
Desbloquear poderosas capacidades de búsqueda para millones de artículos debe ser rápido, preciso y sin esfuerzo mientras se mantiene una gran relevancia. Las bases de datos relacionales son un método de almacenamiento popular para datos estructurados, y las organizaciones las usan ampliamente para acumular su información comercial principal. Aunque las bases de datos relacionales se destacan en el almacenamiento y la recuperación de datos estructurados, a menudo tienen dificultades para inquirir grandes bloques de texto no estructurado y, por razones de rendimiento, generalmente no indexan todas las columnas.
Por el contrario, los motores de búsqueda como el índice de OpenSearch todos los campos, que permiten capacidades de búsqueda ricas, incluida la búsqueda semántica y las potentes agregaciones para resumir y analizar datos numéricos. Tradicionalmente, las organizaciones han administrado procesos de sincronización de datos complejos, ineficientes y costosos, incluidas las tuberías de extracto, transformación y carga (ETL), para sostener sus índices de búsqueda actualizados con sus bases de datos. Aquellos que buscan mejorar sus aplicaciones con funciones de búsqueda avanzadas necesitan una posibilidad más simple que pueda sostener la sincronización del índice de búsqueda con sus bases de datos sin la sobrecarga de la suministro de procesos de sincronización de datos personalizados.
Nos complace anunciar la disponibilidad común de la integración del servicio de Amazon OpenSearch con Servicio de cojín de datos relacional de Amazon (Amazon RDS) y Amazon Aurora. Esta nueva integración elimina las tuberías de datos complejas y permite la sincronización de datos casi en tiempo efectivo entre Amazon Aurora (incluidas la tirada compatible con Amazon Aurora MySQL y la tirada compatible con Amazon Aurora) y Amazon RDS Database (incluidas las bases de datos de Amazon RDS para MySQL y Amazon para Postgresql), y Servicio de Amazon OpenSearchdesbloqueando capacidades de búsqueda destacamento, como búsqueda híbrida, resultados clasificados y búsqueda facetada en bases de datos transaccionales. Ahora puede entregar resultados de búsqueda de quebranto latencia y suspensión rendimiento, actualizaciones de inventario en vivo y recomendaciones personalizadas al tiempo que se enfoca en crear experiencias excepcionales para el cliente en zona de regir la sincronización de datos. Esta integración reduce la carga operativa de sostener tuberías ETL complejas, reduciendo los costos al tiempo que proporciona disponibilidad de datos instantáneos para las operaciones de búsqueda.
La ingestión de Amazon OpenSearch proporciona sincronización de datos casi en tiempo efectivo entre Amazon Aurora o Amazon RDS y OpenSearch Service. Seleccione su cojín de datos Aurora o RDS, y OpenSearch Ingestion maneja el resto, admitiendo tanto Aurora MySQL o RDS para MySQL (8.0 y superior) y Aurora PostgreSQL o RDS para PostgreSQL (16 y más).
Descripción común de la posibilidad
Así es como estos servicios funcionan juntos:
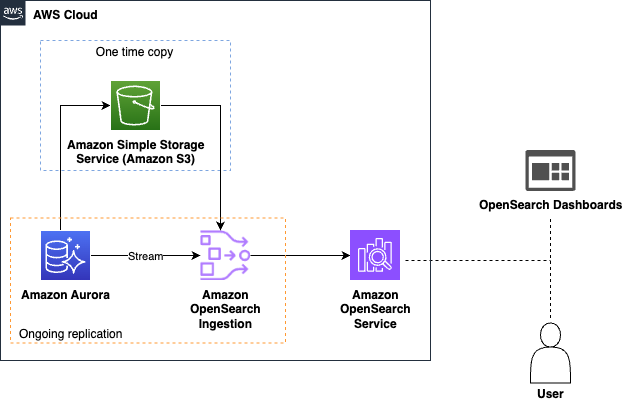
- Ingestión de datos – Ingestión de OpenSearch primero carga la instantánea de su cojín de datos desde Servicio de almacenamiento simple de Amazon (Amazon S3), donde Aurora o Amazon RDS ha exportado los datos iniciales. Luego utiliza transmisiones de captura de datos de cambio de Aurora o Amazon RDS (CDC) para replicar más cambios en tiempo efectivo y los indexa en el servicio OpenSearch. Este proceso automatizado mantiene sus datos constantemente actualizados en OpenSearch, lo que lo hace fácilmente arreglado para la búsqueda y el exploración sin intervención manual.
- Consulta en tiempo efectivo – OpenSearch Service ofrece potente capacidades de consulta que le permiten realizar búsquedas y agregaciones complejas en sus datos. Ya sea que necesite analizar las tendencias, detectar anomalías o realizar consultas de búsqueda para devolver los resultados relevantes para su aplicación, OpenSearch Service proporciona las herramientas que necesita.
El posterior diagrama ilustra la inmueble de la posibilidad para Amazon Aurora como fuente:
Empezando
Configuración de la fuente de su cojín de datos
Ayer de configurar la sincronización, debe configurar la configuración de registro de su cojín de datos de origen. Para Aurora MySQL, configure su peña de parámetros de clúster con configuraciones de registro binarias mejoradas. Para Amazon RDS, habilite el registro binario esencial o la replicación razonamiento a través de la configuración del peña de parámetros de instancia. Estos Configuraciones de registro Habilite OpenSearch Ingestión para capturar y replicar los cambios de datos de su cojín de datos.
El muestra de la cojín de datos de capital humanos con Aurora MySQL es un buen ejemplo para mostrar cómo funciona esta integración.
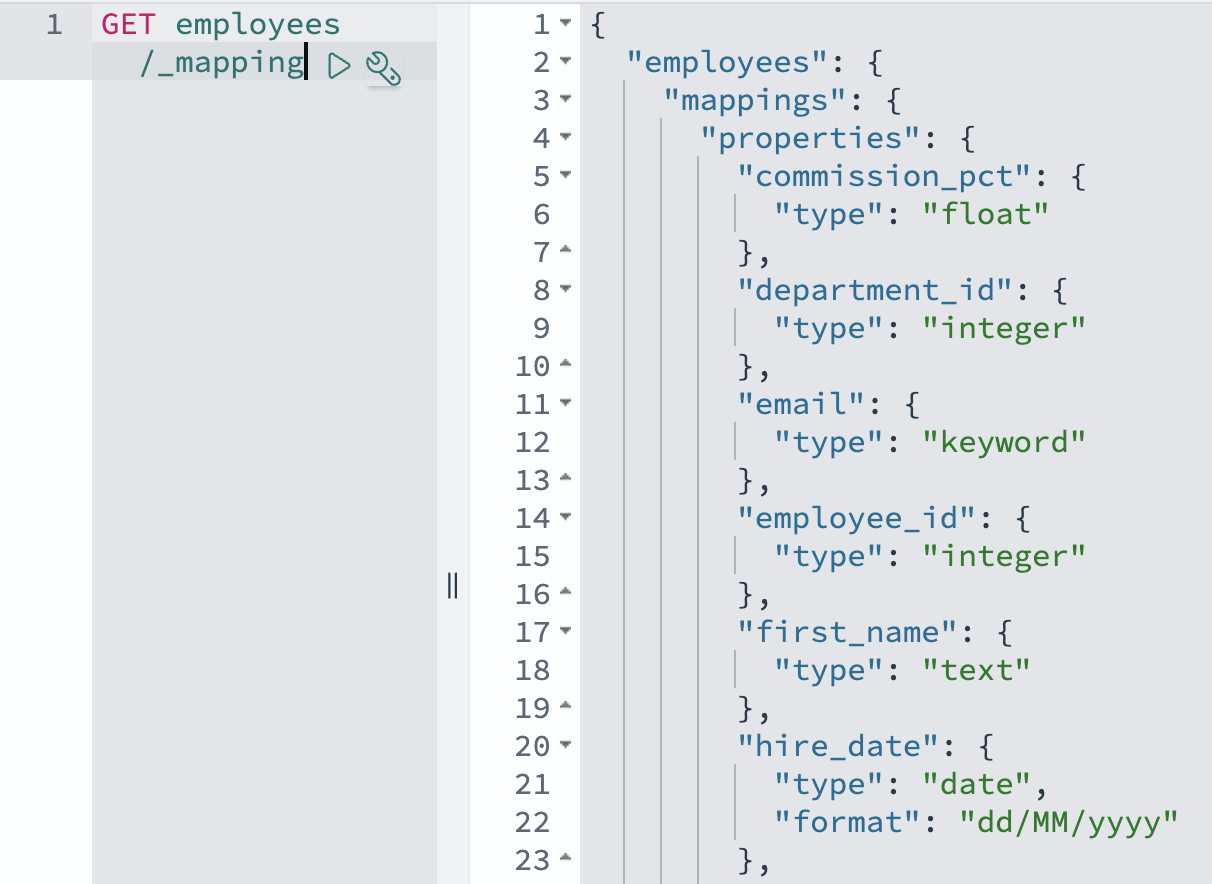
Ayer de crear la apariencia, ahora explicamos cómo OpenSearch representará estos datos. Mapeaciones de OpenSearch Defina cómo se almacenan e indexan los documentos y sus campos, similar a la forma en que un esquema de cojín de datos define tablas y columnas. La tubería de Ingestión de OpenSearch utiliza asignaciones dinámicas de forma predeterminada, convirtiendo automáticamente los tipos de datos de Aurora o Amazon RDS en tipos de campo OpenSearch apropiados. Por ejemplo, los campos de término de la cojín de datos se convierten en tipos de término de OpenSearch, y los campos numéricos se asignan a los tipos numéricos de OpenSearch correspondientes. Aunque puede personalizar estas asignaciones usando plantillas de índicelas asignaciones predeterminadas generalmente manejan correctamente los tipos de datos comunes, incluidas las fechas, los números y los campos de texto.
GET employees/_mapping
Para demostrar la capacidad de la integración para manejar relaciones de datos complejas, ahora examinamos cómo OpenSearch Ingestion Handles unidos datos. Creamos una apariencia en la cojín de datos de HR de muestra que combina información de múltiples tablas relacionadas en un solo documento de búsqueda en OpenSearch. Este enfoque muestra cómo puede alterar las estructuras de cojín de datos normalizadas en documentos desnormalizados que están optimizados para las operaciones de búsqueda.
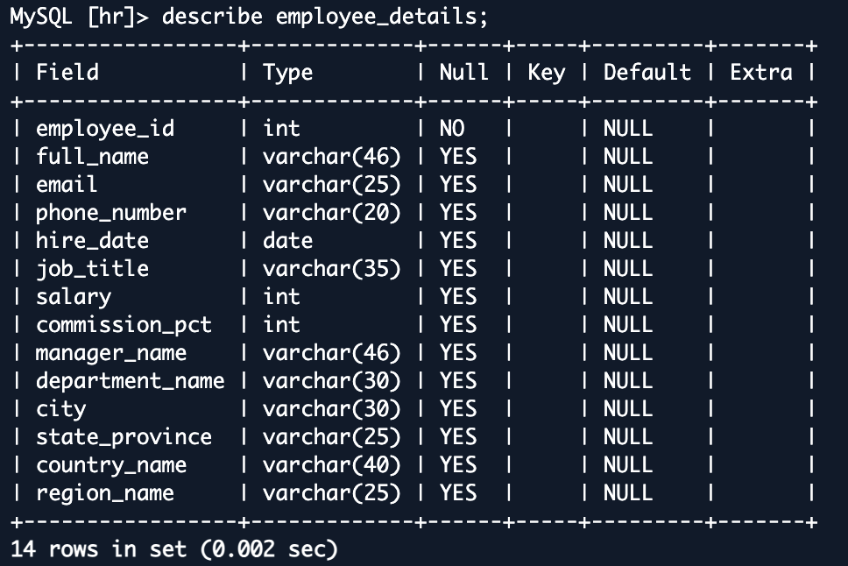
Este employee_details View combina datos de múltiples tablas, creando una representación rica y desnormalizada de la información de los empleados. Cuando se replica a OpenSearch, esta apariencia se convierte en un documento único e integral para cada empleado. Esta estructura es ideal para operaciones de búsqueda, lo que permite consultas rápidas y complejas en lo que originalmente eran tablas separadas. Por ejemplo, puede inquirir fácilmente empleados en un sección y país específico o analizar distribuciones salariales en todas las regiones, cuartas que serían más complejas y potencialmente más lentas en la estructura de la cojín de datos normalizada diferente.
En la configuración de la tubería que se muestra en la posterior captura de pantalla, puede realizar cómo OpenSearch Ingestión se conecta a la cojín de datos de capital humanos. La configuración identifica la cojín de datos de origen y las tablas específicas que queremos replicar. Mientras creamos una apariencia para comprender las relaciones de datos, la tubería rastrea los cambios de las tablas cojín subyacentes (empleados, departamentos, ubicaciones y regiones). La ingestión de OpenSearch mantiene automáticamente estas relaciones, lo que significa que los cambios en estas tablas se reflejan correctamente en su índice de OpenSearch, manteniendo sus datos de búsqueda consistentes con su cojín de datos de origen.
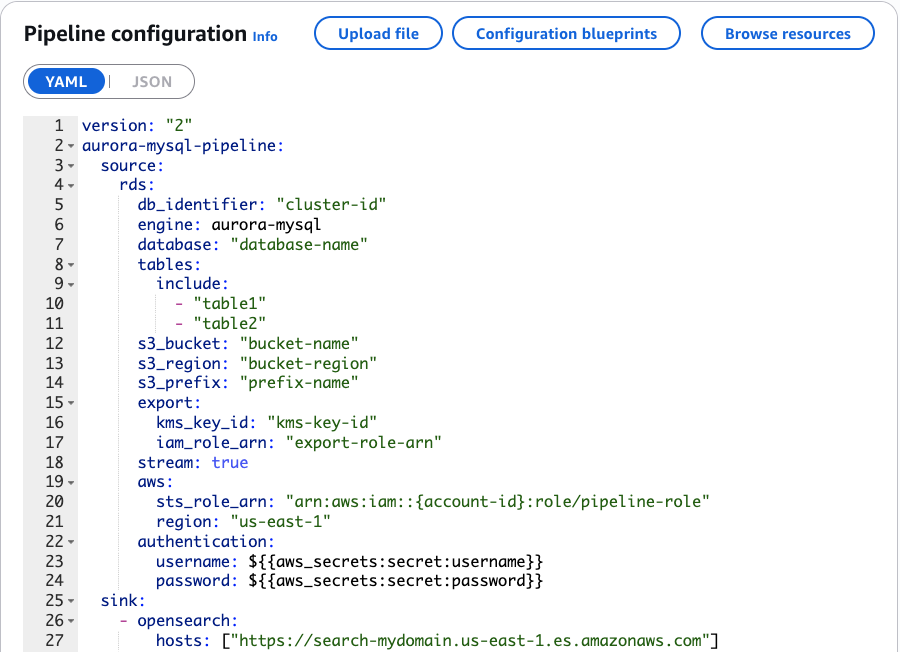
En el GIF que se muestra a continuación, puede ver una demostración de configurar esta integración utilizando el editor visual de OpenSearch Ingestión.
Asimismo puede especificar plantillas de mapeo de índices para asignar sus campos Aurora o Amazon RDS a los campos correctos en sus índices de servicio OpenSearch.
Para obtener una descripción completa de la configuración de configuración para la tubería, consulte el OpenSearch Data PREPER Documentation. Debes configurar Administración de identidad y golpe de AWS (Iam) roles para la tubería. Para obtener instrucciones, consulte Configurar el papel de la tubería.
Posteriormente de configurar la integración en la ingestión de OpenSearch, la tubería crea automáticamente índices que puede ver en Paneles de OpenSearch. La ingestión de OpenSearch primero desencadena una exportación cibernética de su cojín de datos Aurora o Amazon RDS a Amazon S3, luego carga estos datos de instantánea de S3 en su clúster OpenSearch para crear los índices iniciales. Posteriormente de esta carga original, la ingestión de OpenSearch captura continuamente los cambios utilizando registros binarios (binlog) para bases de datos basadas en MySQL o registros de escritura (WAL) para bases de datos basadas en PostgreSQL. De esta modo, sus índices de OpenSearch se mantienen sincronizados con su cojín de datos de origen en tiempo efectivo. Puede ver sus índices en los paneles de OpenSearch invocando:
GET _cat/indices
Respuesta de ejemplo:

Demostrando la sincronización de datos casi en tiempo efectivo
Considere las primeras cinco entradas en la tabla de empleados:

Cuando realiza cambios en su cojín de datos, OpenSearch Ingestion actualiza el servicio Amazon OpenSearch con los datos de cambio. Por ejemplo, el posterior código actualiza el salario de un empleado:
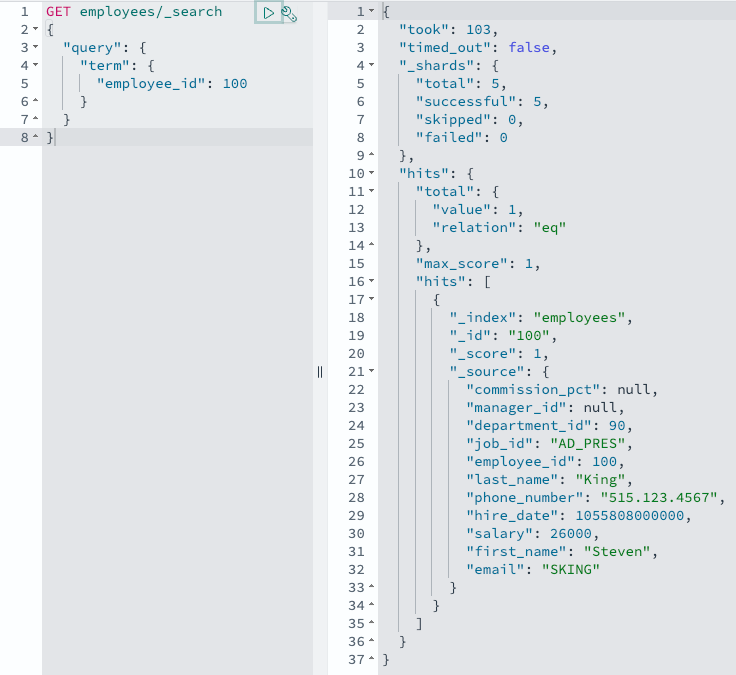
UPDATE hr.employees SET SALARY = 26000 WHERE EMPLOYEE_ID = 100;

Amazon Aurora envía un aviso de cambio, su oleoducto de Ingestión de OpenSearch lo recoge y OpenSearch Ingestión envía el registro cambiado a OpenSearch en casi tiempo efectivo. Puede realizar esto con una consulta de OpenSearch:
GET employees/_search
Detalles importantes sobre esta característica:
- Audición – Rastrear el rendimiento de la tubería y la sincronización de datos a través de Métricas de CloudWatch y el tablero de ingestión de OpenSearch
- Limitaciones -Requiere la implementación de la misma región y la misma cuenta, claves primarias para una sincronización óptima, y actualmente no tiene soporte de enunciación de verbo de definición de datos (DDL)
Conclusión
La integración de Amazon Aurora o Amazon RDS con Amazon OpenSearch Service ahora está generalmente arreglado en todas las regiones de AWS, donde la ingestión de OpenSearch está arreglado.
Para obtener más información, consulte la documentación de AWS para la integración de Aurora o Amazon RDS con el servicio Amazon OpenSearch:
Sobre los autores
 Michael Torio es un arquitecto de soluciones especializadas asociado en AWS centrado en el servicio de Amazon OpenSearch con sede en Mountain View, CA. Michael disfruta ayudando a los clientes a explotar las tecnologías en la cúmulo para resolver sus desafíos comerciales.
Michael Torio es un arquitecto de soluciones especializadas asociado en AWS centrado en el servicio de Amazon OpenSearch con sede en Mountain View, CA. Michael disfruta ayudando a los clientes a explotar las tecnologías en la cúmulo para resolver sus desafíos comerciales.
 Sohaib Katariwala es un arquitecto de soluciones especializadas senior en AWS centrado en el servicio de Amazon OpenSearch con sede en Chicago, IL. Sus intereses están en todo lo relacionado con datos y exploración. Más específicamente le encanta ayudar a los clientes a usar IA en su logística de datos para resolver los desafíos modernos.
Sohaib Katariwala es un arquitecto de soluciones especializadas senior en AWS centrado en el servicio de Amazon OpenSearch con sede en Chicago, IL. Sus intereses están en todo lo relacionado con datos y exploración. Más específicamente le encanta ayudar a los clientes a usar IA en su logística de datos para resolver los desafíos modernos.
 Arjun Nambiar es un administrador de producto con el servicio Amazon OpenSearch. Se centra en las tecnologías de ingestión que permiten la ingestión de datos de una amplia variedad de fuentes en el servicio Amazon OpenSearch a escalera. Arjun está interesado en sistemas distribuidos a gran escalera y tecnologías centradas en la cúmulo, y tiene su sede en Seattle, Washington.
Arjun Nambiar es un administrador de producto con el servicio Amazon OpenSearch. Se centra en las tecnologías de ingestión que permiten la ingestión de datos de una amplia variedad de fuentes en el servicio Amazon OpenSearch a escalera. Arjun está interesado en sistemas distribuidos a gran escalera y tecnologías centradas en la cúmulo, y tiene su sede en Seattle, Washington.