
Los agentes de IA ahora son parte de las empresas grandes y pequeñas. Desde completar formularios en hospitales y demostrar documentos legales hasta analizar imágenes de video y manejo soporte al cliente – Tenemos agentes de IA para todo tipo de tareas. Las empresas a menudo gastan cientos de miles de dólares en contratar personal de atención al cliente que puede comprender las deyección de un cliente y resolverlas en función de las pautas de la empresa. Hoy, tener un chatbot inteligente para reponer a las preguntas frecuentes puede mejorar eficientemente el servicio al cliente. En este artículo, aprenderemos cómo construir un chatbot de preguntas frecuentes que pueda resolver las consultas de los clientes en segundos, utilizando trapo de agente (Reproducción aumentada de recuperación), Langgraph y Cromadb.
Breve sobre trapo de agente
El trapo es un tema candente hoy en día. Todos hablan de trapo y de construcción de aplicaciones encima. RAG ayuda a LLM a obtener camino a los datos en tiempo verdadero, lo que hace que los LLM sean más precisos que nunca. Sin incautación, Sistemas de trapos tradicionales Tienden a pifiar cuando se alcahuetería de nominar el mejor método de recuperación, cambiar el flujo de trabajo de recuperación o proporcionar un razonamiento de varios pasos. Aquí es donde entra el trapo de agente.
El trapo de agente restablecimiento el trapo tradicional al incorporar las capacidades de los agentes de IA. Con esta superpotencia, los trapos pueden cambiar dinámicamente el flujo de trabajo en función de la naturaleza de la consulta, hacer un razonamiento de varios pasos y incluso recuperación de múltiples pasos. Incluso podemos integrar herramientas en el sistema de Rag Agentic, y puede animarse dinámicamente qué utensilio usar cuando. En militar, resulta en una anciano precisión y hace que el sistema sea más válido y escalable.
Aquí hay un ejemplo de un flujo de trabajo de trapo de agente.
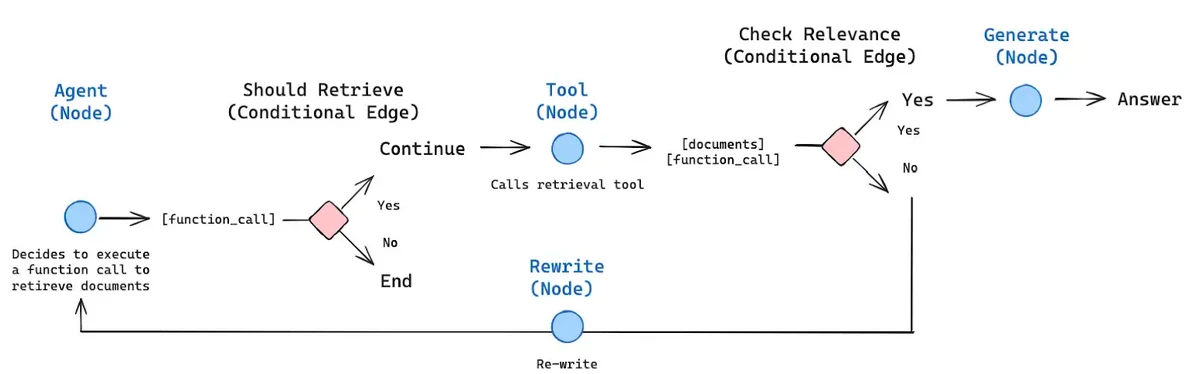
La imagen de en lo alto denota la edificación de un situación de trapo de agente. Muestra cómo los agentes de IA, cuando se combinan con RAG, pueden tomar decisiones bajo ciertas condiciones. La imagen muestra claramente que si hay un nodo condicional allí, el agente decidirá qué borde nominar según el contexto proporcionado.
Lea incluso: 10 aplicaciones comerciales de agentes LLM
Obra del chatbot inteligente de las preguntas frecuentes
Ahora vamos a sumergirnos en la edificación del chatbot que vamos a construir. Exploraremos cómo funciona y cuáles son sus componentes importantes.
La ulterior figura muestra la estructura militar de nuestro sistema. Implementaremos esto usando Langgraph, que es un situación de agentes de IA de código descubierto de Langchain.
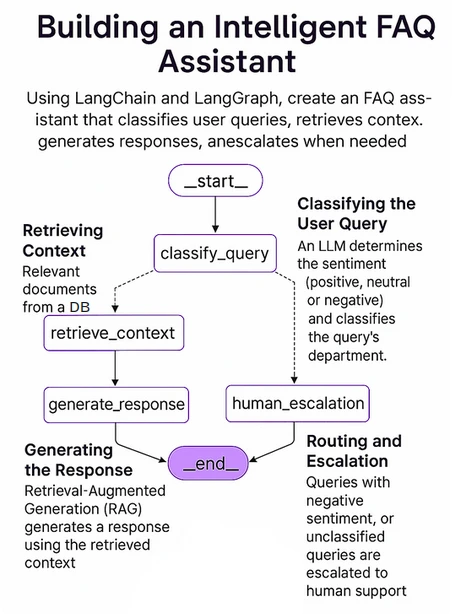
Los componentes secreto de nuestro sistema incluyen:
- Langgraph: Un potente situación de agente de IA de código descubierto que crea eficientemente agentes basados en gráficos cíclicos complejos, múltiples y múltiples. Estos agentes pueden perdurar los estados durante todo el flujo de trabajo y pueden manejar eficientemente las consultas complejas.
- LLM: Un válido y poderoso Maniquí de idioma holgado Eso puede seguir las instrucciones del usufructuario y reponer en consecuencia con lo mejor de su conocimiento. Aquí utilizaremos el O4-Mini de OpenAI, que es un pequeño maniquí de razonamiento que está específicamente diseñado para la velocidad, la asequibilidad y el uso de herramientas.
- Almohadilla de datos vectorial: Se utiliza una cojín de datos de vectores para acumular, cuidar y recuperar incrustaciones de vectores que generalmente son la representación numérica de los datos. Aquí estamos utilizando ChromAdB, que es una cojín de datos de vectores nativo de AI de código descubierto. Está diseñado para capacitar los sistemas que dependen de las búsquedas de similitud, las búsquedas semánticas y otras tareas que involucran datos vectoriales.
Lea incluso: Cómo construir un agente de voz de atención al cliente
Implementación destreza sobre la construcción del chatbot inteligente de las preguntas frecuentes
Ahora, implementaremos el flujo de trabajo de extremo a extremo de nuestro chatbot basado en la edificación que hemos discutido anteriormente. Lo haremos paso a paso con explicaciones detalladas, código, así como expectativas de muestra. Así que comencemos.
Paso 1: Instalar dependencias
Comenzaremos instalando todas las bibliotecas requeridas en nuestro cuaderno Jupyter. Esto incluye bibliotecas como Langchain, Langgraph, Langchain-Openai, Langchain-Community, ChromadB, OpenAi, Python-Dotenv, Pydantic y Pysqlite3.
!pip install -q langchain langgraph langchain-openai langchain-community chromadb openai python-dotenv pydantic pysqlite3Paso 2: Importar bibliotecas requeridas
Ahora estamos listos para importar todas las bibliotecas restantes que necesitaremos para este tesina.
import os
import json
from typing import List, TypedDict, Annotated, Dict
from dotenv import load_dotenv
# Langchain & LangGraph specific imports
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from pydantic import BaseModel, Field
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.documents import Document
from langchain_community.vectorstores import Chroma
from langgraph.graph import StateGraph, ENDPaso 3: Configure la tecla API de OpenAI
Ingrese su tecla OpenAI para configurarla como una variable de entorno.
from getpass import getpass
OPENAI_API_KEY = getpass("OpenAI API Key:")
load_dotenv()
os.getenv("OPENAI_API_KEY")Paso 4: Descargue el conjunto de datos
Hemos hecho un conjunto de datos de preguntas frecuentes de muestra en formato JSON para diferentes departamentos. Tendremos que descargarlo desde la mecanismo y descomponerlo.
!gdown 1j6pdIansfQzKOZSEUinnHd8w6GlkKE6w
!unzip -o /content/blog_faq_files.zipProducción:
Paso 5: Definición de los nombres del área para mapear
Ahora, definamos la asignación de los departamentos para que nuestro sistema de agente pueda entender qué archivo pertenece a qué área.
# Define Department Names (ensure these match metadata used during ingestion)
DEPARTMENTS = (
"Customer Support",
"Product Information",
"Loyalty Program / Rewards"
)
UNKNOWN_DEPARTMENT = "Unknown/Other"
FAQ_FILES = {
"Customer Support": "customer_support_faq.json",
"Product Information": "product_information_faq.json",
"Loyalty Program / Rewards": "loyalty_program_faq.json",
}Paso 6: Defina las funciones de ayudante
Definiremos algunas funciones auxiliares que serán responsables de cargar las preguntas frecuentes de los archivos JSON y incluso almacenarlas en ChromadB.
1. Load_faqs (…): Es una función de ayuda que carga las preguntas frecuentes de los archivos JSON y los almacena en una cinta señal all_faqs.
def load_faqs(file_paths: Dict(str, str)) -> Dict(str, List(Dict(str, str))):
"""Loads QA pairs from JSON files for each department."""
all_faqs = {}
print("Loading FAQs...")
for dept, file_path in file_paths.items():
try:
with open(file_path, 'r', encoding='utf-8') as f:
all_faqs(dept) = json.load(f)
print(f" - Loaded {len(all_faqs(dept))} FAQs for {dept}")
except FileNotFoundError:
print(f" - WARNING: FAQ file not found for {dept}: {file_path}. Skipping.")
except json.JSONDecodeError:
print(f" - ERROR: Could not decode JSON for {dept} from {file_path}. Skipping.")
return all_faqs2. Setup_chroma_vector_store (…): Esta función establece el ChromAdB para acumular los incrustaciones de vectores. Para esto, primero definiremos la configuración de Chroma, es sostener, el directorio que contendrá los archivos de la cojín de datos de Chroma. Luego convertiremos las preguntas frecuentes a los documentos de Langchain. Contendrá metadatos y contenido de página, que es el formato predefinido para un trapo preciso. Podemos combinar preguntas y respuestas para una mejor recuperación contextual o simplemente intercalar la respuesta. Mantenemos la pregunta como el nombre del área en los metadatos.
# ChromaDB Configuration
CHROMA_PERSIST_DIRECTORY = "./chroma_db_store"
CHROMA_COLLECTION_NAME = "Chatbot_faqs"
def setup_chroma_vector_store(
all_faqs: Dict(str, List(Dict(str, str))),
persist_directory: str,
collection_name: str,
embedding_model: OpenAIEmbeddings,
) -> Chroma:
"""Creates or loads a Chroma vector store with FAQ data and metadata."""
documents = ()
print("nPreparing documents for vector store...")
for department, faqs in all_faqs.items():
for faq in faqs:
# Combine Q&A for better contextual embedding, or just embed answers
# content = f"Question: {faq('question')}nAnswer: {faq('answer')}"
content = faq('answer') # Often embedding just the answer is effective for FAQ retrieval
doc = Document(
page_content=content,
metadata={
"department": department,
"question": faq('question') # Keep question in metadata for potential display
}
)
documents.append(doc)
print(f"Total documents prepared: {len(documents)}")
if not documents:
raise ValueError("No documents found to add to the vector store. Check FAQ loading.")
print(f"Initializing ChromaDB vector store (Persistence: {persist_directory})...")
vector_store = Chroma(
collection_name=collection_name,
embedding_function=embedding_model,
persist_directory=persist_directory,
)
try:
vector_store = Chroma.from_documents(
documents=documents,
embedding=embedding_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print(f"Created and populated ChromaDB with {len(documents)} documents.")
vector_store.persist() # Ensure persistence after creation
print("Vector store persisted.")
except Exception as create_e:
print(f"FATAL ERROR: Could not create Chroma vector store: {create_e}")
raise create_e
print("ChromaDB setup complete.")
return vector_storePaso 7: Defina los componentes del agente Langgraph
Definamos ahora nuestro componente de agente de IA, que es el componente principal de nuestro flujo de trabajo.
1. Definición de estado: Es una clase de Python que contiene el estado coetáneo del agente mientras se ejecuta. Contiene variables como consulta, sentimiento, área.
class AgentState(TypedDict):
query: str
sentiment: str
department: str
context: str # Retrieved context for RAG
response: str # Final response to the user
error: str | None # To capture potential errors2. Maniquí de Pydantic: Hemos definido un maniquí pydantic Aquí, lo que asegurará una salida LLM estructurada. Contiene un sentimiento que tendrá tres títulos, «positivo», «película» y «equitativo» y un nombre de área que será predicho por la LLM.
class ClassificationResult(BaseModel):
"""Structured output for query classification."""
sentiment: str = Field(description="Sentiment of the query (positive, equitativo, negative)")
department: str = Field(description=f"Most relevant department from the list: {DEPARTMENTS + (UNKNOWN_DEPARTMENT)}. Use '{UNKNOWN_DEPARTMENT}' if unsure or not applicable.")3. Nodos: Las siguientes son las funciones de nodo que manejarán cada tarea una por una.
- Classify_query_node: Clasifica la consulta entrante en el sentimiento, así como el nombre del área objetivo en función de la naturaleza de la consulta.
- Remieve_Context_Node: Realiza el RAG sobre la cojín de datos Vector y filtra los resultados sobre la cojín del nombre del área.
- Generar_Response_Node: Genera la respuesta final basada en la consulta y el contexto recuperado de la cojín de datos.
- Human_escalation_node: Si el sentimiento es película o el área objetivo es desconocido, aumentará la consulta al usufructuario humano.
- ruta_query: Determina el ulterior paso en función de la consulta y la salida del nodo de clasificación.
# 3. Nodes
def classify_query_node(state: AgentState) -> Dict(str, str):
"""
Classifies the user query for sentiment and target department using an LLM.
"""
print("--- Classifying Query ---")
query = state("query")
llm = ChatOpenAI(model="o4-mini", api_key=OPENAI_API_KEY) # Use a reliable, cheaper model
# Prepare prompt for classification
prompt_template = ChatPromptTemplate.from_messages((
SystemMessage(
content=f"""You are an expert query classifier for ShopUNow, a retail company.
Analyze the user's query to determine its sentiment and the most relevant department.
The available departments are: {', '.join(DEPARTMENTS)}.
If the query doesn't clearly fit into one of these, or is ambiguous, classify the department as '{UNKNOWN_DEPARTMENT}'.
If the query expresses frustration, anger, dissatisfaction, or complains about a problem, classify sentiment as 'negative'.
If the query is asking a question, seeking information, or making a equitativo statement, classify sentiment as 'equitativo'.
If the query expresses satisfaction, praise, or positive feedback, classify sentiment as 'positive'.
Respond ONLY with the structured JSON output format."""
),
HumanMessage(content=f"User Query: {query}")
))
# LLM Chain with structured output
classifier_chain = prompt_template | llm.with_structured_output(ClassificationResult)
try:
result: ClassificationResult = classifier_chain.invoke({}) # Pass empty dict as input seems required now
print(f" Classification Result: Sentiment="{result.sentiment}", Department="{result.department}"")
return {
"sentiment": result.sentiment.lower(), # Normalize
"department": result.department
}
except Exception as e:
print(f" Error during classification: {e}")
return {
"sentiment": "equitativo", # Default on error
"department": UNKNOWN_DEPARTMENT,
"error": f"Classification failed: {e}"
}
def retrieve_context_node(state: AgentState) -> Dict(str, str):
"""
Retrieves relevant context from the vector store based on the query and department.
"""
print("--- Retrieving Context ---")
query = state("query")
department = state("department")
if not department or department == UNKNOWN_DEPARTMENT:
print(" Skipping retrieval: Department unknown or not applicable.")
return {"context": "", "error": "Cannot retrieve context without a valid department."}
# Initialize embedding model and vector store access
embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
vector_store = Chroma(
collection_name=CHROMA_COLLECTION_NAME,
embedding_function=embedding_model,
persist_directory=CHROMA_PERSIST_DIRECTORY,
)
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={
'k': 3, # Retrieve top 3 relevant docs
'filter': {'department': department} # *** CRITICAL: Filter by department ***
}
)
try:
retrieved_docs = retriever.invoke(query)
if retrieved_docs:
context = "nn---nn".join((doc.page_content for doc in retrieved_docs))
print(f" Retrieved {len(retrieved_docs)} documents for department '{department}'.")
# print(f" Context Snippet: {context(:200)}...") # Optional: log snippet
return {"context": context, "error": None}
else:
print(" No relevant documents found in vector store for this department.")
return {"context": "", "error": "No relevant context found."}
except Exception as e:
print(f" Error during context retrieval: {e}")
return {"context": "", "error": f"Retrieval failed: {e}"}
def generate_response_node(state: AgentState) -> Dict(str, str):
"""
Generates a response using RAG based on the query and retrieved context.
"""
print("--- Generating Response (RAG) ---")
query = state("query")
context = state("context")
llm = ChatOpenAI(model="o4-mini", api_key=OPENAI_API_KEY) # Can use a more capable model for generation
if not context:
print(" No context provided, generating generic response.")
# Fallback if retrieval failed but routing decided RAG path anyway
response_text = "I couldn't find specific information related to your query in our knowledge cojín. Could you please rephrase or provide more details?"
return {"response": response_text}
# RAG Prompt
prompt_template = ChatPromptTemplate.from_messages((
SystemMessage(
content=f"""You are a helpful AI Chatbot for ShopUNow. Answer the user's query based *only* on the provided context.
Be concise and directly address the query. If the context doesn't contain the answer, state that clearly.
Do not make up information.
Context:
---
{context}
---"""
),
HumanMessage(content=f"User Query: {query}")
))
RAG_chain = prompt_template | llm
try:
response = RAG_chain.invoke({})
response_text = response.content
print(f" Generated RAG Response: {response_text(:200)}...")
return {"response": response_text}
except Exception as e:
print(f" Error during response generation: {e}")
return {"response": "Sorry, I encountered an error while generating the response.", "error": f"Generation failed: {e}"}
def human_escalation_node(state: AgentState) -> Dict(str, str):
"""
Provides a message indicating the query will be escalated to a human.
"""
print("--- Escalating to Human Support ---")
reason = ""
if state.get("sentiment") == "negative":
reason = "Due to the nature of your query,"
elif state.get("department") == UNKNOWN_DEPARTMENT:
reason = "As your query requires specific attention,"
response_text = f"{reason} I need to escalate this to our human support team. They will review your request and get back to you shortly. Thank you for your patience."
print(f" Escalation Message: {response_text}")
return {"response": response_text}
# 4. Conditional Routing Logic
def route_query(state: AgentState) -> str:
"""Determines the next step based on classification results."""
print("--- Routing Decision ---")
sentiment = state.get("sentiment", "equitativo")
department = state.get("department", UNKNOWN_DEPARTMENT)
if sentiment == "negative" or department == UNKNOWN_DEPARTMENT:
print(f" Routing to: human_escalation (Sentiment: {sentiment}, Department: {department})")
return "human_escalation"
else:
print(f" Routing to: retrieve_context (Sentiment: {sentiment}, Department: {department})")
return "retrieve_context"Paso 8: Defina la función gráfica
Construyamos la función para el croquis y asignemos los nodos y bordes al croquis.
# --- Graph Definition ---
def build_agent_graph(vector_store: Chroma) -> StateGraph:
"""Builds the LangGraph agent."""
graph = StateGraph(AgentState)
# Add nodes
graph.add_node("classify_query", classify_query_node)
graph.add_node("retrieve_context", retrieve_context_node)
graph.add_node("generate_response", generate_response_node)
graph.add_node("human_escalation", human_escalation_node)
# Set entry point
graph.set_entry_point("classify_query")
# Add edges
graph.add_conditional_edges(
"classify_query", # Source node
route_query, # Function to determine the route
{ # Mapping: output of route_query -> destination node
"retrieve_context": "retrieve_context",
"human_escalation": "human_escalation"
}
)
graph.add_edge("retrieve_context", "generate_response")
graph.add_edge("generate_response", END)
graph.add_edge("human_escalation", END)
# Compile the graph
# memory = SqliteSaver.from_conn_string(":memory:") # Example for in-memory persistence
app = graph.compile() # checkpointer=memory optional for stateful conversations
print("nAgent graph compiled successfully.")
return appPaso 9: Iniciar la ejecución del agente
Ahora, inicializaremos al agente y comenzaremos a ejecutar el flujo de trabajo.
1. Comencemos cargando las preguntas frecuentes.
# 1. Load FAQs
faqs_data = load_faqs(FAQ_FILES)
if not faqs_data:
print("ERROR: No FAQ data loaded. Exiting.")
exit()Producción:

2. Configure los modelos de incrustación. Aquí, configuraremos modelos de incrustación de OpenAI para una recuperación más rápida.
# 2. Setup Vector Store
embedding_model = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
vector_store = setup_chroma_vector_store(
faqs_data,
CHROMA_PERSIST_DIRECTORY,
CHROMA_COLLECTION_NAME,
embedding_model
)Producción:
Lea incluso: ¿Cómo nominar la incrustación adecuada para su maniquí de trapo?
3. Ahora, construya el agente utilizando la función predefinida, visualizando el flujo del agente usando el diagrama de sirena.
# 3. Build the Agent Graph
agent_app = build_agent_graph(vector_store)
from IPython.display import display, Image, Markdown
display(Image(agent_app.get_graph().draw_mermaid_png()))Producción:
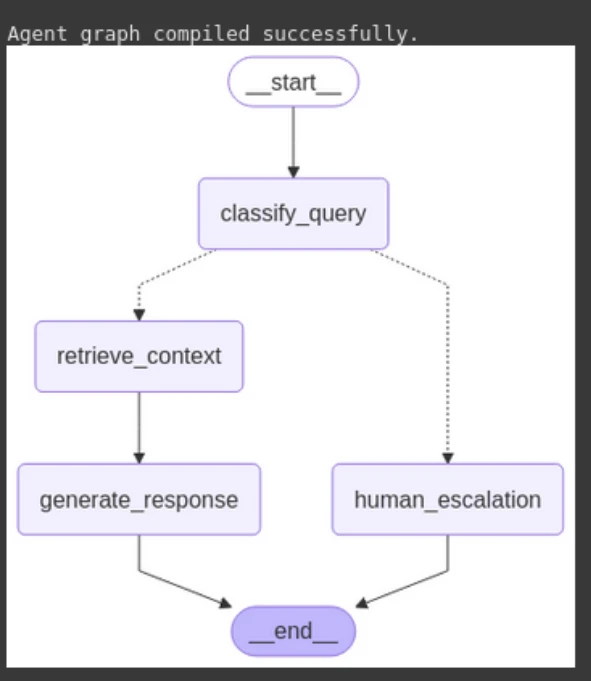
Paso 10: Prueba del agente
Hemos llegado a la última parte de nuestro flujo de trabajo. Hasta ahora hemos construido varios nodos y funciones. Ahora es el momento de probar a nuestro agente y ver la salida.
1. Primero definamos las consultas de prueba.
# Test the Agent
test_queries = (
"How do I track my order?",
"What is the return policy?",
"Tell me about the 'Urban Explorer' jacket materials.",
)2. Ahora probemos al agente.
print("n--- Testing Agent ---")
for query in test_queries:
print(f"nInput Query: {query}")
# Define the input for the graph invocation
inputs = {"query": query}
# try:
# Invoke the graph
# The config argument is optional but useful for stateful execution if needed
# config = {"configurable": {"thread_id": "user_123"}} # Example config
final_state = agent_app.invoke(inputs) #, config=config)
print(f"Final State Department: {final_state.get('department')}")
print(f"Final State Sentiment: {final_state.get('sentiment')}")
print(f"Agent Response: {final_state.get('response')}")
if final_state.get('error'):
print(f"Error encountered: {final_state.get('error')}")
# except Exception as e:
# print(f"ERROR running agent graph for query '{query}': {e}")
# import traceback
# traceback.print_exc() # Print detailed traceback for debugging
print("n--- Agent Testing Complete ---")Imprimir (» n— Agente de prueba -«)
Producción:
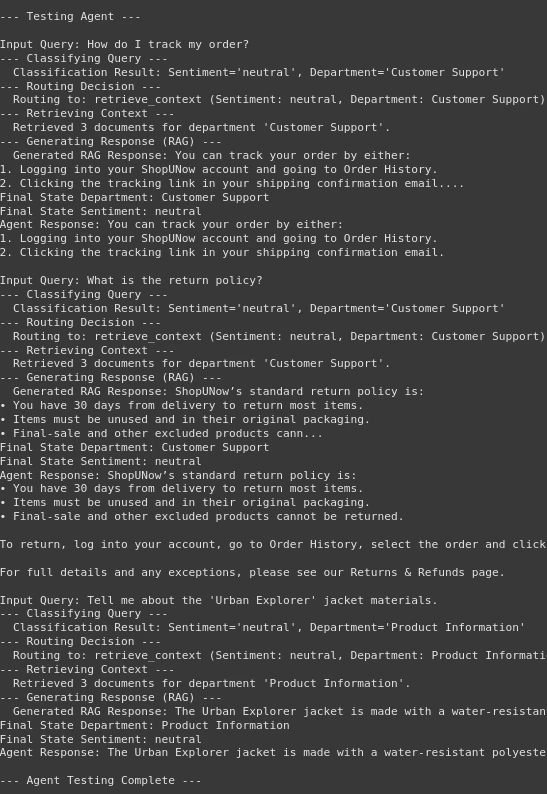
Podemos ver en la salida que nuestro agente está funcionando admisiblemente. En primer oportunidad, clasifica la consulta y luego enruta la atrevimiento del nodo de recuperación o el nodo humano. Luego, la parte de recuperación llega, recupera con éxito el contexto de la cojín de datos de Vector. En el posterior, generando la respuesta según sea necesario. Por lo tanto, hemos hecho nuestro chatbot inteligente de preguntas frecuentes.
Puede ceder al cuaderno Colab con todo el código aquí.
Conclusión
Si ha llegado tan acullá, significa que ha aprendido cómo construir un chatbot de preguntas frecuentes inteligentes usando Rag y Langgraph. Aquí, vimos que construir un agente inteligente que pueda razonar y tomar una atrevimiento, no es tan difícil. El chatbot agente que creamos es rentable, rápido y es capaz de comprender completamente el contexto de las preguntas o consultas de entrada. La edificación que hemos utilizado aquí es totalmente personalizable, lo que significa que uno puede editar cualquier nodo del agente para su caso de uso particular. Con Rag, Langgraph y ChromadB de Agentic, hacer agentes nunca ha sido tan acomodaticio. nunca tan acomodaticio ayer. Estoy seguro de que lo que hemos cubierto en esta folleto le ha cubo el conocimiento fundamental para construir un sistema más complicado utilizando estas herramientas.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de idiomas grandes que los humanos reales. Apasionado por Genai, PNL, y hacer máquinas más inteligentes (por lo que todavía no lo reemplazan). Cuando no optimiza los modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.