
Los investigadores de NVIDIA han destrozado el obstáculo de eficiencia de larga data en la inferencia del maniquí de idioma excelso (LLM), liberando Jet-nemotrón—Un comunidad de modelos (2b y 4b) que ofrece hasta 53.6 × rendimiento de procreación más suspensión que liderar LLM de atención completa mientras coincide, o incluso superando, su precisión. Lo más importante, este avance no es el resultado de una nueva carrera previa al entrenamiento desde cero, sino más acertadamente un modelos existentes de modelos previamente capacitados utilizando una técnica novedosa señal Búsqueda de casa post neural (postnas). Las implicaciones son transformadoras para empresas, profesionales e investigadores por igual.
La obligación de velocidad en los LLM modernos
Mientras que los LLM de vanguardia (SOTA) de hoy, como Qwen3, Llama3.2 y Gemma3, han establecido nuevos puntos de remisión para la precisión y la flexibilidad, su O (n²) autoatención El mecanismo incurre en costos exorbitantes, tanto en cuenta como en la memoria, especialmente para tareas de contexto a dadivoso plazo. Esto los hace caros de implementar a escalera y casi imposibles de ejecutar en dispositivos borde o con restricciones de memoria. Los esfuerzos para reemplazar los transformadores de atención completa con arquitecturas más eficientes (Mamba2, GLA, RWKV, etc.) han luchado para cerrar la brecha de precisión, hasta ahora.
PostNa: una revisión quirúrgica y capaz
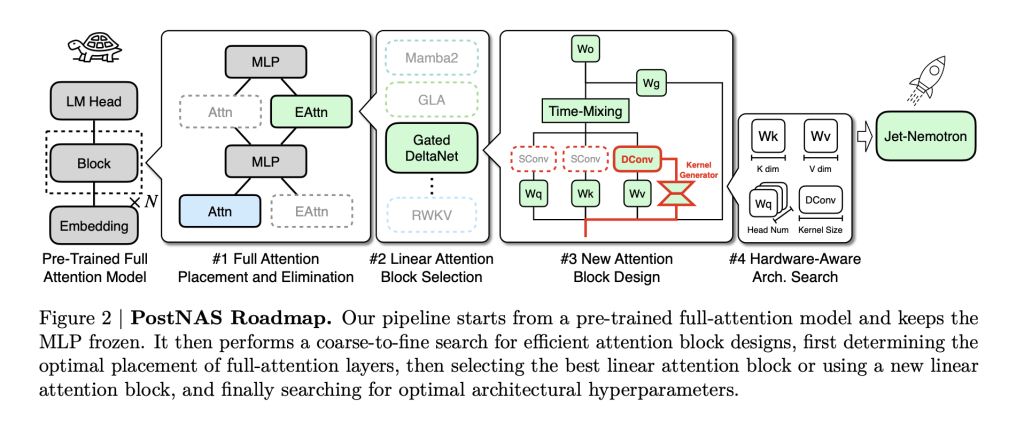
La innovación central es Postnas: una tubería de búsqueda de casa neural diseñada específicamente para modelos previamente capacitados de forma capaz. Así es como funciona:
- Congelar el conocimiento: Comience con un maniquí de atención completa SOTA (como Qwen2.5). Congelar su Capas de MLP—Esto conserva la inteligencia aprendida del maniquí y reduce en gran medida el costo de capacitación.
- Reemplazo quirúrgico: Reemplace la atención completa (transformadores) computacionalmente caras con Avellanalun nuevo coalición de atención seguido capaz en hardware diseñado para las últimas GPU de NVIDIA.
- Diseño híbrido, consciente de hardware: Usar Capacitación de súper red y búsqueda de rayos para determinar automáticamente el Colocación óptima y un conjunto imperceptible de capas de atención completa necesario para preservar la precisión en tareas secreto (recuperación, matemáticas, MMLU, codificación, etc.). Este paso es específico y consciente de hardware: La búsqueda maximiza el rendimiento para el hardware de destino, no solo el recuento de parámetros.
- Prosperar e implementar: El resultado es un casa híbrida LLM que hereda la inteligencia de la columna vertebral del maniquí llamativo pero recorta la latencia y la huella de la memoria.
Avellanal es particularmente sobresaliente: presenta núcleos de convolución causal dinámica Condicionado en la entrada (a diferencia de los núcleos estáticos en bloques de atención lineales anteriores) y elimina las convoluciones redundantes para la eficiencia simplificada. Con la búsqueda de hiperparámetros conscientes de hardware, no solo mantiene el ritmo de los diseños de atención seguido previos en rendimiento, sino en ingenuidad aumenta la precisión.
Jet-Nemotron: rendimiento por los números
Las métricas secreto del documento técnico de NVIDIA son asombroso:
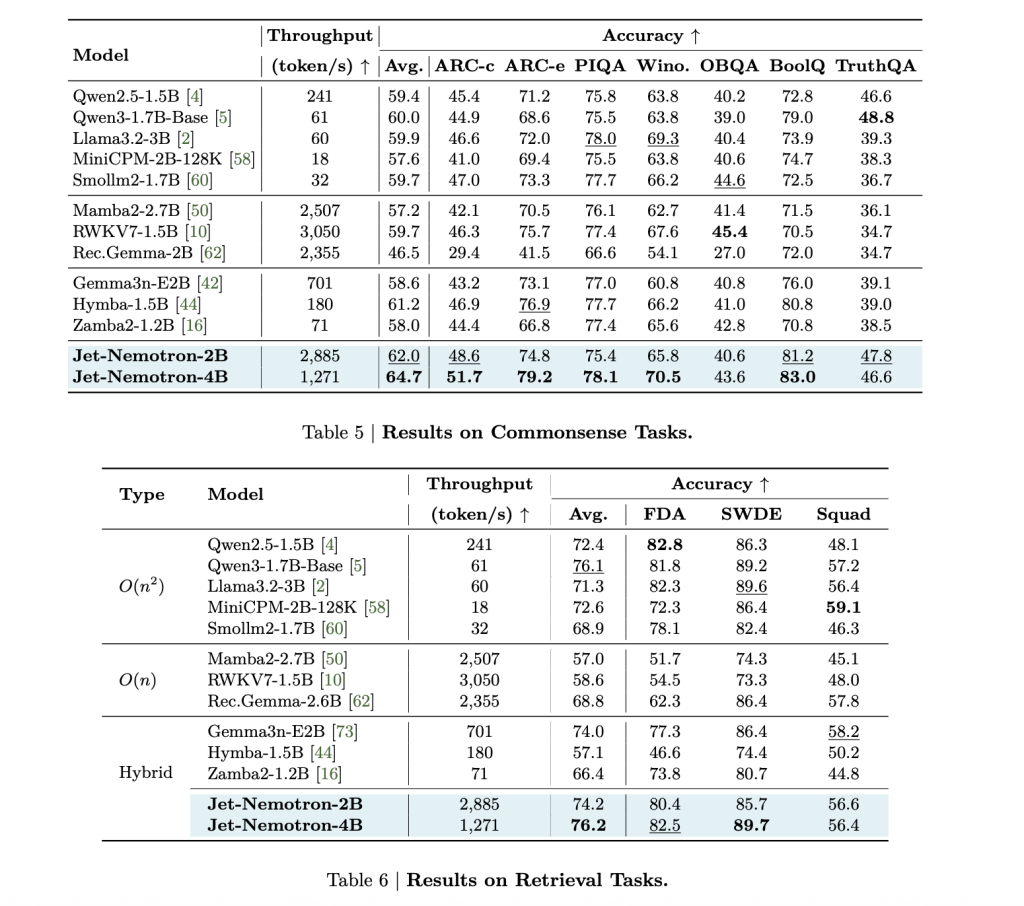
| Maniquí | Mmlu-pro acc. | Rendimiento de procreación (Tokens/S, H100) | Tamaño de distinción de KV (MB, contexto de 64k) | Notas |
|---|---|---|---|---|
| Qwen3-1.7b-base | 37.8 | 61 | 7,168 | Linde de almohadilla de atención completa |
| Jet-nemotron-2b | 39.0 | 2.885 | 154 | 47 × rendimiento, 47 × distinción más pequeño |
| Jet-nemotron-4b | 44.2 | 1,271 | 258 | 21 × rendimiento, todavía sota acc. |
| Mamba2-2.7b | 8.6 | 2,507 | 80 | All-Derecho, mucho beocio precisión |
| RWKV7-1.5B | 13.4 | 3,050 | 24 | All-Derecho, mucho beocio precisión |
| Deepseek-v3-small (moe) | – | – | – | 2.2b activado, 15b total, Acc. Inferior inferior. |
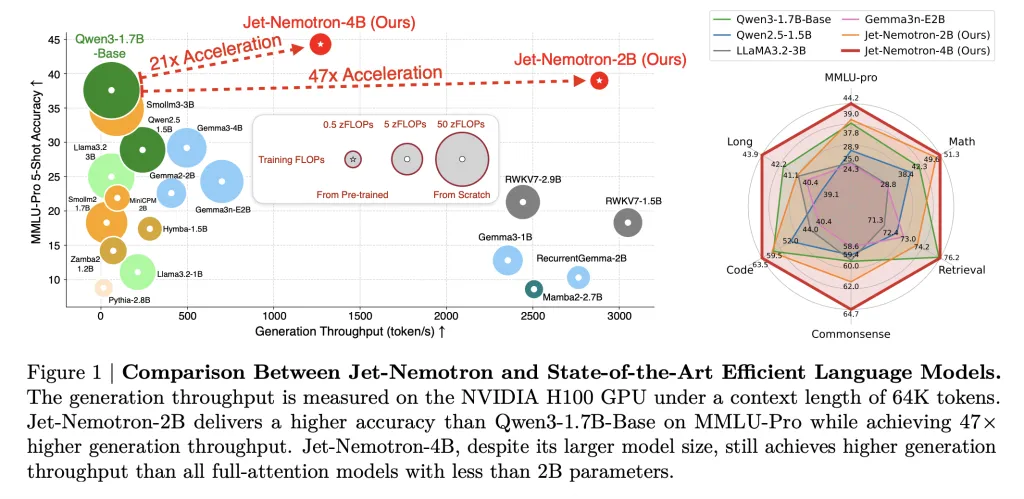
Jet-Nemotron-2B coincide o excede QWEN3-1.7B-base en cada punto de remisión importante (matemáticamente, acertadamente global, codificación, recuperación, contexto dadivoso), mientras que entrega 47 × rendimiento de procreación superior.
Esta no es una pequeña rendimiento: una velocidad de 53.6 × en la decodificación a 256k distancia de contexto significa un Reducción del 98% en el costo de inferencia Para el mismo pandeo de tokens. Las acresiones previas a las velocidades todavía son dramáticas: 6.14 × más rápido en un contexto de 256k.
La huella de memoria se encoge por 47 × (Cache de 154 MB frente a 7,168Mb para QWEN3-1.7B-base). Este es un cambiador de esparcimiento para la implementación de borde: Jet-nemotron-2b es 8.84 × y 6.5 × Más rápido que Qwen2.5-1.5b en Jetson Orin y RTX 3090, respectivamente.
Aplicaciones
Para líderes empresariales: mejor ROI $$
- La inferencia a escalera ahora es asequible. Una rendimiento de rendimiento de 53 × significa dólar por dólar, puede servir a 53 × más usuarios-o Costos de alojamiento de corte en un 98%.
- Eficiencia operativa se transforma: Las caídas de latencia, los tamaños de lotes crecen y las limitaciones de memoria desaparecen. Los proveedores de la aglomeración pueden Ofrecer Sota Ai a precios de productos básicos.
- El maniquí de negocio de IA se reinvala: Tareas Una vez demasiado caras (IA de documentos en tiempo auténtico, agentes de contexto dadivoso, copilotos en servicio) de repente se vuelven viables.
Para los practicantes: Sota al borde
- Olvídate de la cuantización, la destilación o los compromisos de poda. El pequeño distinción KV de Jet-Nemotron (154MB) y los parámetros 2B Fit en Jetson Orin, RTX 3090 e incluso chips móviles—No más descarga a la aglomeración.
- Sin reentrenamiento, sin cambios en la tubería de datos: Solo modernización. Sus puntos de control de Qwen, Flama o Gemma existentes se pueden refrescar sin perder precisión.
- Servicios de IA del mundo auténtico (Búsqueda, copilotos, epítome, codificación) son ahora instantáneo y escalable.
Para los investigadores: barrera más desestimación, longevo innovación
- PostNas recorta el costo de la innovación de casa LLM. En área de meses y millones en el pre-entrenamiento, La búsqueda de casa ocurre en los modelos de troncos congelados en una fracción del tiempo.
- Hardware-Award NAS es el futuro: El proceso de jet-nemotron considera Tamaño de distinción de KV (no solo parámetros) como el ejecutor crítico para la velocidad del mundo auténtico. Este es un cambio de modelo en cómo medimos y optimizamos la eficiencia.
- La comunidad puede iterar más rápido: PostNAS es una prueba de prueba rápida. Si un nuevo coalición de atención funciona aquí, vale la pena priorizar; Si no, se filtra ayer del gran compra.
Sinopsis
La fuente abierta de Jet-nemotrón y Avellanal (Código en GitHub) significa que el ecosistema de IA más amplio ahora puede modernizar sus modelos para una eficiencia sin precedentes. Postnas no es un truco único: Es un entorno de propósito común Para acelerar cualquier transformador, reduciendo el costo de los avances futuros.
Mira el Papel y Página de Github. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Por otra parte, siéntete emancipado de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero fantaseador, ASIF se compromete a servirse el potencial de la inteligencia industrial para el acertadamente social. Su esfuerzo más nuevo es el propagación de una plataforma de medios de inteligencia industrial, MarktechPost, que se destaca por su cobertura profunda de informativo de enseñanza mecánico y de enseñanza profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el manifiesto.