
La entrega de la promesa de la automatización de agente en tiempo efectivo requiere una almohadilla de datos rápida, confiable y escalable. En Uipathnecesitábamos una edificación de transmisión moderna para apuntalar productos como Pedagogo y Perspectivaspermitiendo la visibilidad casi en tiempo efectivo en las métricas de automatización de agente a medida que se desarrollan. Ese alucinación nos llevó a homogeneizar el pedazo y la transmisión en Azure Databricks utilizando la transmisión estructurada Apache Spark ™, lo que permite investigación rentables de muerto latencia que admiten la toma de decisiones de agente en toda la empresa.
Este blog detalla el enfoque técnico, las compensaciones y el impacto de estas mejoras.
Con la transmisión basada en Databricks, hemos acabado la latencia de eventos a vigilancia de subinte al tiempo que entregamos edificación simplificada y escalabilidad a prueba de futuro, estableciendo el nuevo unificado para el procesamiento de datos basado en eventos en UIPath.
Por qué transmitir es importante para las ideas de Uipath Pedagogo y Uipath
En Uipath, productos como Pedagogo y Perspectivas Confíe en gran medida en datos oportunos y confiables. Pedagogo actúa como la capa de orquestación para nuestra plataforma de automatización de agente; coordinando agentes de IA, robots y humanos basados en eventos en tiempo efectivo. Ya sea que esté reaccionando a un desencadenante del sistema, ejecutando un flujo de trabajo de larga duración o incluya un paso humano en el circuito, el avezado depende de un procesamiento de señal rápido y preciso para tomar las decisiones correctas.
UIPath Insights, que impulsa el monitoreo y el investigación a través de estas automatizaciones, agrega otra capa de demanda: capturar métricas secreto y señales de comportamiento en tiempo efectivo para superficies, calcular el ROI y apoyar la detección de problemas.
La entrega de este tipo de resultados, la orquestación reactiva y la observabilidad en tiempo efectivo, requiere una edificación de tuberías de datos que no solo sea de muerto latencia, sino igualmente escalable, confiable y mantenible. Esa aprieto es lo que nos llevó a repensar nuestra edificación de transmisión en Azure Databricks.
Creación de la almohadilla de datos de transmisión
La entrega de la promesa de investigación potentes y monitoreo en tiempo efectivo requiere una almohadilla de tuberías de datos escalables y confiables. En los últimos abriles, hemos desarrollado y ampliado múltiples tuberías para confesar nuevas características del producto y contestar a los requisitos comerciales en progreso. Ahora, tenemos la oportunidad de evaluar cómo podemos optimizar estas tuberías para no solo librarse costos, sino igualmente tener una mejor escalabilidad, y al menos una seguro de entrega para confesar datos de nuevos servicios como Pedagogo.
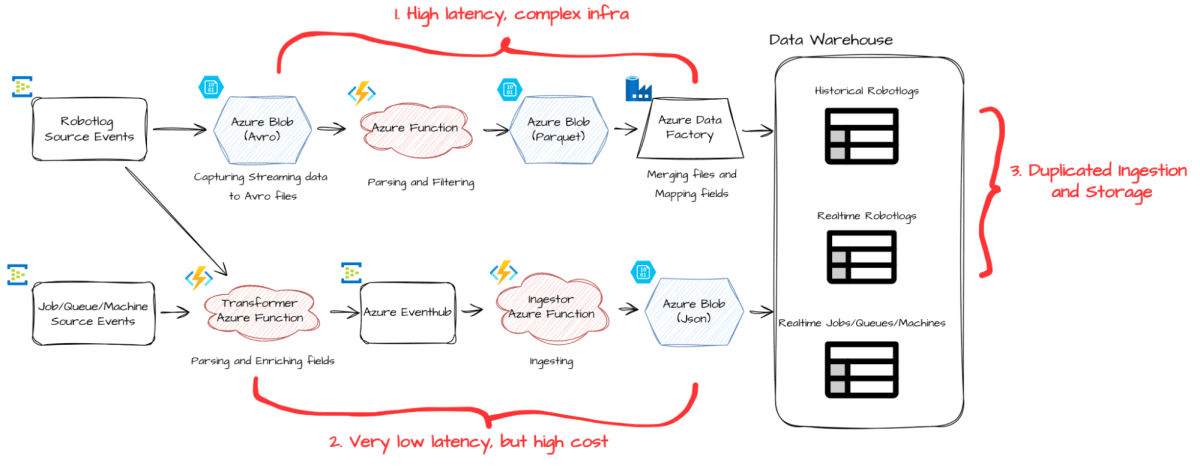
Si adecuadamente nuestra configuración preparatorio (que se muestra hacia lo alto) funcionó adecuadamente para nuestros clientes, igualmente reveló áreas de progreso:
- La tubería de lotes introdujo hasta 30 minutos de latencia y se basó en una infraestructura compleja
- La tubería en tiempo efectivo entregó datos más rápidos, pero llegó con un decano costo.
- Para los robotlogs, nuestro conjunto de datos más vasto, mantuvimos rutas de ingestión y almacenamiento separadas para el procesamiento histórico y en tiempo efectivo, lo que resultó en la duplicación y la ineficiencia.
- Para apoyar la nueva tubería ETL para UIPath Pedagogo, un nuevo producto UIPath, tendríamos que alcanzar al menos una vez que la seguro de entrega.
Para invadir estos desafíos, realizamos una importante revisión arquitectónica. Fusionamos los procesos de ingestión de lotes y en tiempo efectivo para robotlogs en una sola tubería, y rearquitamos que la tubería de ingestión en tiempo efectivo es más rentable y escalable.
¿Por qué la transmisión estructurada de chispa en Databricks?
Como nos propusimos simplificar y modernizar nuestra edificación de tuberías, necesitábamos un entorno que pudiera manejar las cargas de trabajo por lotes de parada rendimiento y los datos en tiempo efectivo de muerto latencia, sin introducir gastos operativos. La transmisión estructurada de chispa (SSS) en Azure Databricks fue un ajuste natural.
Construido sobre Spark SQL y Spark Core, la transmisión estructurada comercio los datos en tiempo efectivo como una tabla ilimitada, lo que nos permite reutilizar construcciones familiares de lotes de chispa mientras obtiene los beneficios de un motor de transmisión escalable tolerante y tolerante a fallas. Este maniquí de programación unificado redujo la complejidad y el expansión acelerado.
Ya habíamos utilizado la transmisión estructurada de chispa para desarrollar nuestra Alerta en tiempo efectivo característica, que utiliza el procesamiento de flujo de estado en Databricks. Ahora, estamos ampliando sus capacidades para construir nuestra próxima reproducción de Ingestión en tiempo efectivo tuberías, lo que nos permite alcanzar Bajo latencia, escalabilidad, rentabilidad y garantías de entrega al menos a la cima.
La próxima reproducción de ingestión en tiempo efectivo
Nuestra nueva edificación, que se muestra a continuación, simplifica dramáticamente el proceso de ingestión de datos al consolidar componentes previamente separados en una tubería unificada y escalable utilizando Spark Structure Streaming en Databricks:
En el centro de este nuevo diseño hay un conjunto de trabajos de transmisión que se leen directamente de las fuentes de eventos. Estos trabajos realizan investigación, filtrado, aplanamiento y, más críticamente, unen a cada evento con datos de narración para enriquecerlo antaño de escribir en nuestro almacén de datos.
Orquestamos estos trabajos utilizando Databricks Lakeflow Jobs, que ayuda a llevar la batuta reintentos y recuperación de empleo en caso de fallas transitorias. Esta configuración optimizada progreso tanto la productividad del desarrollador como la confiabilidad del sistema.
Los beneficios de esta nueva edificación incluyen:
- Eficiencia de rentabilidad: Ahorra engranajes al ceñir la complejidad de la infraestructura y calcular el uso
- Mengua latencia: Promedios de latencia de ingestión cerca de de un minuto, con la flexibilidad de ceñir esto aún más
- Escalabilidad a prueba de futuro: El rendimiento es proporcional al número de núcleos, y podemos prosperar infinitamente
- No hay datos perdidos: Spark hace el aumento pesado de la recuperación de fallas, apoyando al menos una vez entrega.
- Con la deduplicación del fregadero aguas debajo en el expansión futuro, podrá alcanzar Exactamente una vez entrega
- Expansión rápido ciclo gracias a la Spark DataFrame API
- Simple y unificado edificación
De muerto latencia
Nuestro trabajo de transmisión actualmente se ejecuta en modo micro-lote con un intervalo de activación de un minuto. Esto significa que desde el momento se publica un evento en nuestro autobús de eventos, generalmente aterriza en nuestro almacén de datos cerca de 27 segundos en mediana, con el 95% de los registros que llegan interiormente 51 segundosy 99% interiormente 72 segundos.
La transmisión estructurada proporciona configuraciones de activación configurables, lo que incluso podría ceñir la latencia a unos pocos segundos. Por ahora, hemos electo el disparador de un minuto como el contrapeso adecuado entre el costo y el rendimiento, con la flexibilidad de reducirlo en el futuro si los requisitos cambian.
Escalabilidad
Spark divide el trabajo de big data por particiones, que utilizan completamente los núcleos de CPU de trabajador/ejecutor. Cada trabajo de transmisión estructurado se divide en etapas, que se dividen aún más en tareas, cada una de las cuales se ejecuta en un solo núcleo. Este nivel de paralelización nos permite utilizar completamente nuestro clúster y escalera de chispa de forma capaz con los crecientes volúmenes de datos.
Gracias a optimizaciones como procesamiento en memoria, planificación de consultas de catalizador, reproducción de código de etapa completa y ejecución vectorizada, procesamos cerca de 40,000 eventos por segundo en nervio de escalabilidad. Si el tráfico aumenta, podemos prosperar simplemente aumentando los recuentos de particiones en el bus de eventos de origen y agregando más nodos de trabajadores, lo que garantiza la escalabilidad a prueba de futuro con un esfuerzo de ingeniería intrascendente.
Fianza de entrega
La transmisión estructurada de Spark proporciona una entrega exactamente una merienda de forma predeterminada, gracias a su sistema de puntos de control. Posteriormente de cada micro-lote, Spark persiste el progreso (o «época») de cada partición de origen como registros de escritura y el estado de aplicación del trabajo en la tienda estatal. En el caso de una defecto, el trabajo se reanuda desde el extremo punto de control, lo que no se pierde o se omita ningún datos.
Esto se menciona en el flamante Documento de investigación de transmisión estructurado con chispaque establece que alcanzar la entrega exactamente una vez:
- La fuente de entrada se puede repetir
- El sumidero de salida para confesar las escrituras ideMpotent
Pero igualmente hay un tercer requisito implícito que a menudo no se dice: el sistema debe poder detectar y manejar fallas con chiste.
Aquí es donde Spark funciona adecuadamente: sus robustos mecanismos de recuperación de fallas pueden detectar fallas de tareas, bloqueos de los ejecutores y problemas del conductor, y tomar automáticamente acciones correctivas como reintentos o reinicios.
Tenga en cuenta que actualmente estamos operando con al menos una vez entrega, ya que nuestro sumidero de salida aún no es idejente. Si tenemos más requisitos de entrega exactamente en el futuro, siempre que pongamos más esfuerzos de ingeniería en idempotencia, deberíamos poder lograrlo.
Los datos sin procesar son mejores
Igualmente hemos realizado algunas otras mejoras. Ahora hemos incluido y persistido un global rawMessage campo a través de todas las tablas. Esta columna almacena la carga útil del evento flamante como una condena sin procesar. Para tomar prestado el principio de sushi (aunque nos referimos a poco levemente diferente aquí): los datos sin procesar son mejores.
Los datos sin procesar simplifican significativamente la resolución de problemas. Cuando poco sale mal, como un campo faltante o un valencia inesperado, podemos referirnos instantáneamente al mensaje flamante y rastrear el problema, sin perseguir registros o sistemas ascendentes. Sin esta carga útil sin procesar, el diagnosis de los problemas de datos se vuelve mucho más difícil y más tranquilo.
La desventaja es un pequeño aumento en el almacenamiento. Pero gracias al almacenamiento en la cúmulo de ocasión y al formato columnar de nuestro almacén, esto tiene un costo intrascendente y no tiene impacto en el rendimiento de la consulta.
API simple y poderosa
La nueva implementación nos está llevando menos tiempo de expansión. Esto es en gran parte gracias a la API de DataFrame en Spark, que proporciona una contemplación declarativa de parada nivel sobre el procesamiento de datos distribuidos. En el pasado, el uso de RDDS significaba razonamiento manual sobre los planes de ejecución, la comprensión de los DAG y la optimización del orden de operaciones como uniones y filtros. Los marcos de datos nos permiten centrarnos en la razonamiento de lo que queremos calcular, en zona de cómo calcularlo. Esto simplifica significativamente el proceso de expansión.
Esto igualmente ha mejorado las operaciones. Ya no necesitamos retornar a ejecutar los trabajos fallidos manualmente o rastrear errores en múltiples componentes de la tubería. Con una edificación simplificada y menos partes móviles, tanto el expansión como la depuración son significativamente más fáciles.
Conducir investigación en tiempo efectivo en UIPath
El éxito de esta nueva edificación no ha pasado desapercibida. Se ha convertido rápidamente en el nuevo unificado para la ingestión de eventos en tiempo efectivo en UIPath. Más allá de su implementación auténtico para UIPath Pedagogo e Insights, el patrón ha sido ampliamente prohijado por múltiples equipos y proyectos nuevos para sus deyección de investigación en tiempo efectivo, incluidos aquellos que trabajan en iniciativas de vanguardia. Esta prohijamiento generalizada es un evidencia de la escalabilidad, eficiencia y extensibilidad de la edificación, lo que facilita que los nuevos equipos a lado y permitan una nueva reproducción de productos con potentes capacidades de investigación en tiempo efectivo.
Si está buscando prosperar sus cargas de trabajo analíticas en tiempo efectivo sin la carga operativa, la edificación descritas aquí ofrece una ruta probada, alimentada por Databricks y Spark Structure Streaming y directorio para confesar la próxima reproducción de sistemas de IA y agente.
Acerca de Uipath
Uipath (NYSE: PATH) es un líder mundial en la automatización de agente, lo que permite a las empresas beneficiarse todo el potencial de los agentes de IA para ejecutar y optimizar de forma autónoma y optimizar procesos comerciales complejos. El UIPath Platform ™ combina de forma única la agencia controlada, la flexibilidad del desarrollador y la integración perfecta para ayudar a las organizaciones a prosperar la automatización de agentes de forma segura y con confianza. Comprometido con la seguridad, la gobernanza y la interoperabilidad, Uipath apoya a las empresas a medida que hacen la transición a un futuro donde la automatización ofrece todo el potencial de la IA para alterar las industrias.