
Las tuberías declarativas del charca ahora están generalmente disponibles, y el impulso no se ha ralentizado desde Dais. Esta publicación redondea todo lo que ha aterrizado en las últimas semanas, por lo que está completamente atrapado en lo que está aquí, lo que viene posteriormente y cómo comenzar a usarlo.
Dais 2025 en revisión: las tuberías declarativas del charca
En Data + AI Summit 2025, anunciamos que hemos contribuido con nuestra tecnología de tubería declarativa central al esquema Apache Spark ™ como Spark Declarative Pipelines. Esta contribución extiende el maniquí declarativo de Spark de consultas individuales a tuberías completas, permitiendo que los desarrolladores definan qué deberían hacer sus tuberías mientras Spark maneja cómo hacerlo. Ya probado en miles de cargas de trabajo de producción, ahora es un en serie despejado para toda la comunidad Spark.
Todavía anunciamos la disponibilidad normal del charcaLa alternativa unificada de Databricks para la ingestión de datos, la transformación y la orquestación en la plataforma de inteligencia de datos. El hito de GA asimismo marcó una crecimiento importante para el progreso de la tubería. DLT ahora es el charca del charca, las tuberías declarativascon los mismos beneficios centrales y la compatibilidad completa con sus tuberías existentes. Todavía introdujimos el charca del charca del charca IDE para ingeniería de datos (que se muestra en lo alto), construido desde cero hasta apresurar el progreso de la tubería con características como emparejamiento de código de código, vistas previas contextuales y autorización asistida por AI-AI.
Finalmente, anunciamos Diseñador del charcauna experiencia sin código para construir tuberías de datos. Hace que ETL sea accesible para más usuarios, sin comprometer la preparación de la producción o la gobernanza, generando tuberías reales de flujo del charca debajo del capó. Paisaje previa próximamente.
Juntos, estos anuncios representan un nuevo capítulo en ingeniería de datos: simplificador, más escalable y más despejado. Y en las semanas posteriores a Dais, hemos mantenido el impulso.
Rendimiento más inteligente, costos más bajos para tuberías declarativas
Hemos realizado mejoras significativas en el backend para ayudar a las tuberías declarativas de los charca del charca que funcionan más rápido y de forma más rentable. En todos los ámbitos, las tuberías sin servidor ahora ofrecen un mejor rendimiento de precio gracias a las mejoras de los motores a fotones, enzimas, autoscalización y características avanzadas como Autocdc y Expectativas de calidad de datos.
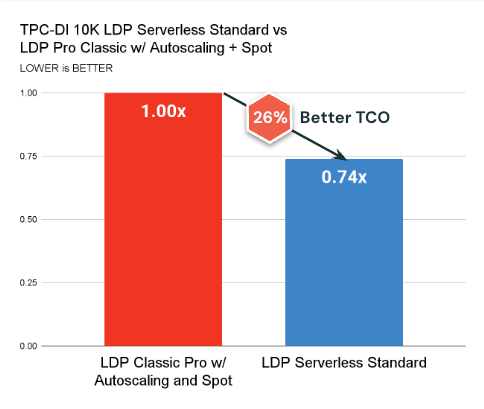
Aquí están las conclusiones secreto:
- Sin servidor Modo en serie ahora está habitable y supera constantemente el calculador clásico en términos de costo (26% mejor TCO en promedio) y latencia.
- Sin servidor Modo de rendimiento Desbloquea resultados aún más rápidos y es competitivo para SLAS ajustados.
- Autocdc Ahora supera la fusión tradicional en muchas cargas de trabajo, al tiempo que facilita la implementación de patrones SCD1 y SCD2 sin deducción compleja, especialmente cuando se combina con estas optimizaciones.
Estos cambios se basan en nuestro compromiso continuo de hacer que las tuberías declarativas de la charca del charca sean la opción más eficaz para la producción ETL a escalera.
¿Qué más hay de nuevo en tuberías declarativas?
Desde la cumbre Data + AI, hemos entregado una serie de actualizaciones que hacen que las tuberías sean más modulares, listas para la producción y más fáciles de proceder, sin requerir configuración adicional o código de pegamento.
Simplicidad operacional
La diligencia de la vitalidad de la tabla ahora es más obvio y rentable:
- Optimización predictiva Ahora administra el mantenimiento de la tabla, como optimizar y vano, para todas las tuberías de catálogo de Unity New y existentes. En ocasión de ejecutarse en un horario fijo, el mantenimiento ahora se adapta a los patrones de carga de trabajo y al diseño de datos para optimizar el costo y el rendimiento automáticamente. Esto significa:
- Menos tiempo dedicado a ajustar o programar mantenimiento manualmente
- Ejecución más inteligente que evita el uso innecesario de enumeración
- Mejores tamaños de archivo y clúster para un rendimiento de consulta más rápido
- Vectores de asesinato ahora están habilitados de forma predeterminada para nuevas tablas de transmisión y vistas materializadas. Esto reduce las reescrituras innecesarias, mejorando el rendimiento y la reducción de los costos de cálculo al evitar las reescrituras completas de los archivos durante las actualizaciones y las eliminaciones. Si tiene requisitos estrictos de asesinato física (por ejemplo, para GDPR), puede Desactivar vectores de asesinato o eliminar los datos permanentemente.
Tuberías más modulares y flexibles
Las nuevas capacidades brindan a los equipos una veterano flexibilidad en cómo estructuran y administran tuberías, todas sin ningún reprocesamiento de datos:
- Las tuberías declarativas de lakeflow ahora admiten la puesta al día de las tuberías existentes para beneficiarse Transmitir tablas para múltiples catálogos y esquemas. Anteriormente, esta flexibilidad solo estaba habitable al crear una nueva tubería. Ahora, puede portar una tubería existente a este maniquí sin falta de reconstruirla desde cero, permitiendo arquitecturas de datos más modulares con el tiempo.
- Ahora puedes Mover tablas de transmisión y vistas materializadas de una tubería a otra usando un solo comando SQL y un pequeño cambio de código para mover la definición de la tabla. Esto facilita la división de tuberías grandes, consolidar las más pequeñas o adoptar diferentes horarios de puesta al día en todas las tablas sin falta de alegrar datos o deducción. Para reasignar una tabla a una tubería diferente, simplemente ejecute:
A posteriori de ejecutar el comando y mover la definición de la tabla de la fuente a la tubería de destino, la tubería de destino toma actualizaciones de la tabla.
Nuevas tablas de sistema para la observabilidad de la tubería
Una nueva tubería mesa del sistema ahora está en una sagacidad previa pública, que le brinda una sagacidad completa y consultable de todas las tuberías en su espacio de trabajo. Incluye metadatos como creadores, etiquetas y eventos de ciclo de vida (como deleciones o cambios de configuración), y se puede unir registros de facturación para la atribución de costos e informes. Esto es especialmente útil para equipos que administran muchas tuberías y buscan rastrear el costo en entornos o unidades de negocios.
Se planea una segunda tabla del sistema para actualizaciones de tuberías, que cubren el historial de puesta al día, el rendimiento y las fallas, para finales de este verano.
Contáctate con el charca del charca
 ¿Nuevo en Lakeflow o buscando profundizar tus habilidades? Hemos emprendedor tres cursos de capacitación gratuitos para ayudarlo a comenzar:
¿Nuevo en Lakeflow o buscando profundizar tus habilidades? Hemos emprendedor tres cursos de capacitación gratuitos para ayudarlo a comenzar:
- Ingestión de datos con Lakeflow Connect -Aprenda a ingerir datos en Databricks desde el almacenamiento en la abundancia o usar conectores sin código y totalmente administrados.
- Desplegar cargas de trabajo con trabajos del charca -Orchestre las cargas de trabajo de producción con observabilidad y automatización incorporadas.
- Construir tuberías de datos con tuberías declarativas del charca -Vaya de extremo a extremo con el progreso de la tubería, incluida la transmisión, la calidad de los datos y la publicación.
Los tres cursos están disponibles ahora sin costo en Institución de Databricks.