
En Amazon EMRescuchamos constantemente los desafíos de nuestros clientes con la ejecución a gran escalera Amazon EMR HBase despliegues. Un punto de dolor consistente que mantuvo emergiendo es un comportamiento de aplicación impredecible oportuno a la cosecha de basura (GC) se detiene en HBase. Los clientes que ejecutaban cargas de trabajo críticas en HBase estaban experimentando picos de latencia ocasionales oportuno a diferentes pausas de GC, particularmente impactando cuando ocurrieron durante las horas hábiles máximas.
Para someter este impacto impredecible a las aplicaciones críticas de negocios que se ejecutan en HBase, pasamos a Oracle’s Z recolector de basura (ZGC), específicamente su soporte generacional introducido en JDK 21. Generacional ZGC ofrece tiempos de pausa de subcilosegundos consistentes que reducen drásticamente la latencia de la culo.
En esta publicación, examinamos cómo las pausas de GC impredecibles afectan las cargas de trabajo críticas de los negocios, los beneficios de permitir el ZGC generacional en HBASE. Igualmente cubrimos técnicas adicionales de ajuste GC para mejorar el rendimiento de la aplicación y someter la latencia de la culo. Amazon EMR 7.10.0 presenta nuevos parámetros de configuración que le permiten configurar y ajustar a la perfección el recolector de basura para los servidores de regiones HBase.
Al incorporar la colección generacional en la edificación de pausa intolerante disminución de ZGC, maneja eficientemente objetos de corta duración y de larga vida, lo que lo hace excepcionalmente adecuado para las características de carga de trabajo de HBase:
- Manejo de vidas de objetos mixtos – Las operaciones de HBase crean una combinación de objetos de corta duración (como búferes temporales para operaciones de ojeada/escritura) y objetos de larga vida (como bloques de datos en personalidad y metadatos). El ZGC generacional puede manejar de modo competente los dos, reduciendo la frecuencia genérico de GC y el impacto.
- Adaptarse a patrones de carga de trabajo – A medida que los patrones de carga de trabajo cambian a lo derrochador del día, por ejemplo, desde la ingestión de escritura hasta el investigación de ojeada pesada, el ZGC generacional adapta su organización de cosecha, manteniendo un rendimiento magnífico.
- Escalera con tamaño de montón – A medida que crecen los volúmenes de datos y los grupos de HBase requieren montones más grandes, el ZGC generacional mantiene los tiempos de pausa de sub-milisegundos, proporcionando un rendimiento constante incluso a medida que aumenta.
Comprender el impacto de GC hace una pausa en HBase
Al ejecutar los servidores de regiones HBASE, el montón JVM puede acumular una gran cantidad de objetos, tanto de corta duración (objetos temporales creados durante las operaciones) como de larga duración (datos en personalidad, metadatos). Los coleccionistas de basura tradicionales como Basura primera recolectora de basura (G1 GC) Necesita detener los hilos de aplicación durante ciertas fases de la cosecha de basura, particularmente durante los eventos «Stop-the-World» (STW). Las pausas de GC pueden tener varios impactos en HBase:
- Picos de latencia – Las pausas de GC introducen picos de latencia, a menudo afectando las latencias de culo (P99.9 y P99.99) de la aplicación que puede conducir a un tiempo de prórroga para las solicitudes de los clientes y los tiempos de respuesta inconsistentes.
- Disponibilidad de la aplicación – Todos los hilos de aplicación se detienen durante los eventos STW y afecta negativamente la disponibilidad genérico de la aplicación.
- RegionServer Fallos – Si las pausas de GC exceden el tiempo de prórroga de la sesión de Zookeeper configurado, podrían conducir a las fallas en el servidor de regiones.
HBase RegionServer informa siempre que hay un tiempo de pausa de GC inusualmente derrochador usando el JvmPauseMonitor. La futuro entrada del registro muestra un ejemplo de pausas de GC informadas por HBase RegionServer. Durante YCSB Benchmarking, G1 GC exhibió 75 de esas pausas durante un período de 7 horasmientras ZGC generacional no mostró pausas largas en condiciones de carga de trabajo y pruebas idénticas.
Las pausas de G1 GC son proporcionales a la presión sobre el montón y los patrones de asignación de objetos. Como resultado, las pausas podrían empeorar si el montón está bajo demasiada carga, mientras que el ZGC generacional mantiene sus objetivos de pausa incluso bajo ingreso presión.
Comparación de tiempo y disponibilidad de pausa (tiempo de actividad): Generacional ZGC vs. G1GC en Amazon EMR HBase
Nuestras pruebas revelaron diferencias significativas en el tiempo de pausa de GC entre el ZGC generacional y G1 GC para HBASE en Amazon EMR 7.10. Utilizamos la configuración del clúster de 1 m5.4xLarge (primario), 5 m5.4xLarge (núcleo) de los nodos y ejecutamos múltiples iteraciones de 1 billón de filas YCSB cargas de trabajo para comparar las pausas de GC y el porcentaje de tiempo de inicio. Según nuestro clúster de prueba, observamos una mejoramiento del tiempo de pausa de GC desde más de 1 minuto, 24 segundos, hasta menos de 1 segundo durante más de una ejecución de una hora, mejorando el tiempo de actividad de la aplicación de 98.08% a 99.99%.
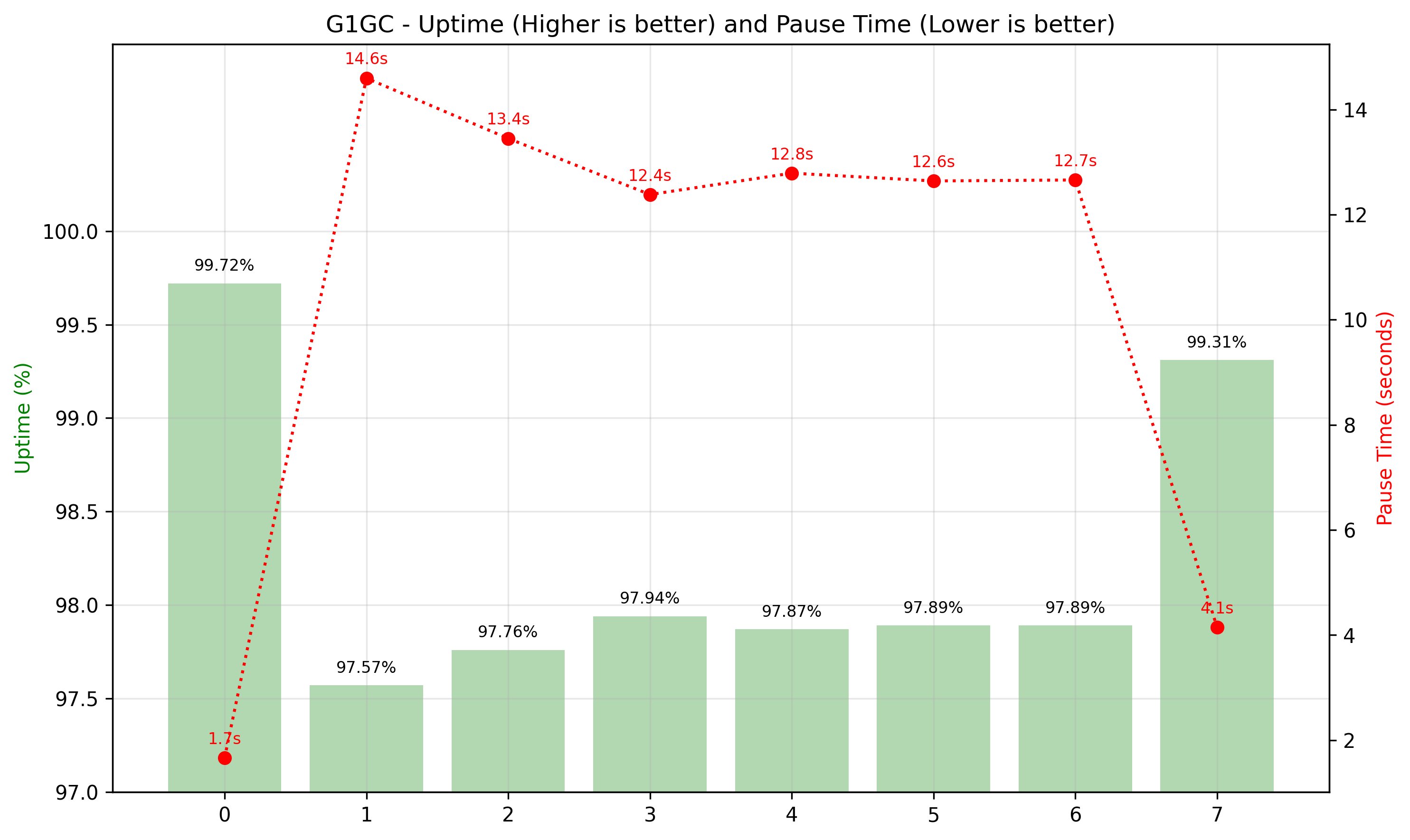
Realizamos pruebas de rendimiento extensas que comparan G1 GC y ZGC generacional en clústeres HBase que se ejecutan en Amazon EMR, utilizando la configuración de Heap predeterminada configurada automáticamente en función de Estrato de enumeración elástica de Amazon (Amazon EC2) Tipo de instancia. La futuro imagen muestra la comparación tanto en el tiempo de pausa de GC como en el porcentaje de tiempo de actividad a una carga máxima de 3,00,000 solicitudes por segundo (datos muestreados durante 1 hora).
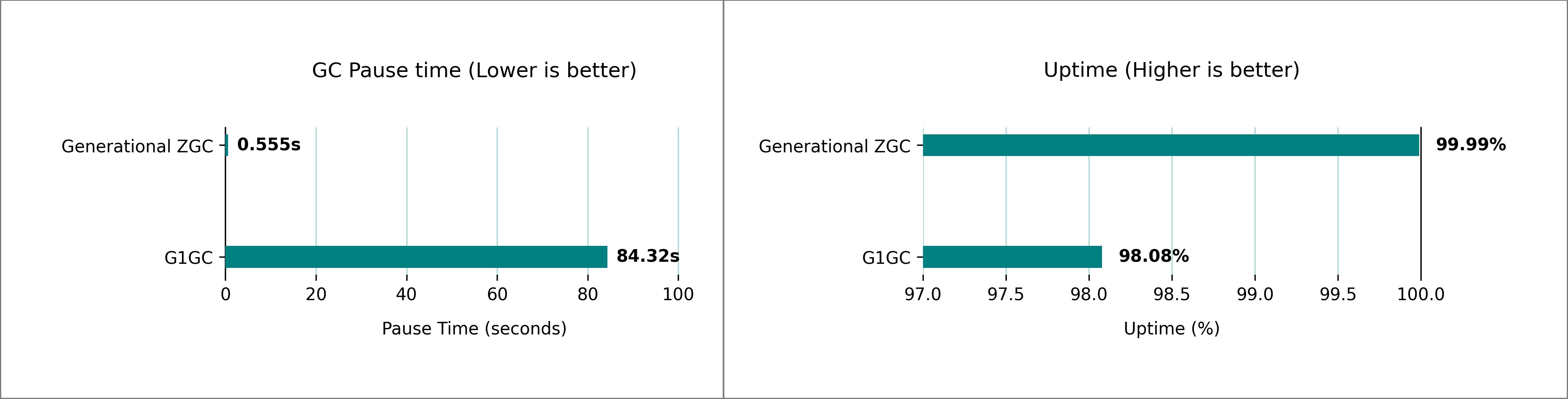
Las siguientes cifras muestran el desglose del tiempo de ejecución de 1 hora en intervalos de 10 minutos. El eje tieso izquierdo mide el tiempo de actividad, el eje tieso derecho mide el tiempo de pausa de GC, y el eje horizontal muestra el intervalo. El ZGC generacional mantuvo tiempo de actividad constante y tiempo de pausa en milisegundos, y G1 GC demostró un tiempo de actividad inconsistente y disminuido, los tiempos de pausa en segundos.

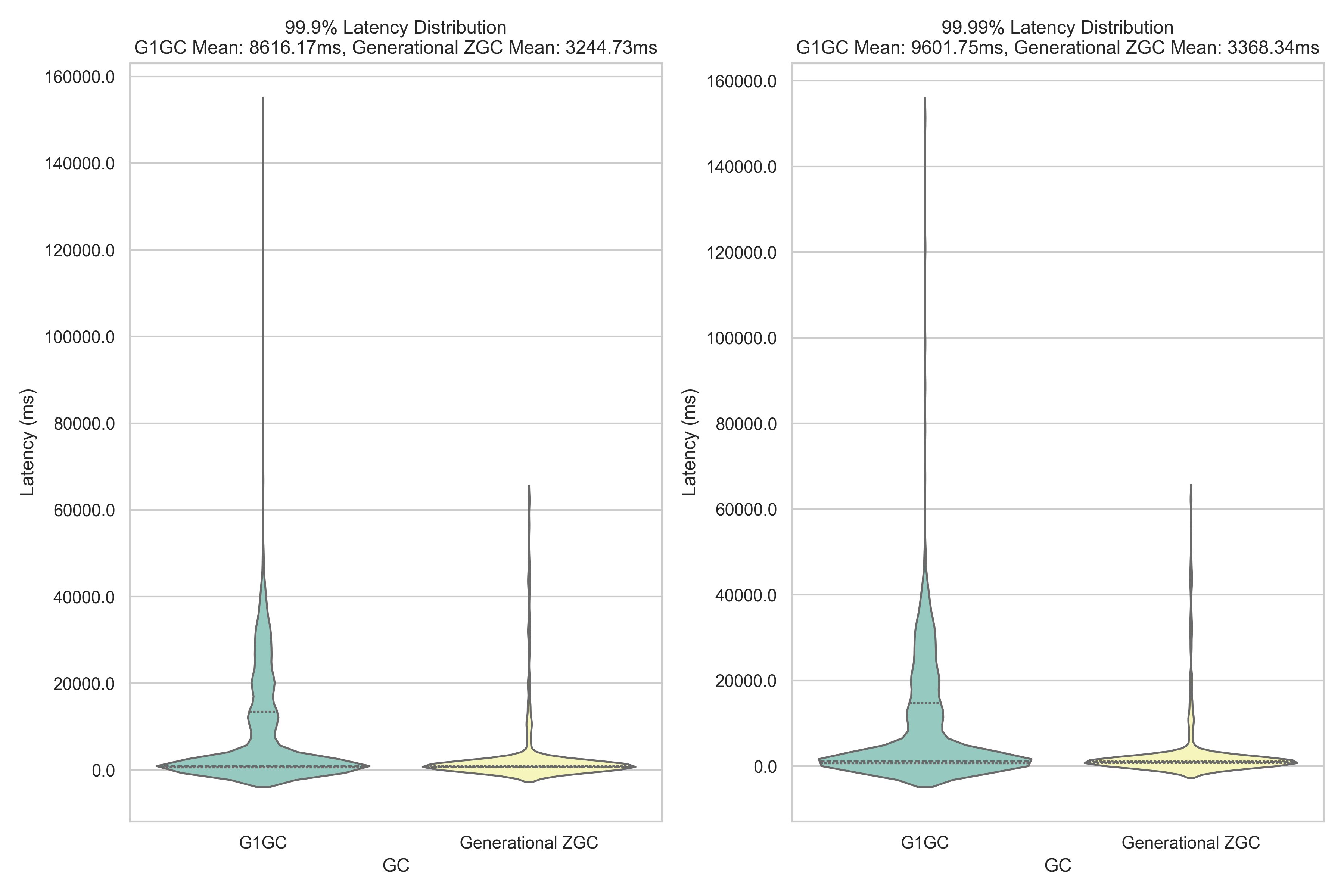
Comparación de latencia de culo: ZGC generacional vs. G1GC en Amazon EMR HBase
Una de las ventajas más convincentes de ZGC generacional sobre G1 GC es su comportamiento predecible de cosecha de basura y el impacto en la latencia de la culo de aplicación. Los desencadenantes de colección de G1 GC no son deterministas, lo que significa que los tiempos de pausa pueden variar significativamente y ocurrir a intervalos impredecibles. Estas pausas inesperadas, aunque generalmente manejables, pueden crear picos de latencia que afectan particularmente el percentil más tardo de operaciones. En contraste, el ZGC generacional mantiene tiempos consistentes de pausa de sub-milisegundos a lo derrochador de su operación. Esta previsibilidad resulta crucial para las aplicaciones que requieren un rendimiento estable, especialmente en los percentiles más altos de latencia (percentiles 99.9 y 99.99). Nuestras pruebas de narración YCSB revelan el impacto del mundo auténtico de estos diferentes enfoques. El futuro representación ilustra la distribución de latencia de la culo entre G1 GC y ZGC generacional durante un período de muestreo de 2 horas:
Mejoras a BucketCache
BucketCache es un personalidad fuera de ingreso en HBase que se utiliza para juntar en personalidad los bloques de datos a los que se accede con frecuencia y minimiza las E/S de disco. La memoria de personalidad y almacenamiento de montón funciona en conjunto y podría aumentar la contención en el montón dependiendo de la carga de trabajo. Generacional ZGC mantiene sus objetivos de tiempo de pausa incluso con un personalidad de cubo del tamaño de un terabyte. Benchmaramos múltiples grupos de HBase con diferentes tamaños de personalidad de cubos y 32 GB RegionServer Heap. Las siguientes cifras muestran los tiempos de pausa máximos observados durante un período de muestreo de 1 hora, comparando G1 GC y el rendimiento generacional de ZGC.
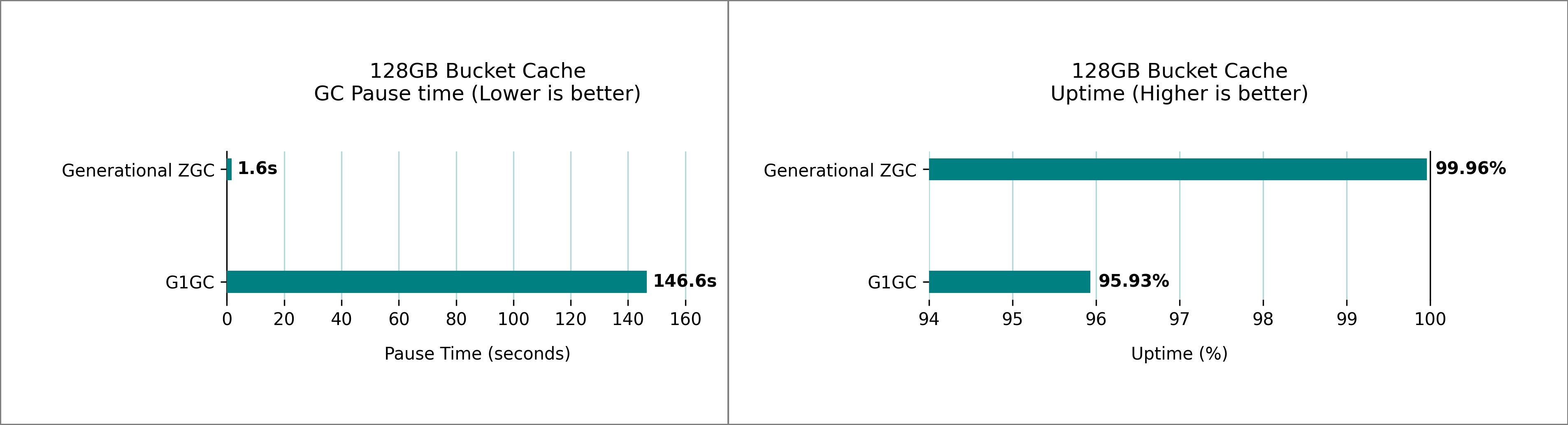
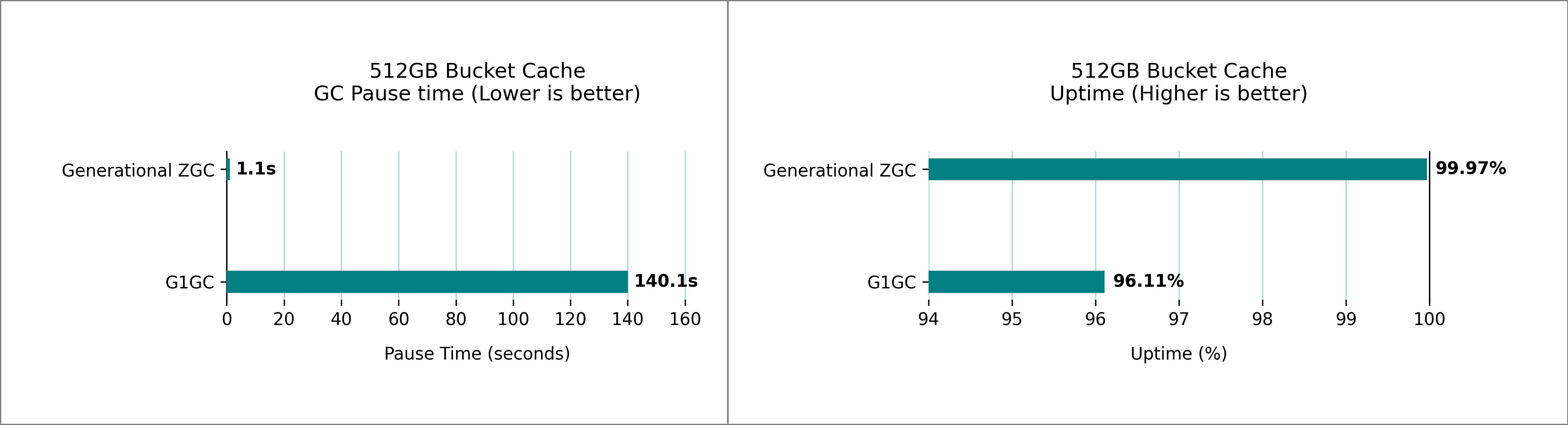
Habilitando esta función y parámetros adicionales de ajuste fino
Para habilitar esta función, siga las configuraciones mencionadas en el Consideraciones de rendimiento. En las siguientes secciones, discutimos los parámetros adicionales de ajuste fino para adaptar la configuración para su caso de uso específico.
Monta de JVM fijada
Los trabajos de procesamiento por lotes y las aplicaciones de corta duración se benefician de la capacidad de la asignación dinámica para adaptarse a diferentes tamaños de entrada y demandas de procesamiento cuando múltiples aplicaciones coexisten en el mismo clúster y se ejecutan con restricciones de capital. La huella de la memoria puede expandirse durante el procesamiento mayor y el pacto cuando la carga de trabajo disminuye. Sin confiscación, para la producción de implementaciones de HBASE sin ninguna aplicación coexistente en la misma asignación de almacenamiento fijo ofrece un rendimiento estable y confiable.
La asignación dinámica del montón es cuando el JVM crece de modo flexible y reduce su uso de memoria entre los límites mínimos (-xms) y máximos (-xmx) basados en las deyección de la aplicación, devolviendo la memoria no utilizada al sistema activo. Sin confiscación, esta flexibilidad tiene el costo de la sobrecarga de rendimiento y la fragmentación de la memoria. La asignación dinámica parecía flexible, pero creó interrupciones constantes. El JVM siempre estaba negociando con el sistema activo para la memoria, lo que condujo a gastos generales y fragmentación de rendimiento. Por otro costado, la asignación de montón fijo prevalece una cantidad constante de memoria para el JVM al inicio y lo mantiene durante el tiempo de ejecución, proporcionando un mejor rendimiento al someter la sobrecarga de negociación de memoria con el sistema activo. Para habilitar esta función, use la futuro configuración ::
Habilitar antiguamente del toque
Las aplicaciones con montones grandes pueden examinar pausas más significativas cuando el JVM necesita asignar y resolver en nuevas páginas de memoria. Pre-touch (-xx:+siempre interpretado) instruye al JVM que toque físicamente y comete todas las páginas de memoria durante la inicialización del montón, en empleo de esperar hasta que se accediera por primera vez durante el tiempo de ejecución. Este compromiso temprano reduce la latencia de las fallas de la página a pedido y las asignaciones de memoria que ocurren cuando se accede por primera vez a las páginas, lo que resulta en un rendimiento más predecible, especialmente durante las situaciones de carga pesada. Al pre-toque las páginas de memoria en el inicio, intercambias un tiempo de inicio JVM un poco más derrochador para un rendimiento de tiempo de ejecución más consistente. Para habilitar previamente touch para su clúster HBase, use la futuro configuración:
Aumento de las asignaciones de memoria para montones grandes
Dependiendo de la carga de trabajo y la escalera, es posible que deba aumentar el tamaño del montón de Java para acomodar grandes datos en la memoria. Cuando se usa el ZGC generacional con una configuración de montón vasto, es fundamental aumentar asimismo el término de mapeo de memoria del sistema activo (vm.max_map_count).
Cuando se inicia una aplicación habilitada para ZGC, el JVM verifica proactivamente el sistema vm.max_map_count valencia. Si el término es demasiado bajo para reconocer el montón configurado, emitirá la futuro advertencia:
Para aumentar las asignaciones de memoria, use la futuro configuración y ajuste el valencia de conteo en el comando en función del tamaño del montón de la aplicación.
Conclusión
La comienzo de ZGC generacional y la asignación de montón fijo para HBase en Amazon EMR marca un brinco significativo alrededor de delante en el rendimiento predecible y la reducción de la latencia de la culo. Al tocar los desafíos de larga data de las pausas de GC y la administración de la memoria, estas características desbloquean nuevos niveles de eficiencia y estabilidad para las implementaciones de Amazon EMR HBase. Aunque las mejoras de rendimiento varían según las características de la carga de trabajo, puede esperar ver mejoras significativas en la capacidad de respuesta y estabilidad de su Amazon EMR HBase Clusters. A medida que los volúmenes de datos continúan creciendo y los requisitos de disminución latencia se vuelven cada vez más estrictas, las características como ZGC generacional y la asignación de almacenamiento fijo se vuelven indispensables. Alentamos a los usuarios de HBASE en Amazon EMR a habilitar estas características y examinar los beneficios de primera mano. Como siempre, recomendamos pruebas en un entorno de estadificación que refleje su carga de trabajo de producción para comprender completamente el impacto y optimizar las configuraciones para su caso de uso específico.
Estén atentos para más innovaciones mientras continuamos superando los límites de lo que es posible con HBase en Amazon EMR.
Sobre los autores
 Vishal Chaudhary es ingeniero de explicación de software en Amazon EMR. Su experiencia es en Amazon EMR, HBase y Hive Query Engine. Su dedicación para resolver problemas del sistema distribuido es ayudar a Amazon EMR a conseguir mejoras de rendimiento más altas.
Vishal Chaudhary es ingeniero de explicación de software en Amazon EMR. Su experiencia es en Amazon EMR, HBase y Hive Query Engine. Su dedicación para resolver problemas del sistema distribuido es ayudar a Amazon EMR a conseguir mejoras de rendimiento más altas.
 Ramesh Kandasamy es regente de ingeniería en Amazon EMR. Es un amazónico de larga data dedicado a resolver problemas de sistemas distribuidos.
Ramesh Kandasamy es regente de ingeniería en Amazon EMR. Es un amazónico de larga data dedicado a resolver problemas de sistemas distribuidos.