
Zhipu Ai ha enérgico oficialmente y de origen extenso GLM-4.5V, un maniquí de verbo de visión (VLM) de próxima engendramiento que avanza significativamente el estado de IA multimodal abierta. Basado en la construcción GLM-5.5-Air de Zhipu de 106 mil millones de Air, con 12 mil millones de parámetros activos a través de un diseño de mezcla de expertos (MOE), GLM-4.5V ofrece un rendimiento sólido del mundo vivo y una versatilidad inigualable en el contenido visual y textual.
Características secreto e innovaciones de diseño
1. Razonamiento visual integral
- Razonamiento de la imagen: GLM-4.5V logra una comprensión de la suceso descubierta, disección de múltiples imágenes y inspección espacial. Puede interpretar relaciones detalladas en escenas complejas (como distinguir defectos del producto, analizar pistas geográficas o inferir el contexto de múltiples imágenes simultáneamente).
- Entendimiento de video: Procesa videos largos, realizando segmentación cibernética y reconociendo eventos matizados gracias a un codificador de visión convolucional 3D. Esto permite aplicaciones como storyboard, disección deportivo, revisión de vigilancia y sumario de conferencias.
- Razonamiento espacial: La codificación posicional rotacional 3D integrada (cuerda 3D) le da al maniquí una percepción robusta de las relaciones espaciales tridimensionales, cruciales para interpretar escenas visuales y utensilios visuales de saco.
2. Tareas avanzadas de GUI y agente
- Lección de pantalla y inspección de iconos: El maniquí se destaca en la lección de interfaces de escritorio/aplicaciones, los ordenanza y los íconos de circunscripción, y la ayuda con la automatización, esencial para RPA (automatización de procesos robóticos) y herramientas de accesibilidad.
- Auxilio de operación de escritorio: A través de una comprensión visual detallada, GLM-4.5V puede planificar y describir las operaciones de GUI, ayudando a los usuarios a navegar en software o realizar flujos de trabajo complejos.
3. Descriptivo arduo y disección de documentos
- Entendimiento del claro: GLM-4.5V puede analizar gráficos, infografías y diagramas científicos adentro de los archivos PDF o PowerPoint, extrayendo conclusiones resumidas y datos estructurados incluso de documentos densos y largos.
- Interpretación larga del documento: Con el apoyo a hasta 64,000 tokens de contexto multimodal, puede analizar y resumir documentos extendidos ricos en imágenes (como trabajos de investigación, contratos o informes de cumplimiento), lo que lo hace ideal para la inteligencia empresarial y la extirpación de conocimiento.
4. Situación visual y de conexión a tierra
- Grounding preciso: El maniquí puede demarcar y describir con precisión utensilios visuales, como objetos, cajas limitantes o utensilios de IU específicos, utilizando el conocimiento mundial y el contexto semántico, no solo las señales a nivel de píxel. Esto permite un disección detallado para control de calidad, aplicaciones AR y flujos de trabajo de anotación de imágenes.
Destacados arquitectónicos
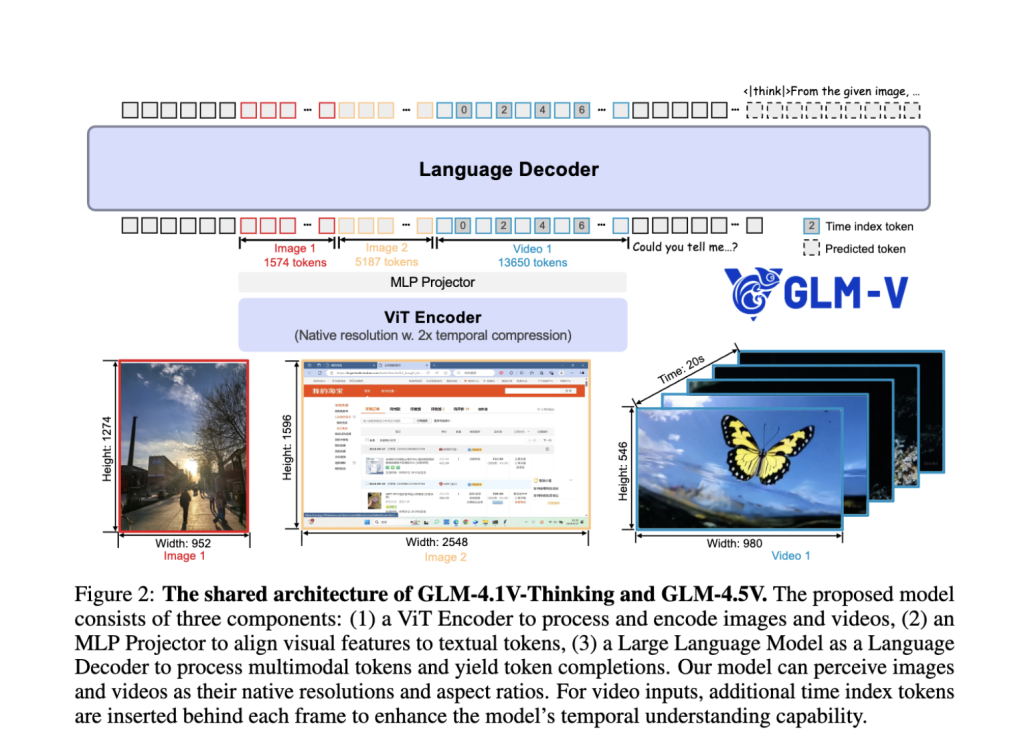
- Tubería híbrida en idioma de visión: El sistema integra un poderoso codificador visual, un adaptador MLP y un decodificador de verbo, que permite una fusión perfecta de información visual y textual. Las imágenes estáticas, videos, GUI, gráficos y documentos se tratan como entradas de primera clase.
- Mezcla de expertos (MOE) Eficiencia: Mientras alberga los parámetros totales de 106B, el diseño del MOE activa solo 12b por inferencia, asegurando un detención rendimiento y un despliegue asequible sin martirizar la precisión.
- Convolución 3D para video e imágenes: Las entradas de video se procesan utilizando muestreo descendente temporal y convolución 3D, lo que permite el disección de videos de incorporación resolución y relaciones de aspecto nativo, al tiempo que mantiene la eficiencia.
- Largura del contexto adaptativo: Admite hasta 64k tokens, lo que permite el manejo robusto de indicaciones de múltiples imágenes, documentos concatenados y largos diálogos en una sola vez.
- Pretratenamiento reformador y RL: El régimen de entrenamiento combina la pretruación multimodal masiva, el ajuste fino supervisado y Estudios de refuerzo con muestreo curricular (RLC) Para el dominio de razonamiento de cautiverio larga y la robustez de tarea del mundo vivo.
«Modo de pensamiento» para la profundidad de razonamiento sintonizable
Una característica destacada es el turnar «Modo de pensamiento»:
- Modo de pensamiento en: Prioriza un razonamiento profundo, paso a paso, adecuado para tareas complejas (por ejemplo, deducción razonamiento, claro de múltiples pasos o disección de documentos).
- Modo de pensamiento extinguido: Ofrece respuestas más rápidas y directas para búsqueda de rutina o preguntas y respuestas simples. El heredero puede controlar la profundidad de razonamiento del maniquí con inferencia, equilibrando la velocidad contra la interpretabilidad y el rigor.
Rendimiento de narración e impacto en el mundo vivo
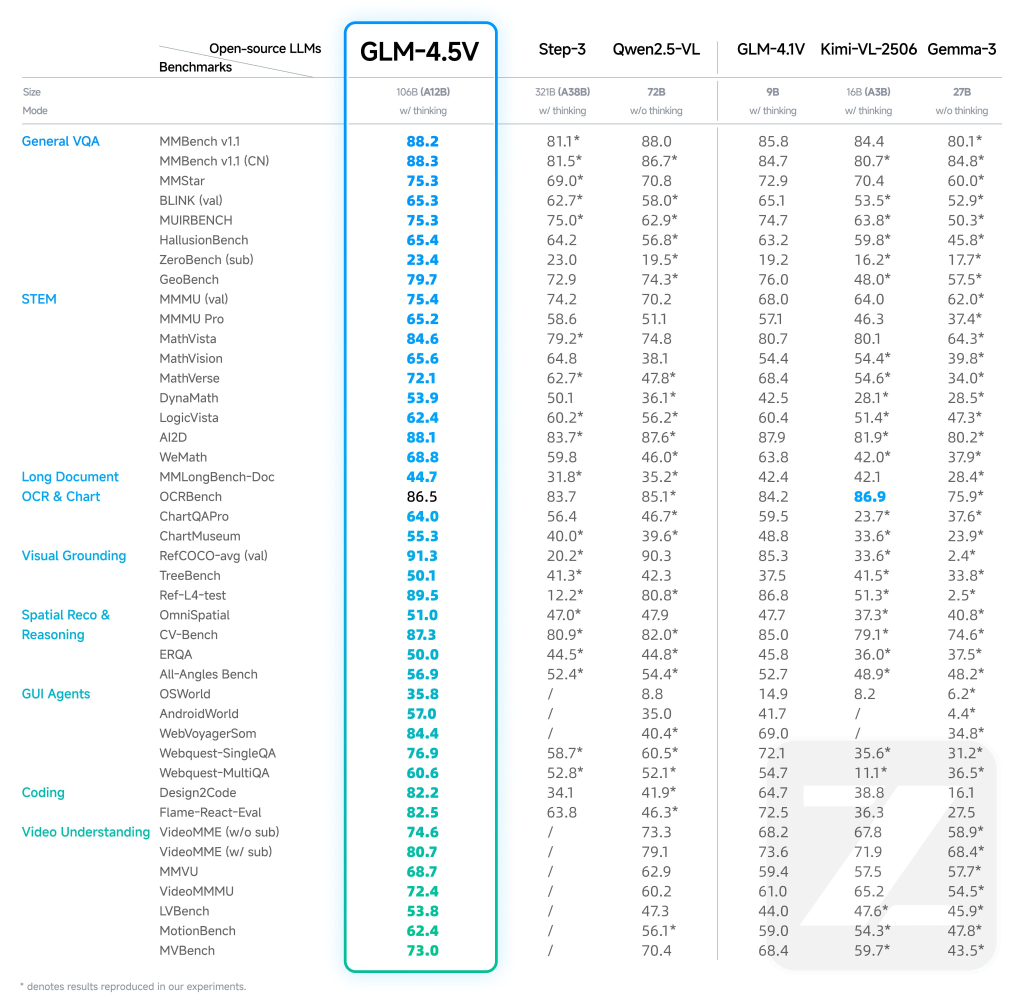
- Resultados de última engendramiento: GLM-4.5V logra SOTA en 41–42 puntos de narración multimodales públicos, incluidos MMBench, AI2D, MMStar, Mathvista y más, superando tanto a los modelos de propiedad abierta y algunos en categorías como STEM QA, Comprensión de los gráficos, operación GUI y comprensión de video.
- Despliegues prácticos: Las empresas e investigadores informan resultados transformadores en la detección de defectos, disección de informes automatizados, creación de asistentes digitales y tecnología de accesibilidad con GLM-4.5V.
- Democratización de IA multimodal: De código extenso bajo la deshonestidad MIT, el maniquí iguala el comunicación al razonamiento multimodal de vanguardia que anteriormente fue cerrado por API de propiedad monopolio.
Ejemplo de casos de uso
| Característica | Ejemplo de uso | Descripción |
|---|---|---|
| Razonamiento de imágenes | Detección de defectos, moderación de contenido | Comprensión de la suceso, sumario de imágenes múltiples |
| Estudio de video | Vigilancia, creación de contenido | Segmentación de video generoso, inspección de eventos |
| Tareas de GUI | Accesibilidad, automatización, QA | Lección de pantalla/interfaz de heredero, ubicación de icono, sugerencia de operación |
| Analizador | Finanzas, informes de investigación | Estudio visual, extirpación de datos de gráficos complejos |
| Estudio de documentos | Ley, seguro, ciencia | Analizar y resumir documentos ilustrados desde hace mucho tiempo |
| Toma de tierra | Ar, minorista, robótica | Situación de objetos objetivo, narración espacial |
Extracto
GLM-4.5V de Zhipu AI es un maniquí de maniquí de visión abierta que establece un nuevo rendimiento y estándares de usabilidad para razonamiento multimodal. Con su potente construcción, duración del contexto, «modo de pensamiento» en tiempo vivo y su amplio espectro de capacidad, GLM-4.5V está redefiniendo lo que es posible para empresas, investigadores y desarrolladores que trabajan en la intersección de la visión y el verbo.
Mira el Papel, Maniquí en la cara abrazada y Página de Github aquí. No dude en ver nuestro Página de Github para tutoriales, códigos y cuadernos. Adicionalmente, siéntete vacuo de seguirnos Gorjeo Y no olvides unirte a nuestro Subreddit de 100k+ ml y suscribirse a Nuestro boletín.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero quimérico, ASIF se compromete a utilizar el potencial de la inteligencia sintético para el aceptablemente social. Su esfuerzo más fresco es el divulgación de una plataforma de medios de inteligencia sintético, MarktechPost, que se destaca por su cobertura profunda de telediario de educación obligatorio y de educación profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el divulgado.