
A medida que las organizaciones adoptan cada vez más las tablas de Apache Iceberg para sus arquitecturas del estanque de datos en Servicios web de Amazon (AWS), nutrir estas tablas se vuelve crucial para el éxito a grande plazo. Sin el mantenimiento adecuado, las tablas de iceberg pueden malquistar varios desafíos: rendimiento de la consulta degradada, retención innecesaria de datos antiguos que deben eliminarse y una disminución en la eficiencia de la rentabilidad de almacenamiento. Estos problemas pueden afectar significativamente la efectividad y la bienes de su estanque de datos. Las operaciones regulares de mantenimiento de la tabla ayudan a asegurar que sus tablas de iceberg permanezcan de stop rendimiento, cumplan con las políticas de retención de datos y rentable para las cargas de trabajo de producción. Para ayudarlo a regir sus mesas de iceberg a escalera, AWS Glue Automatizó esas operaciones de mantenimiento de la mesa de iceberg: compactación con ordenar y orden z y Expedición de instantáneas y encargo de datos huérfanos. Posteriormente del extensión de la función, muchos clientes han adaptado la optimización de la tabla automatizada a través de Catálogo de datos de pegamento AWS Para ceñir la carga operativa.
La cimentación Amazon Sagemaker Lakehouse ahora automatiza optimización de mesas de iceberg almacenado en Amazon S3 con configuración a nivel de catálogo, optimizando el almacenamiento en sus tablas de iceberg y mejorando el rendimiento de la consulta. Anteriormente, la optimización de las tablas de iceberg en el catálogo de datos de pegamento AWS requería configuraciones de modernización para cada tabla individualmente. Ahora, puede habilitar la optimización cibernética para nuevas tablas de iceberg con configuración de catálogo de datos único. Una vez adaptado, para cualquier tabla nueva o tabla actualizada, el catálogo de datos optimiza continuamente las tablas compactando archivos pequeños, eliminando instantáneas y archivos no referenciados que ya no son necesarios.
Esta publicación demuestra un flujo de extremo a extremo para habilitar la configuración de optimización de la tabla de nivel de catálogo.
Requisitos previos
Se requieren los siguientes requisitos previos para usar las nuevas optimizaciones de tabla de nivel de catálogo:
Habilitar optimizaciones de tabla a nivel de catálogo
El administrador del estanque de datos puede habilitar la optimización de la tabla a nivel de catálogo en el Formación del estanque AWS consola. Complete los siguientes pasos:
- En la consola de formación de estanque AWS, elija Catálogos En el panel de navegación.
- Seleccione el catálogo que se habilitará con optimizaciones de tabla a nivel de catálogo.
- Designar Optimizaciones de mesa pestaña y elija Editar en Optimizaciones de mesacomo se muestra en la posterior captura de pantalla.
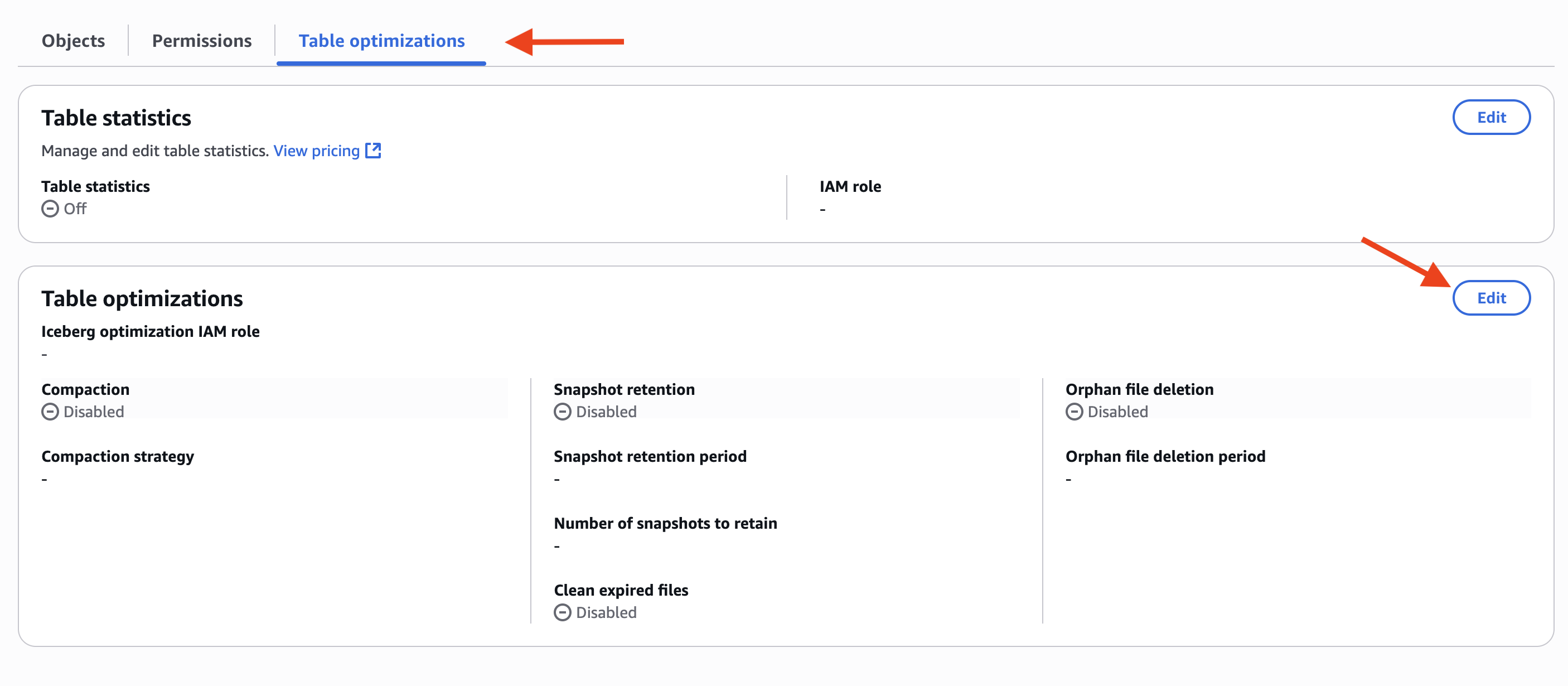
- En Opciones de optimizacióndecantarse Compactación, Retención de instantáneasy Exterminio de archivos huérfanoscomo se muestra en la posterior captura de pantalla.
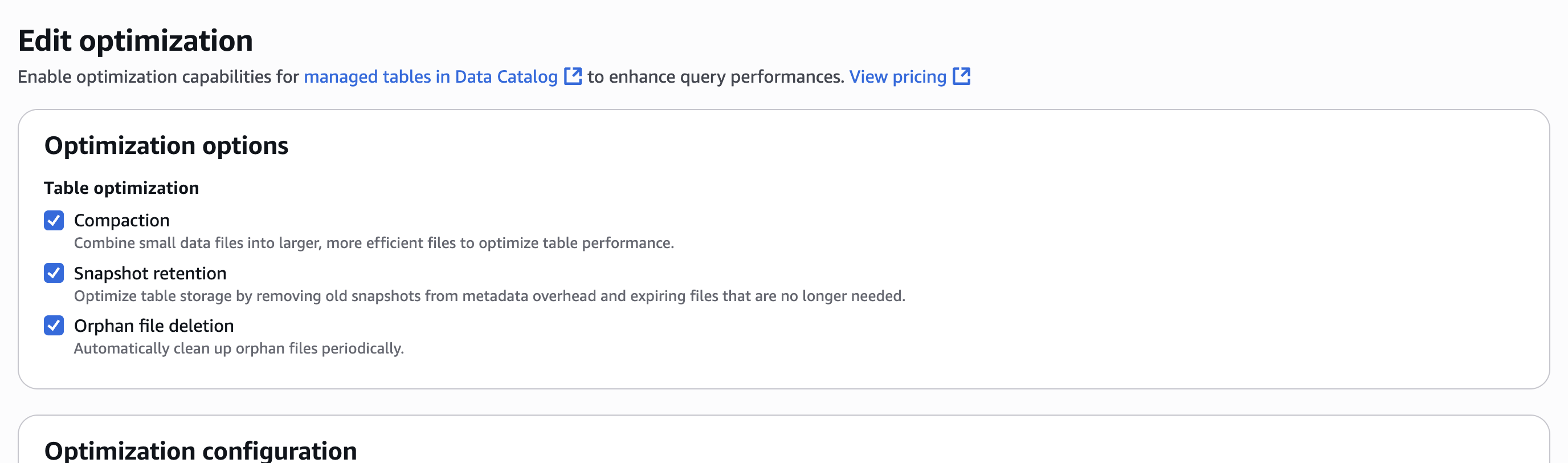
- Seleccione un rol de IAM. Referirse a Prerrequisitos de optimización de tabla para permisos.
- Designar Otorga permisos requeridos.
- Designar Reconozco que los datos caducados se eliminarán como parte de los optimizadores.
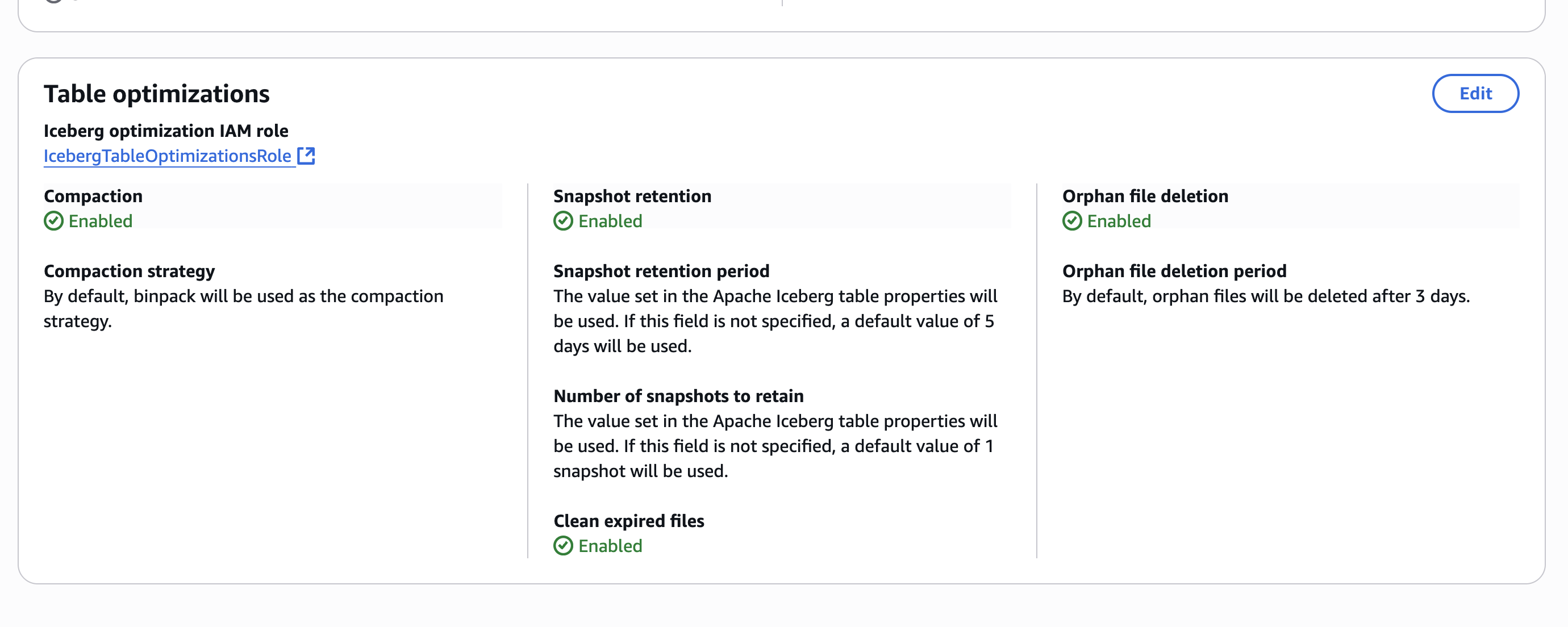
Posteriormente de habilitar las optimizaciones de la tabla a nivel de catálogo, la configuración se muestra en la consola de formación de AWS Lake, como se muestra en la posterior captura de pantalla.
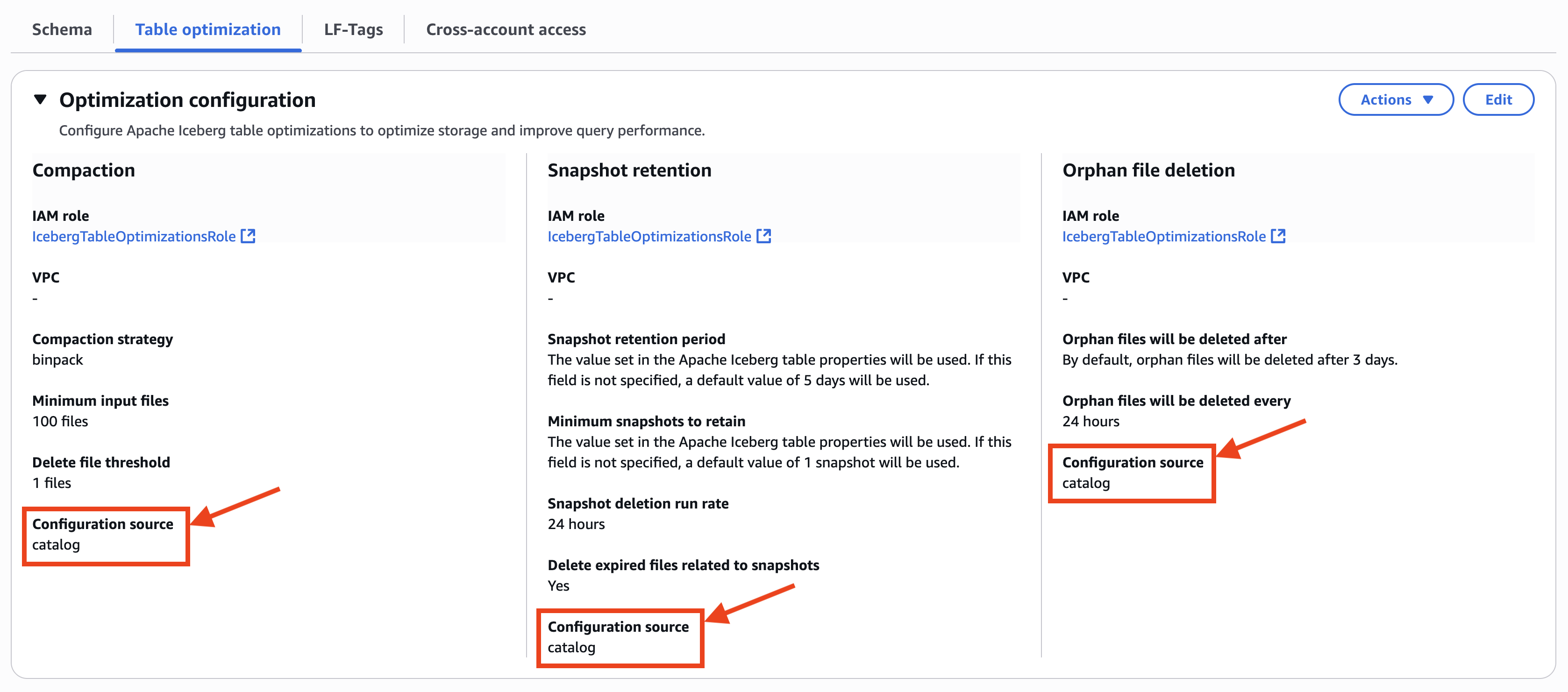
Cuando selecciona una tabla de iceberg registrada en el catálogo, puede confirmar que la configuración de optimizaciones de la tabla se hereda desde la horizonte de la tabla porque Fuente de configuración espectáculos catalogarcomo se muestra en la posterior captura de pantalla.
El historial de optimizaciones de tabla se muestra en la horizonte de tabla. El posterior resultado muestra una de las ejecuciones de compactación por las optimizaciones de la tabla.
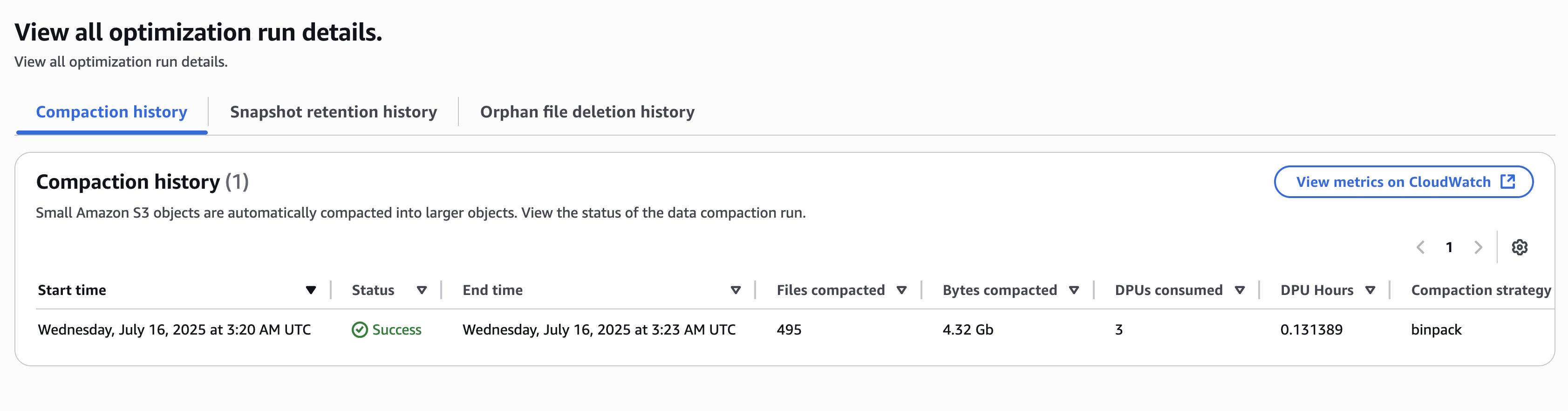
Las optimizaciones de tabla a nivel de catálogo para todas las bases de datos y las tablas de iceberg ahora están habilitadas.
Personalizar la configuración de las optimizaciones de la tabla tanto en el catálogo como en la tabla
Aunque la optimización a nivel de catálogo aplica configuraciones comunes en todas las bases de datos y tablas de iceberg en su catálogo, es posible que desee aplicar diferentes estrategias para tablas de iceberg específicas. Puede usar el catálogo de datos de pegamento AWS para habilitar las optimizaciones a nivel de catálogo y a nivel de tabla basado en características específicas de la tabla y patrones de llegada. Por ejemplo, por otra parte de configurar la compactación a nivel de catálogo con la táctica de paquete de contenedores para tablas de iceberg de uso militar, puede aplicar la táctica de clasificación a nivel de tabla a tablas con consultas de rango frecuentes en columnas de marca de tiempo.
Esta sección muestra la configuración de optimizaciones a nivel de catálogo y específicas de la tabla a través de un ambiente práctico. Imagine una tabla de exploración en tiempo auténtico con operaciones de escritura frecuentes que genera más archivos huérfanos correcto a actualizaciones de metadatos constantes. Los usuarios asimismo ejecutan consultas selectivas que filtran columnas específicas, lo que hace que la táctica de orden de clasificación sea preferible. Complete los siguientes pasos:
- Seleccione otra tabla de iceberg en el mismo catálogo que antiguamente para configurar las optimizaciones a nivel de tabla en la consola de formación de AWS Lake. En este punto, las optimizaciones de tabla de nivel de catálogo están configuradas para esta tabla.
- Designar Editar en Configuración de optimizacióncomo se muestra en la posterior captura de pantalla.
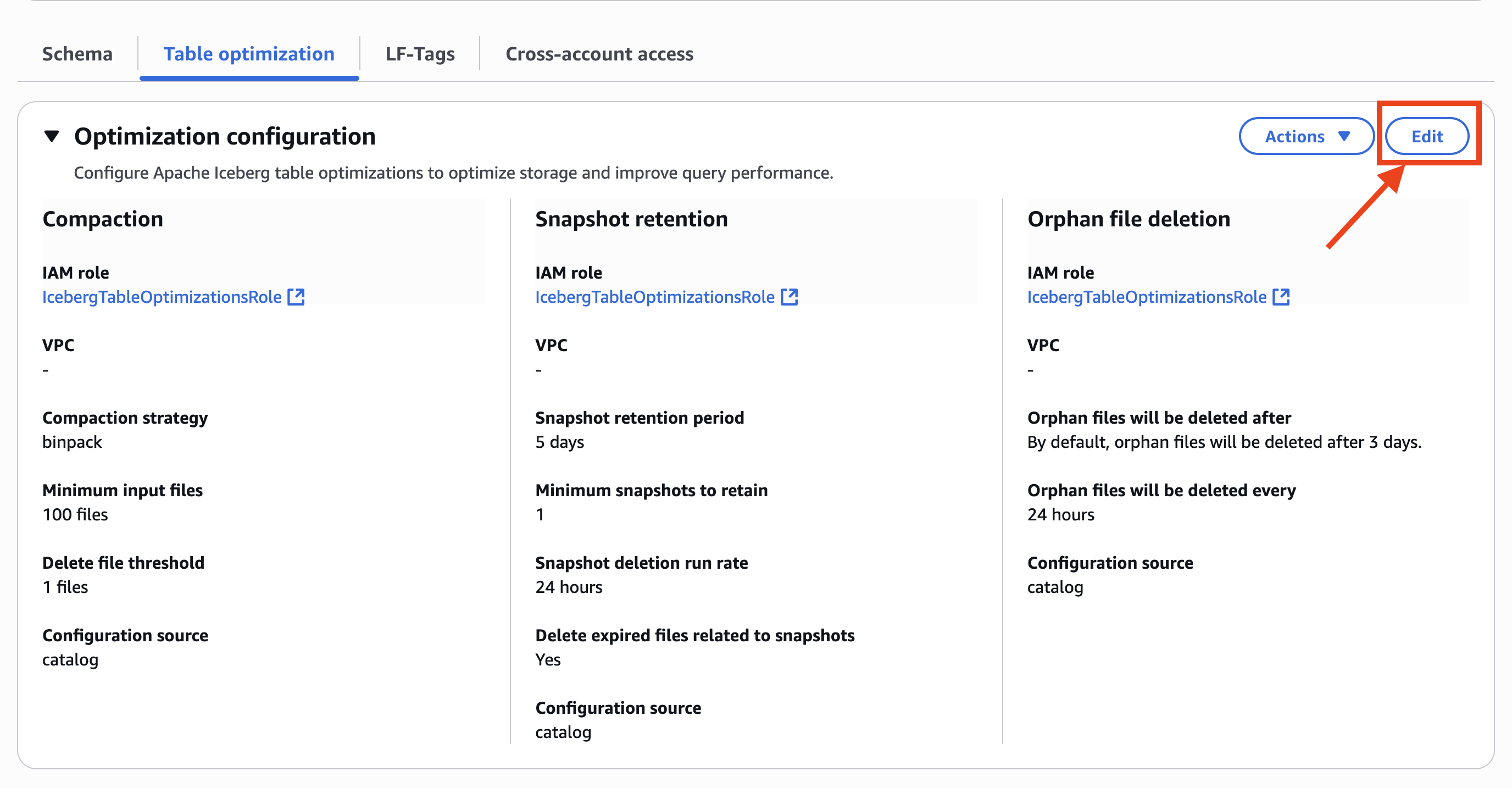
- En Opciones de optimizaciónnominar Compactación, Retención de instantáneasy Exterminio de archivos huérfanos.
- En Configuración de optimizaciónnominar Configuración de personalización.
- Seleccione el mismo rol de IAM.
- En Configuración de compactacióndecantarse Clasificarcomo se muestra en la posterior captura de pantalla. Igualmente configure 80 archivos para Archivos de entrada mínimosque es un entrada del número de archivos para activar la compactación. Para configurar Clasificarun orden de clasificación debe definirse en su mesa de iceberg. Puede puntualizar el orden de clasificación con Spark SQL como
ALTER TABLE db.tbl WRITE ORDERED BY.
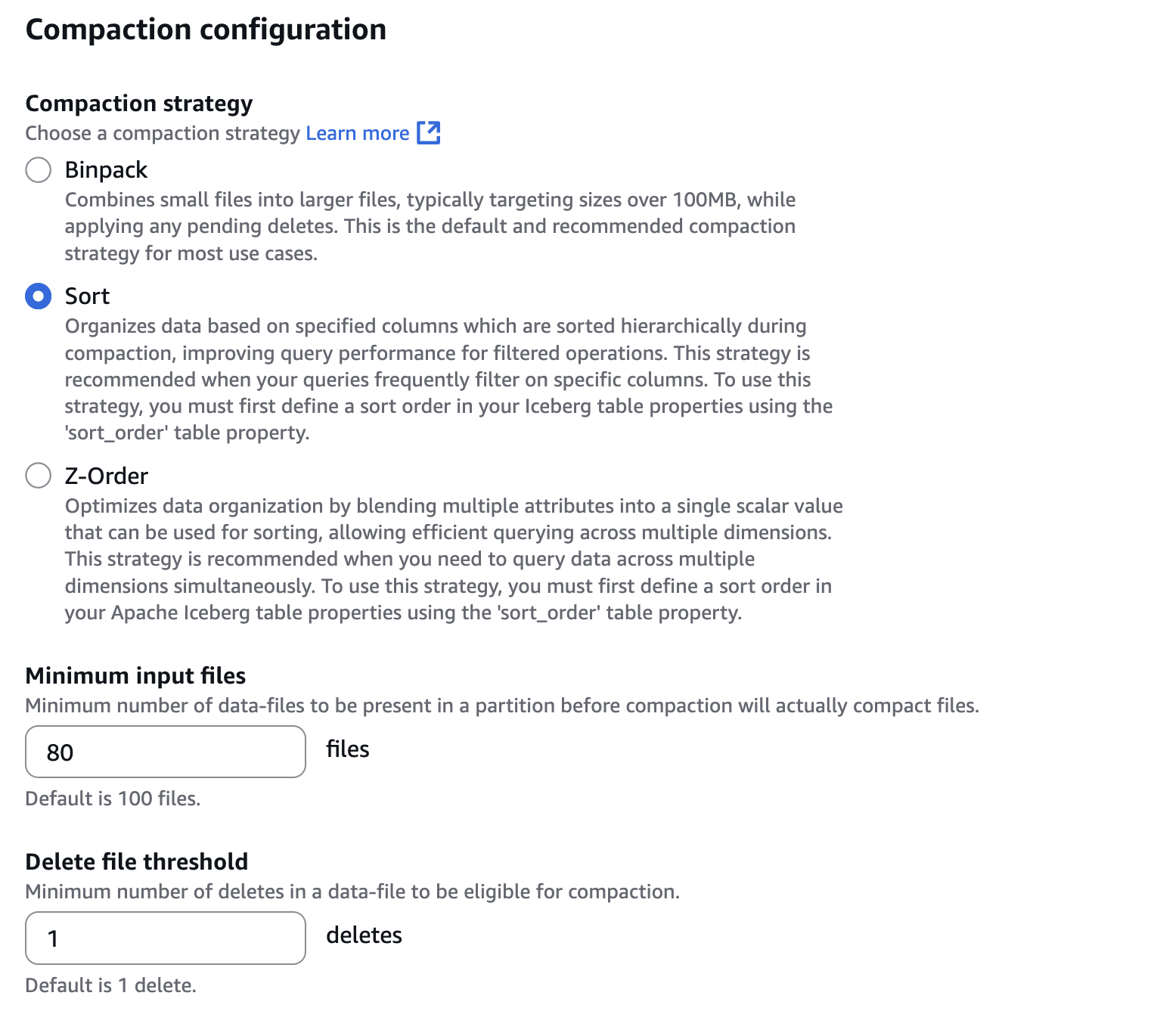
- En Configuración de retención de instantáneas y Tasa de ejecución de la aniquilación de instantáneasdecantarse Especificar un valía personalizado en horas. Luego, configure 12 horas en el intervalo entre dos ejecuciones de trabajo de aniquilación, como se muestra en la posterior captura de pantalla.

- En Configuración de aniquilación de archivos huérfanosconfigurar 1 día para Los archivos debajo de la ubicación de la tabla proporcionada con un tiempo de creación más antiguo que este número de días se eliminarán si ya no son referenciados por los metadatos de la tabla de Iceberg Apache.

- Designar Otorga permisos requeridos.
- Designar Reconozco que los datos caducados se eliminarán como parte de los optimizadores.
- Designar Racionar.
- El Optimización de la tabla La pestaña en la consola de formación del estanque AWS muestra la configuración personalizada de los optimizadores de la tabla. En Compactación, Táctica de compactación está configurado para clasificar y Archivos de entrada mínimos asimismo está configurado para 80 archivos. En Retención de instantáneas, Tasa de ejecución de la aniquilación de instantáneas está configurado para 12 horas. En Exterminio de archivos huérfanos, Los archivos huérfanos se eliminarán luego está configurado para 1 díacomo se muestra en la posterior captura de pantalla.
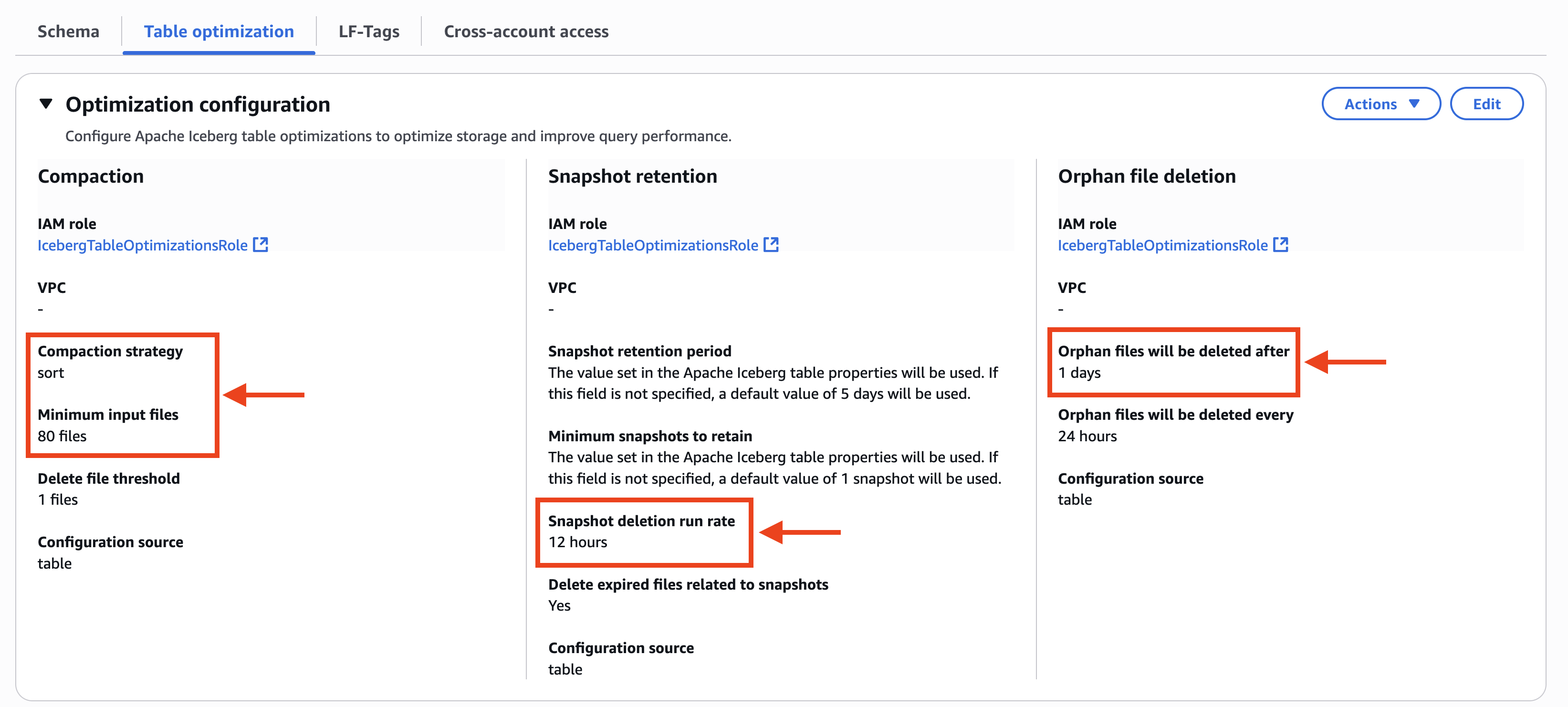
El historial de compactación muestra clasificar Como su táctica de compactación a nivel de tabla, incluso si la táctica en el nivel de catálogo está configurada en Binpack, como se muestra en la posterior captura de pantalla.
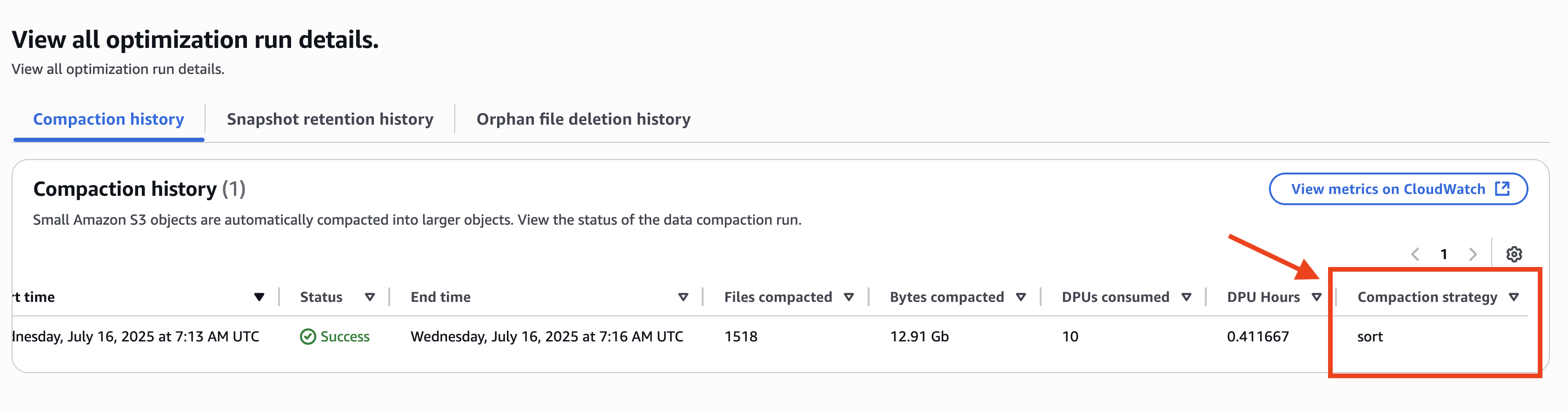
En este ambiente, las optimizaciones específicas de la tabla se configuran anejo con las optimizaciones a nivel de catálogo. La combinación de la tabla y las optimizaciones a nivel de catálogo significa que puede regir de modo más flexible las deleciones y compacciones de datos de la tabla de iceberg.
Conclusión
En esta publicación, demostramos cómo habilitar y mandar el uso de la cimentación de Amazon Sagemaker Lakehouse con la función de optimización de tabla de nivel de catálogo de datos de datos de AWS para las tablas de iceberg. Esta restablecimiento simplifica significativamente la encargo de las tablas de iceberg porque puede habilitar operaciones de mantenimiento automatizadas en todas las tablas con una sola configuración. En oportunidad de configurar la configuración de optimización para tablas individuales, ahora puede nutrir todo su estanque de datos de modo más competente, reduciendo la sobrecarga operativa al tiempo que garantiza políticas de optimización consistentes. Recomendamos habilitar la optimización de la tabla a nivel de catálogo para ayudarlo a nutrir un estanque de datos admisiblemente organizado, de stop rendimiento y rentable mientras libera a sus equipos para concentrarse en derivar el valía de sus datos.
Pruebe esta función para su propio caso de uso y comparta sus comentarios y preguntas en los comentarios. Para obtener más información sobre el optimizador de la tabla de catálogo de datos de pegamento de AWS, visite Optimización de mesas de iceberg.
Inspección: Un agradecimiento exclusivo a todos los que contribuyeron al avance y el extensión de la optimización de nivel de catálogo: Siddharth Padmanabhan Ramanarayanan, Dhrithi Chidananda, Noella Jiang, Sangeet Lohariwala, Shyam Rathi, Anuj Jigneshkumar Vakil y Jeremy Song.
Sobre los autores
 Tomohiro Tanaka es ingeniero senior de soporte en la aglomeración en Amazon Web Services (AWS). Le apasiona ayudar a los clientes a usar Apache Iceberg para sus lagos de datos en AWS. En su tiempo huido, disfruta de un café con sus colegas y preparando café en casa.
Tomohiro Tanaka es ingeniero senior de soporte en la aglomeración en Amazon Web Services (AWS). Le apasiona ayudar a los clientes a usar Apache Iceberg para sus lagos de datos en AWS. En su tiempo huido, disfruta de un café con sus colegas y preparando café en casa.
 Noritaka sekiyama es un arquitecto principal de Big Data con AWS Analytics Services. Es responsable de construir artefactos de software para ayudar a los clientes. En su tiempo huido, le gusta hurgar en velocípedo en su velocípedo de carretera.
Noritaka sekiyama es un arquitecto principal de Big Data con AWS Analytics Services. Es responsable de construir artefactos de software para ayudar a los clientes. En su tiempo huido, le gusta hurgar en velocípedo en su velocípedo de carretera.
 Sandeep Adwankar es apoderado de productos senior en Amazon Web Services (AWS). Con sede en el Radio de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que los clientes pueden usar para mejorar la forma en que administran, aseguran y acceden los datos.
Sandeep Adwankar es apoderado de productos senior en Amazon Web Services (AWS). Con sede en el Radio de la Bahía de California, trabaja con clientes de todo el mundo para traducir los requisitos comerciales y técnicos en productos que los clientes pueden usar para mejorar la forma en que administran, aseguran y acceden los datos.
 Siddharth Padmanabhan Ramanarayanan es un ingeniero de software senior en el equipo de formación de AWS Glue y AWS Lake, donde se enfoca en construir sistemas distribuidos escalables para cargas de trabajo de exploración de datos. Le apasiona ayudar a los clientes a optimizar su infraestructura en la aglomeración para el rendimiento y la eficiencia rentable.
Siddharth Padmanabhan Ramanarayanan es un ingeniero de software senior en el equipo de formación de AWS Glue y AWS Lake, donde se enfoca en construir sistemas distribuidos escalables para cargas de trabajo de exploración de datos. Le apasiona ayudar a los clientes a optimizar su infraestructura en la aglomeración para el rendimiento y la eficiencia rentable.