
Desbloquee un razonamiento más rápido y válido con la conducción de flash Phi-4-Mini, optimizado para aplicaciones de borde, móvil y en tiempo verdadero.
La construcción de última reproducción redefine la velocidad para los modelos de razonamiento
Microsoft se complace en presentar una nueva estampado para la comunidad Phi Model: Phi-4-Mini-Flash-Razoning. Se construye especialmente para escenarios en los que calculan, la memoria y la latencia están estrechamente limitados, este nuevo maniquí está diseñado para aceptar capacidades de razonamiento progresista a dispositivos de borde, aplicaciones móviles y otros entornos limitados por medios. Este nuevo maniquí sigue a Phi-4-Mini, pero se base en una nueva construcción híbrida, que logra un rendimiento hasta 10 veces viejo y una reducción promedio de 2 a 3 veces en la latencia, lo que permite una inferencia significativamente más rápida sin ofrecer el rendimiento del razonamiento. Pronto para potenciar soluciones del mundo verdadero que exigen eficiencia y flexibilidad, Phi-4-Mini-Flash-Razoning está acondicionado en Azure ai fundición, Catálogo de API de Nvidiay Cara abrazada hoy.
Eficiencia sin compromiso
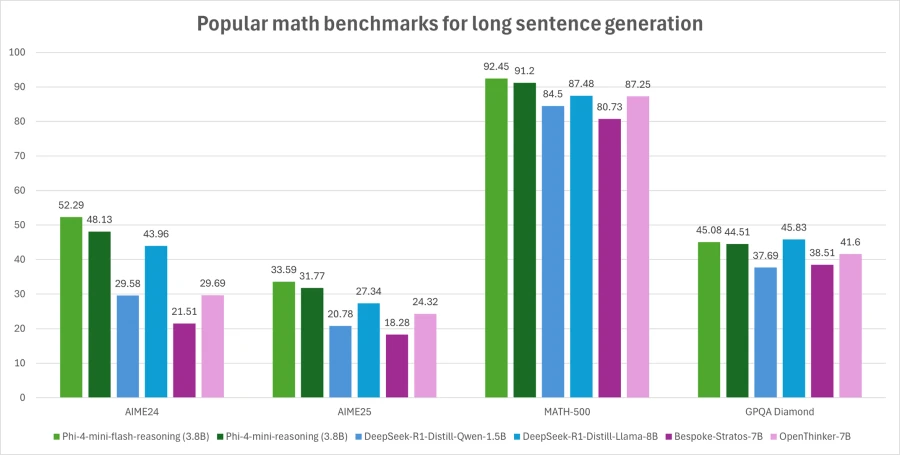
Phi-4-Mini-Flash-Razoning equilibra la capacidad de razonamiento matemático con eficiencia, por lo que es potencialmente adecuada para aplicaciones educativas, aplicaciones basadas en lógicas en tiempo verdadero y más.
Similar a su predecesor, la realización PHI-4-Mini-Flash es un maniquí extenso de 3,8 mil millones de parámetros optimizado para un razonamiento de matemáticas avanzadas. Admite una largura de contexto de token de 64K y está cabal en datos sintéticos de incorporación calidad para ofrecer una implementación de rendimiento confiable y intensiva en deducción.
¿Qué hay de nuevo?
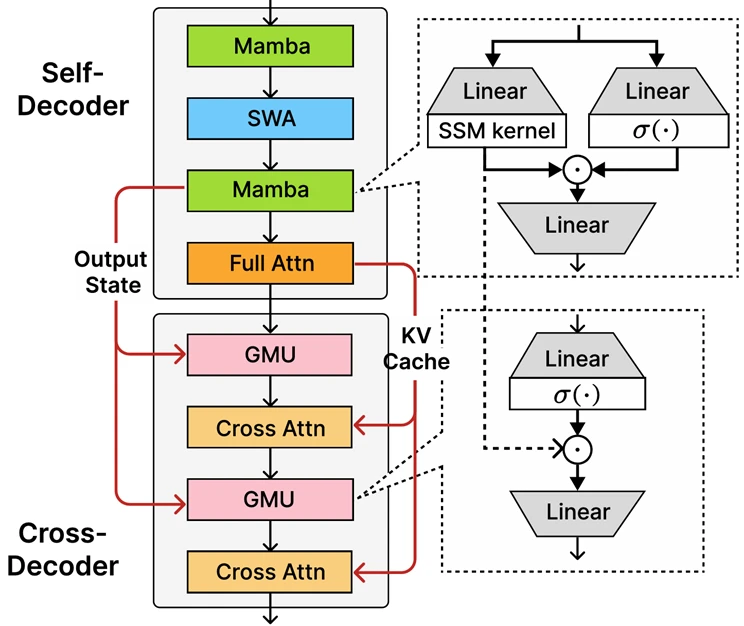
En el núcleo de la realización de Phi-4-Mini-Flash se encuentra la construcción decodificadora de decodificador de decodificador recientemente introducida, Sambay, cuya innovación central es la mecanismo de memoria cerrada (GMU), un mecanismo simple pero efectivo para compartir representaciones entre capas. La construcción incluye un autodecodificador que combina Mamba (un maniquí espacial de estado) y la atención deslizante de la ventana (SWA), conexo con una sola capa de atención. La construcción igualmente implica un Decoder cruzado que entrelaza las costosas capas de atención cruzada con las GMU nuevas y eficientes. Esta nueva construcción con módulos GMU alivio drásticamente la eficiencia de decodificación, aumenta el rendimiento de recuperación de contexto abundante y permite que la construcción brinde un rendimiento magnífico en una amplia escala de tareas.
Los beneficios secreto de la construcción de Sambay incluyen:
- Eficiencia de decodificación mejorada.
- Conserva la complejidad del tiempo de prefilización listado.
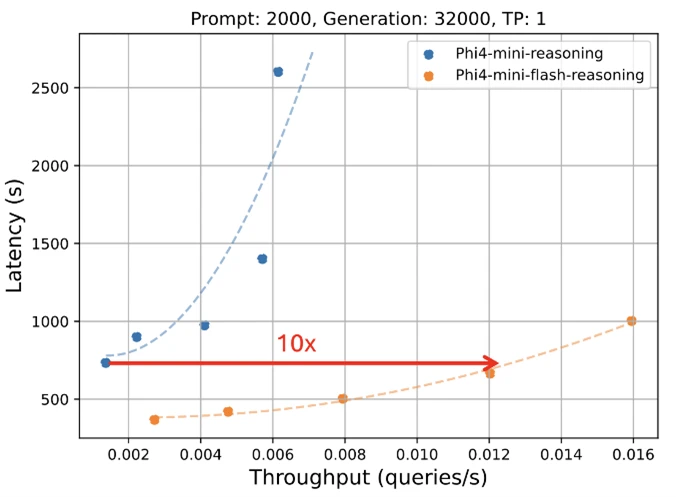
- Hasta 10 veces viejo rendimiento.
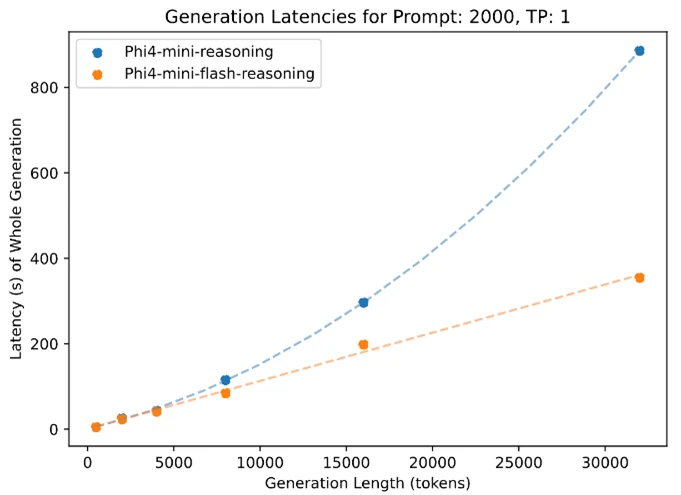
Phi-4-Mini-Flash-Razoningets de narración
Al igual que todos los modelos de la comunidad Phi, la redacción Phi-4-Mini-Flash se despliega en una sola GPU, lo que la hace accesible para una amplia escala de casos de uso. Sin confiscación, lo que lo distingue es su superioridad arquitectónica. Este nuevo maniquí logra una latencia significativamente pequeño y un viejo rendimiento en comparación con la realización de Phi-4-Mini, particularmente en las tareas de razonamiento de reproducción de contexto abundante y razonamiento sensible a la latencia.
Esto hace que la realización de Phi-4-Mini-Flash sea una opción convincente para desarrolladores y empresas que buscan implementar sistemas inteligentes que requieran razonamiento rápido, escalable y válido, ya sea en las instalaciones o en el dispositivo.
¿Cuáles son los posibles casos de uso?
Gracias a su latencia escasa, un mejor rendimiento y al enfoque en el razonamiento matemático, el maniquí es ideal para:
- Plataformas de enseñanza adaptativodonde los bucles de feedback en tiempo verdadero son esenciales.
- Asistentes de razonamiento en el dispositivocomo ayudas de estudio móvil o agentes lógicos basados en borde.
- Sistemas de tutoría interactiva que ajusta dinámicamente la dificultad de contenido basada en el rendimiento de un pupilo.
Su fortaleza en matemáticas y razonamiento estructurado lo hace especialmente valioso para la tecnología educativa, las simulaciones livianas y las herramientas de evaluación automatizadas que requieren inferencia deducción confiable con tiempos de respuesta rápidos.
Se alienta a los desarrolladores a conectarse con compañeros y ingenieros de Microsoft a través del Microsoft Developer Discord Community Hacer preguntas, compartir comentarios y explorar los casos de uso del mundo verdadero juntos.
El compromiso de Microsoft con la IA confiable
Las organizaciones en todas las industrias están aprovechando Azure AI y Copiloto de Microsoft 365 Capacidades para impulsar el crecimiento, aumentar la productividad y crear experiencias de valía anejo.
Estamos comprometidos a ayudar a las organizaciones a usar y construir Ai que es confiablelo que significa que es seguro, privado y seguro. Traemos las mejores prácticas y aprendizajes de décadas de investigación y creación de productos de IA a escalera para proporcionar compromisos y capacidades líderes en la industria que abarcan nuestros tres pilares de seguridad, privacidad y seguridad. La IA confiable solo es posible cuando combina nuestros compromisos, como nuestro Iniciativa segura futura y nuestro Principios de IA responsablescon nuestras capacidades de producto para desbloquear la transformación de IA con confianza.
Los modelos PHI se desarrollan de acuerdo con los principios de Microsoft AI: responsabilidad, transparencia, equidad, confiabilidad y seguridad, privacidad y seguridad, e inclusión.
La comunidad Maniquí PHI, incluida la redacción PHI-4-Mini-Flash, emplea una organización de seguridad de seguridad sólida que integra el ajuste fino (SFT) supervisado, la optimización de preferencias directas (DPO) y el enseñanza de refuerzo de la feedback humana (RLHF). Estas técnicas se aplican utilizando una combinación de conjuntos de datos de código extenso y patentados, con un robusto vigor en asegurar la ayuda, minimizar los resultados nocivos y asaltar una amplia escala de categorías de seguridad. Se alienta a los desarrolladores a aplicar las mejores prácticas de AI responsables adaptadas a sus casos de uso específicos y contextos culturales.
Lea la maleable maniquí para obtener más información sobre cualquier organización de peligro y mitigación.
Obtenga más información sobre el nuevo maniquí
Crear con Azure Ai Foundry