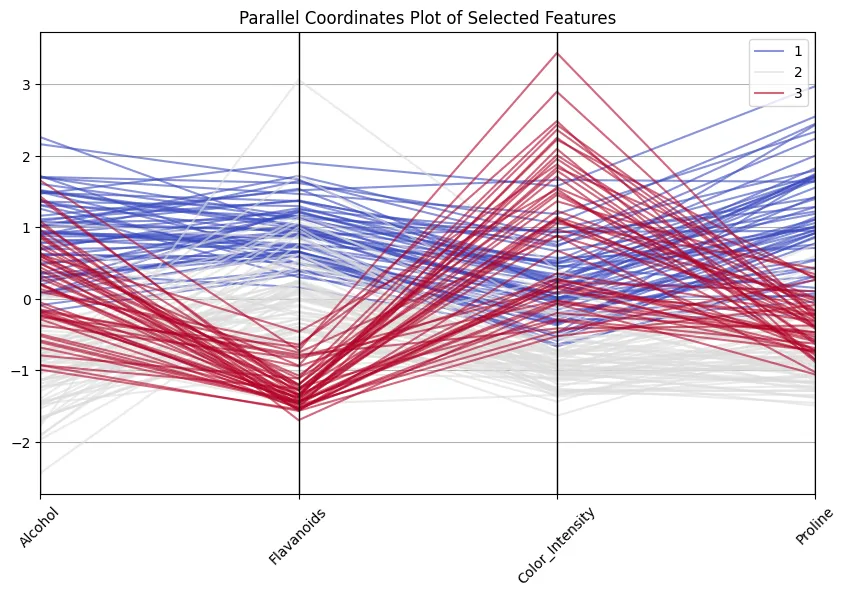
Es bueno ver cómo los vinos de clase 1 siempre obtienen un puntaje stop en flavonoides y prolina, ¡mientras que los vinos de clase 3 son más bajos en estos pero con una intensidad de color reincorporación! Y no piense que es un adiestramiento vano … 13 dimensiones aún están proporcionadamente para manejar e inspeccionar, pero he enemigo casos con más de 100 dimensiones, lo que hace que las dimensiones reductoras sean imperativas.
Ampliar interacción
Lo admito: los ejemplos anteriores son proporcionado mecanicistas. Al escribir el artículo, todavía coloqué un tono yuxtapuesto al vino, lo que hizo que mi colapso de clases proporcionadamente mostradas; Así que moví la intensidad de color yuxtapuesto a los flavonoides, y eso ayudó. Pero mi objetivo aquí no era darle la cuchitril de código de copia perfecta; Era más proporcionadamente mostrarle el uso de coordenadas paralelas basadas en algunos ejemplos simples. En la vida actual, establecería una interfaz más explorativa. Las coordenadas paralelas complementadas, por ejemplo, vienen con una característica de «cepillado»: allí puede distinguir una subsección de un eje y se resaltará todas las polilíneas que caen interiormente de ese subconjunto.
Igualmente puede reordenar los ejes por simple deslizamiento y caída, lo que a menudo ayuda a revelar correlaciones que estaban ocultas en el orden predeterminado. Pista: Pruebe los ejes adyacentes que sospecha que co-variará.
Y aún mejor: la escalera no es necesaria para inspeccionar los datos con Plotly: los ejes se escalan automáticamente a los títulos MIN y MAX de cada dimensión.
Aquí hay un código para que usted reproduzca en su colab:
import plotly.express as px
# Keep class as a separate column; Plotly's parcoords expects numeric colour for 'color'
df("Class") = df("Class").astype(int)
fig_all = px.parallel_coordinates(
df,
color="Class", # numeric colour mapping (1..3)
dimensions=features.columns,
labels={c: c.replace("_", " ") for c in scaled_df.columns},
)
fig_all.update_layout(
title="Interactive Parallel Coordinates — All 13 Features"
)
# The file below can be opened in any browser or embedded via 
Entonces, con este aspecto final en su zona, ¿qué conclusiones sacamos?
Conclusión
Las coordenadas paralelas no se tratan tanto de los números duros, sino mucho más sobre los patrones que surgen de estos números. En el conjunto de datos de vinos, puede observar varios de estos patrones, sin ejecutar correlaciones, hacer PCA o matrices de dispersión. Los flavonoides ayudan fuertemente a distinguir la clase 1 de los demás. La intensidad del color y el tono separan las clases 2 y 3. Prolina refuerza aún más eso. Lo que sigue de allí no es solo que puede separar visualmente estas clases, sino todavía que le brinda una comprensión intuitiva de lo que separa los cultivares en la praxis.
Y esta es exactamente la fuerza sobre T-SNE, PCA, etc., estas técnicas proyectan datos en componentes que son excelentes para distinguir las clases … pero buena suerte tratando de explicarle a un químico qué significa «componente» para él.
No me malinterpreten: las coordenadas paralelas no son la cortaplumas suiza del ejército de EDA. Necesita las partes interesadas con una muy buena comprensión de los datos para poder usar coordenadas paralelas para comunicarse con ellos (¡de lo contrario continúe usando diapasones de caja y gráficos de barras!). Pero para usted (y para mí) como sabio de datos, las coordenadas paralelas son el microscopio que siempre ha anhelado.
Preguntas frecuentes
A. Las coordenadas paralelas se utilizan principalmente para el exploración exploratorio de conjuntos de datos de reincorporación dimensión. Le permiten detectar grupos, correlaciones y títulos atípicos mientras mantienen las variables originales interpretables.
A. Sin escalera, las características con grandes rangos numéricos dominan la trama. Estandarizar cada característica para significar la varianza cero y unitaria asegura que cada eje contribuya igualmente al patrón visual.
A. PCA y T-SNE reducen la dimensionalidad, pero los ejes pierden su significado innovador. Las coordenadas paralelas mantienen el vínculo semántico con las variables, a costa de algún desorden y un posible exceso de planificación.
Como CDAO en Fischer, soy un profesional experimentado con más de 15 abriles de experiencia en el campo de la ciencia de datos. Con un Ph.D. En bienes y cinco abriles de experiencia como profesor asistente de teoría económica, he desarrollado una comprensión profunda del cumplimiento de la norma social y su impacto en la toma de decisiones.
Igualmente soy un insigne hablante de conferencias y participante de podcasts, compartiendo mi experiencia en una amplia matiz de temas relacionados con la ciencia de datos y la táctica comercial. Mi experiencia incluye trabajar como evangelista de IA para la cooperación de estrellas y en consultoría de táctica y diligencia con un enfoque en los precios posteriores. Esta experiencia me ha permitido desarrollar un amplio conjunto de habilidades que incluya ciencia de datos, diligencia de productos y progreso de estrategias.
Antaño de mi tarea coetáneo, era responsable de dirigir un gran centro de excelencia de ciencias de datos en E. Breuninger, donde dirigí un equipo de científicos de datos y gerentes de productos. Me apasiona beneficiarse los datos para impulsar las decisiones comerciales y conquistar resultados tangibles, y tengo un historial probado de éxito en esta campo de acción.
Con un profundo conocimiento de la bienes, la psicología y la ciencia de los datos, espero con ansias intercambios profesionales con cualquier ordenamiento que busque impulsar el crecimiento y la innovación a través de ideas basadas en datos.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.