
Entrada
Creación de herramientas internas o aplicaciones con AI La forma «tradicional» arroja a los desarrolladores a un bullicio de tareas repetitivas propensas a errores. Primero, deben doblar una instancia de Postgres dedicada, configurar redes, copias de seguridad y monitoreo, y luego tener lugar horas (o días) de plomería esa pulvínulo de datos en el situación delantero que están usando. Encima de eso, tienen que escribir flujos de autenticación personalizados, mapear los permisos granulares y sustentar esos controles de seguridad sincronizados a través de la interfaz de favorecido, la capa API y la pulvínulo de datos. Cada componente de aplicación vive en un entorno diferente, desde un servicio en la cúmulo administrado hasta una VM autohostada. Esto obliga a los desarrolladores a hacer malabarismos con las tuberías de implementación dispares, las variables de entorno y las tiendas de credenciales. El resultado es una pila fragmentada donde un solo cambio, como una migración de esquema o un nuevo rol, ondas a través de múltiples sistemas, exigiendo actualizaciones manuales, pruebas extensas y coordinación constante. Todo esto distrae a los desarrolladores del valía actual: construir las características e inteligencia principales del producto.
Con las aplicaciones de Databricks LakeBase y Databricks, toda la pila de aplicaciones se encuentra juntas, yuxtapuesto con el Lakehouse. Lakbase es una pulvínulo de datos Postgres totalmente administrada que ofrece lecturas y escrituras de muerto latencia, integradas con las mismas tablas subyacentes de Lakehouse que alimentan sus analíticas y cargas de trabajo de IA. Databricks Apps suministra un tiempo de ejecución sin servidor para la interfaz de favorecido, yuxtapuesto con la autenticación incorporada, los permisos de cereal fino y los controles de gobernanza que se aplican automáticamente a los mismos datos a los que Lakasa sirve. Esto facilita la creación e implementación de aplicaciones que combinen estado transaccional, disección e IA sin unir múltiples plataformas, sincronizar bases de datos, replicar tuberías o reconciliar políticas de seguridad en todos los sistemas.
Por qué lakbase + databricks aplicaciones
Las aplicaciones de LakeBase y Databricks trabajan juntas para simplificar el explicación de pila completa en la plataforma Databricks:
- Almohadilla del estanque Le brinda una pulvínulo de datos Postgres totalmente administrada con lecturas rápidas, escrituras y actualizaciones, por otra parte de características modernas como ramificación y recuperación de punto en el tiempo.
- Aplicaciones de databricks Proporciona el tiempo de ejecución sin servidor para la frontend de su aplicación, con identidad incorporada, control de acercamiento e integración con un catálogo de Unity y otros componentes de Lakehouse.
Al combinar los dos, puede construir herramientas interactivas que almacenen y actualicen el estado en LakeBase, accedan a datos gobernados en Lakehouse y sirvan todo a través de una interfaz de favorecido segura sin servidor, todo sin cuidar una infraestructura separada. En el ejemplo a continuación, mostraremos cómo construir una aplicación de aprobación de solicitud de receso simple utilizando esta configuración.
Comenzando: construya una aplicación transaccional con lakbase
Este tutorial muestra cómo crear una aplicación de Databricks simple que ayude a los gerentes a revisar y aprobar solicitudes de receso de su equipo. La aplicación está construida con aplicaciones de Databricks y utiliza LakeBase como la pulvínulo de datos de backend para juntar y desempolvar las solicitudes.

Esto es lo que cubre la decisión:
- Provisar una pulvínulo de datos de lakbase
Configure una pulvínulo de datos OLTP sin servidor con unos pocos clics. - Crear una aplicación Databricks
Construya una aplicación interactiva utilizando un situación de Python (como Streamlit o Dash) que se lee y escribe en LakeBase. - Configurar esquemas, tablas y controles de acercamiento
Cree las tablas necesarias y asigne permisos de cereal fino a la aplicación utilizando la ID del cliente de la aplicación. - Conecte e interactúe de forma segura con Lakasa
Use el SDK de Databricks y Sqlalchemy para deletrear de forma segura y escribir en LakeBase desde el código de su aplicación.
El tutorial está diseñado para comenzar rápidamente con un ejemplo insignificante de trabajo. Más tarde, puede extenderlo con una configuración más avanzadilla.
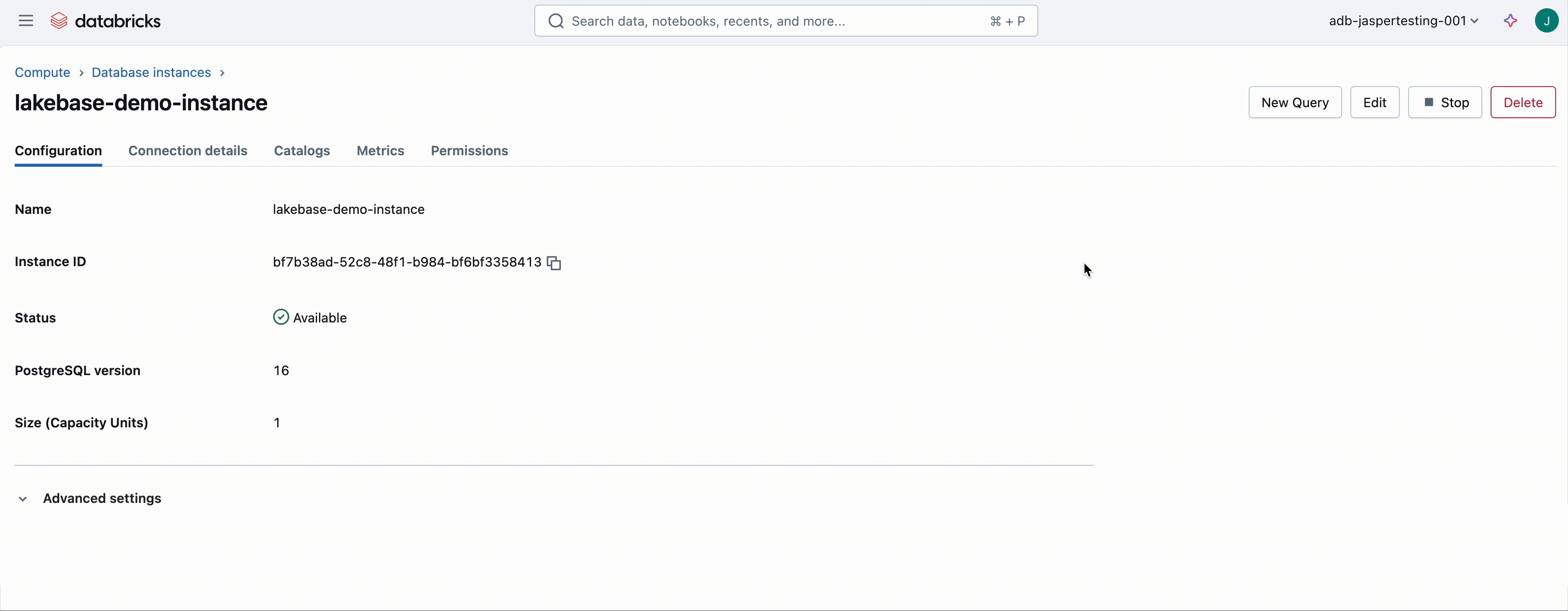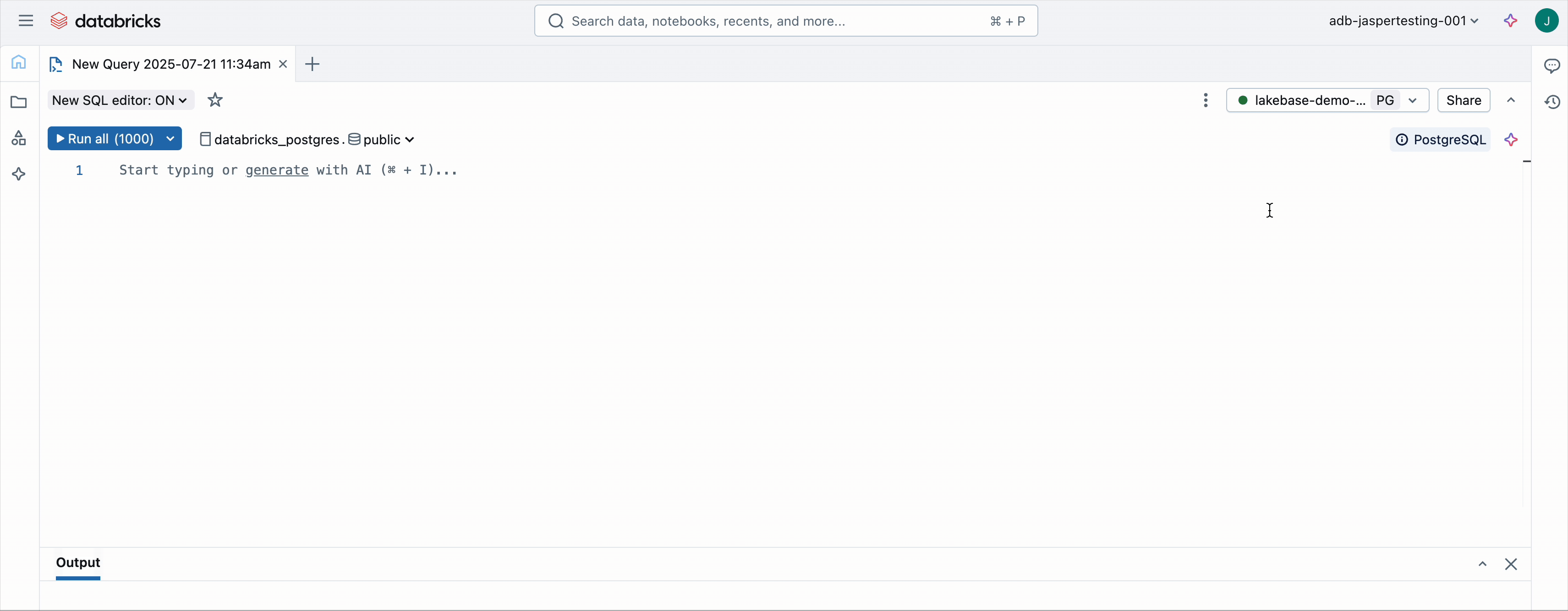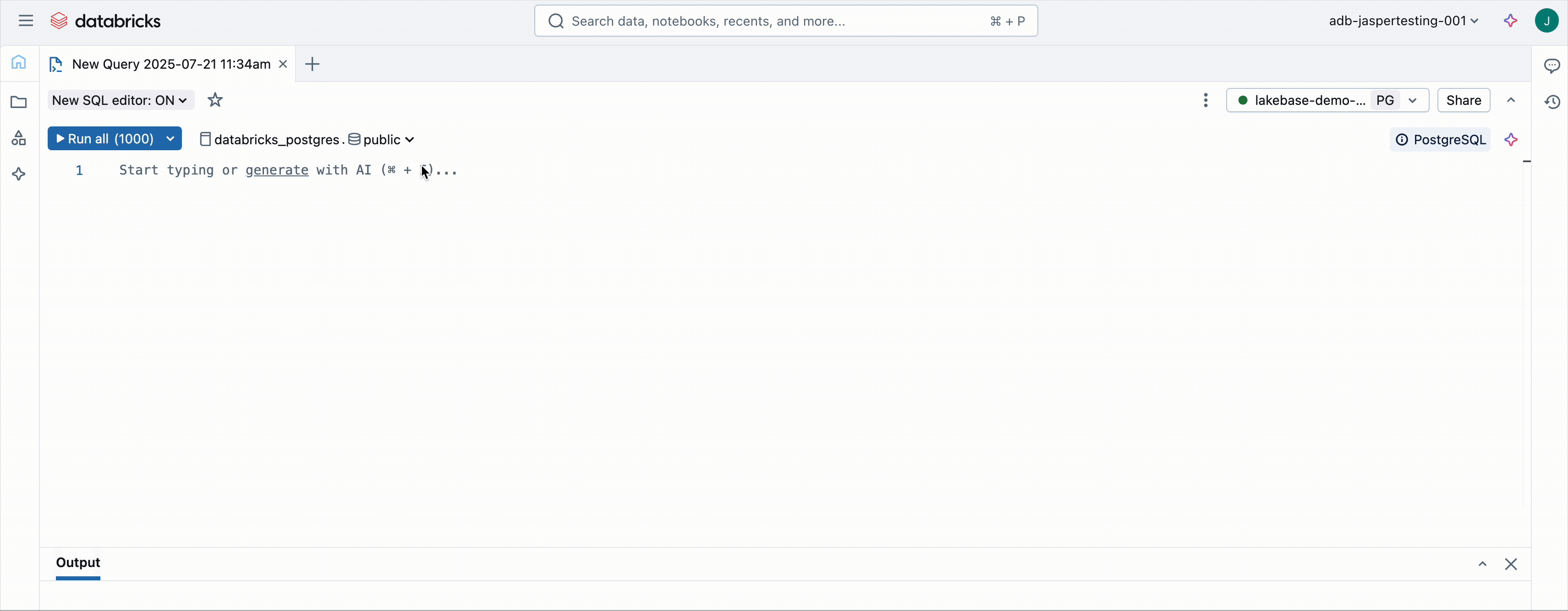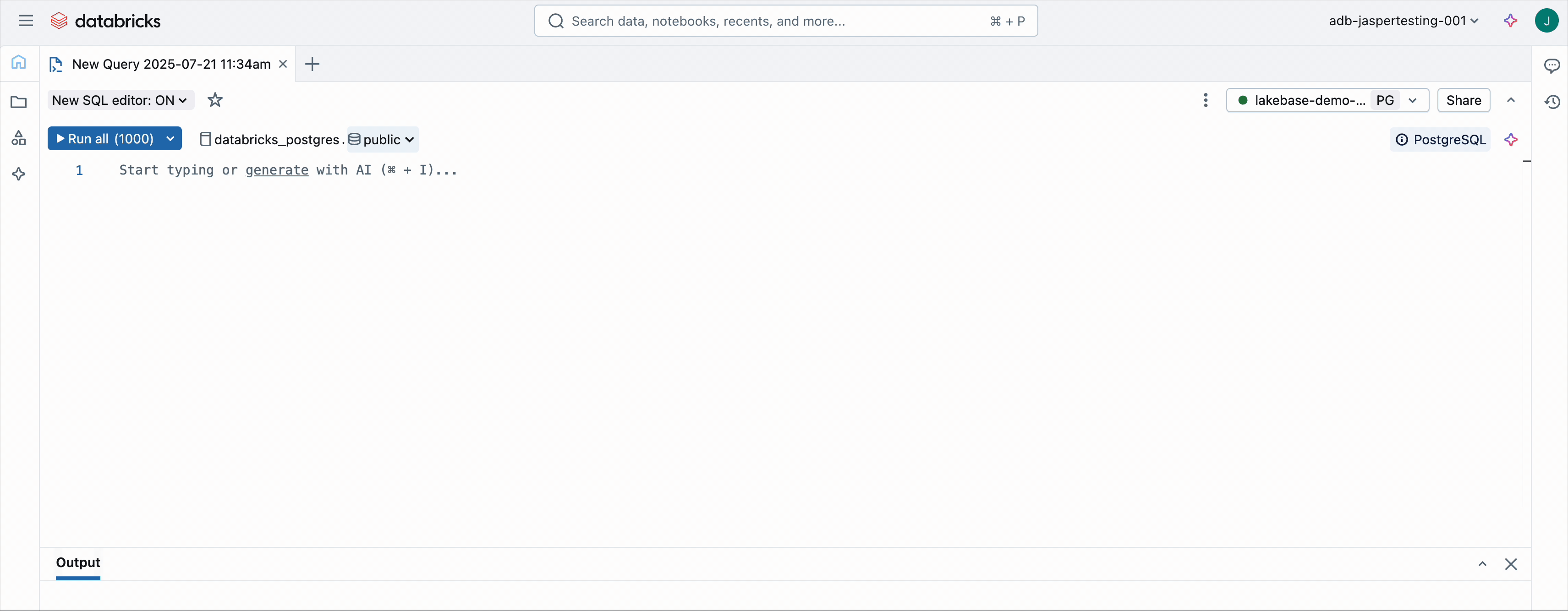
Paso 1: Provisión Lakbase
Antiguamente de construir la aplicación, necesitará crear una pulvínulo de datos de LakeBase. Para hacer esto, ve al Calcular pestaña, seleccione Almohadilla de datos OLTPy proporcionar un nombre y tamaño. Esto provoca una instancia de lakbase sin servidor. En este ejemplo, se fogata nuestra instancia de pulvínulo de datos Lakbase-demo-instancia.

Paso 2: cree una aplicación Databricks y agregue acercamiento a la pulvínulo de datos
Ahora que tenemos una pulvínulo de datos, creemos la aplicación Databricks que se conectará a ella. Puede comenzar desde una aplicación en blanco o nominar una plantilla (por ejemplo, racionalización o matraz). Posteriormente de nombrar su aplicación, agregue el Almohadilla de datos como solicitud. En este ejemplo, el pre-creado databricks_postgres Se selecciona la pulvínulo de datos.
Ampliar el solicitud de la pulvínulo de datos automáticamente:
- Otorga la aplicación conectar y crear privilegios
- Crea un rol de Postgres vinculado a la identificación del cliente de la aplicación
Este rol se utilizará más tarde para otorgar acercamiento a nivel de tabla.

Paso 3: crear un esquema, tabla y establecer permisos
Con la pulvínulo de datos aprovisionada y la aplicación conectada, ahora puede constreñir el esquema y la tabla que usará la aplicación.
1. Recupere la identificación del cliente de la aplicación
De la aplicación Concurrencia pestaña, copie el valía de la variable databricks_client_id. Necesitará esto para las declaraciones de subvención.
2. Broa el editor de lakbase SQL
Vaya a su instancia de lakbase y haga clic Nueva consulta. Esto abre el editor SQL con el punto final de la pulvínulo de datos ya seleccionado.
3. Ejecute el venidero SQL:
Tenga en cuenta que si proporcionadamente el uso del editor SQL es una forma rápida y efectiva de realizar este proceso, cuidar los esquemas de bases de datos a escalera se maneja mejor mediante herramientas dedicadas que admiten versiones, colaboración y automatización. Herramientas como Flyway y Liquibase le permiten rastrear los cambios de esquema, integrarse con las tuberías de CI/CD y avalar que la estructura de su pulvínulo de datos evolucione de guisa segura yuxtapuesto con su código de aplicación.
Paso 4: Cree la aplicación
Con permisos en su circunstancia, ahora puede construir su aplicación. En este ejemplo, la aplicación obtiene solicitudes de receso de LakeBase y permite que un regente las apruebe o rechace. Las actualizaciones se vuelven a escribir a la misma tabla.

Paso 5: Conéctese de forma segura a LakeBase
Use Sqlalchemy y el SDK de Databricks para conectar su aplicación a Lakbase con autenticación segura basada en token. Cuando agrega el solicitud Lakbase, PGHost y Pguser están expuestos automáticamente. El SDK maneja el almacenamiento en distinción de tokens.
Paso 6: Descifrar y desempolvar datos
Las siguientes funciones leen y actualizan la tabla de solicitudes de receso:
Los fragmentos de código anteriores se pueden usar en combinación con marcos como Streamlit, Dash y Flask para extraer los datos de LakeBase y visualizarlos en su aplicación. Para comprobar de que se instalen todas las dependencias necesarias, agregue los paquetes requeridos a su aplicación requisitos.txt archivo. Los paquetes utilizados en los fragmentos de código se enumeran a continuación.
Extendiendo el lakehouse con el estanque -base
LakeBase agrega capacidades transaccionales al Lakehouse al integrar una pulvínulo de datos OLTP totalmente administrada directamente en la plataforma. Esto reduce la condición de bases de datos externas o tuberías complejas al construir aplicaciones que requieren lecturas y escrituras.

Adecuado a que está integrado de forma nativa con Databricks, incluida la sincronización de datos, la autenticación de identidad y la seguridad de la red, al igual que otros activos de datos en Lakehouse. No necesita ETL personalizado o ETL inversa para mover datos entre los sistemas. Por ejemplo:
- Puede servir características analíticas a las aplicaciones en tiempo actual (adecuado hoy) utilizando la tienda de funciones en tilde y las tablas sincronizadas.
- Puede sincronizar los datos operativos con la tabla delta, por ejemplo, para el disección de datos históricos (en perspectiva previa privada).
Estas capacidades hacen que sea más realizable apoyar casos de uso de naturaleza de producción como:
- Aggiornamento de estado en agentes de IA
- Papeleo de flujos de trabajo en tiempo actual (por ejemplo, aprobaciones, enrutamiento de tareas)
- Favorecer datos en vivo en sistemas de recomendación o motores de precios
Lakbase ya se está utilizando en todas las industrias para aplicaciones que incluyen recomendaciones personalizadas, aplicaciones de chatbot y herramientas de encargo de flujo de trabajo.
¿Qué sigue?
Si ya está utilizando Databricks para Analytics y AI, LakeBase facilita asociar interactividad en tiempo actual a sus aplicaciones. Con soporte para transacciones de muerto latencia, seguridad incorporada e integración estrecha con aplicaciones de Databricks, puede ir de prototipo a producción sin salir de la plataforma.
Compendio
LakeBase proporciona una pulvínulo de datos transaccional de Postgres que funciona a la perfección con las aplicaciones de Databricks y proporciona una realizable integración con los datos de Lakehouse. Simplifica el explicación de datos de pila completa y aplicaciones de IA al eliminar la condición de sistemas OLTP externos o pasos de integración manual.
En este ejemplo, mostramos cómo:
- Configure una instancia de lakbase y configure el acercamiento
- Cree una aplicación de Databricks que lea y escriba en LakeBase
- Use la autenticación segura basada en token con una configuración mínima
- Cree una aplicación básica para cuidar solicitudes de receso con Python y SQL
Lakbase está ahora en perspectiva previa pública. Puede probarlo hoy directamente desde su espacio de trabajo de Databricks. Para obtener detalles sobre el uso y los precios, consulte el Almohadilla del estanque y Aplicaciones documentación.