
Qwen acaba de propalar 8 nuevos modelos como parte de su última clan: Qwen3, que muestra capacidades prometedoras. El maniquí insignia, QWEN3-235B-A22B, superó a la mayoría de los otros modelos, incluido Deepseek-R1, OPERAI’S O1O3-Mini, Grok 3, y Géminis 2.5-proen puntos de remisión standard. Mientras tanto, el pequeño QWEN3-30B-A3B superó QWQ-32B que tiene aproximadamente 10 veces los parámetros activados como el nuevo maniquí. Con tales capacidades avanzadas, estos modelos demuestran ser una gran opción para una amplia serie de aplicaciones. En este artículo, exploraremos las características de todos los modelos QWEN3 y aprenderemos cómo usarlos para construir sistemas de trapo y agentes de IA.
¿Qué es Qwen3?
Qwen3 es la última serie de modelos de idiomas grandes (LLMS) en la clan Qwen, que consta de 8 modelos diferentes. Estos incluyen QWEN3-235B-A22B, QWEN3-30B-A3B, QWEN3-32B, QWEN3-14B, QWEN3-8B, QWEN3-4B, QWEN3-1.7B y QWEN3-0.6B. Todos estos modelos se lanzan bajo la deshonestidad Apache 2.0, haciéndolos disponibles gratis para individuos, desarrolladores y empresas.
Mientras que 6 de estos modelos son densos, lo que significa que usan activamente todos los parámetros durante el tiempo de inferencia y capacitación, 2 de ellos son ponderados:
- QWEN3-235B-A22B: Un maniquí ínclito con 235 mil millones de parámetros, de los cuales 22 mil millones son parámetros activados.
- QWEN3-30B-A3B: Un MOE más pequeño con 30 mil millones de parámetros totales y 3 mil millones de parámetros activados.
Aquí hay una comparación detallada de todos los 8 modelos QWEN3:
| Modelos | Capas | Cabezas (Q/KV) | Entablar | Largo de contexto |
| Qwen3-0.6b | 28 | 16/8 | Sí | 32k |
| Qwen3-1.7b | 28 | 16/8 | Sí | 32k |
| Qwen3-4b | 36 | 32/8 | Sí | 32k |
| Qwen3-8b | 36 | 32/8 | No | 128k |
| QWEN3-14B | 40 | 40/8 | No | 128k |
| QWEN3-32B | 64 | 64/8 | No | 128k |
| QWEN3-30B-A3B | 48 | 32/4 | No | 128k |
| QWEN3-235B-A22B | 94 | 64/4 | No | 128k |
Esto es lo que dice la mesa:
- Capas: Las capas representan el número de bloques de transformadores utilizados. Incluye un mecanismo de autoatención de múltiples cabezas, redes de provisiones en torno a delante, codificación posicional, normalización de la capa y conexiones residuales. Entonces, cuando digo que QWEN3-30B-A3B tiene 48 capas, significa que el maniquí usa 48 bloques de transformadores, apilados secuencialmente o en paralelo.
- Cabezas: Los transformadores usan atención múltiple, lo que divide su mecanismo de atención en varias cabezas, cada una para ilustrarse un nuevo aspecto de los datos. Aquí, Q/KV representa:
- P (cabezas de consulta): Número total de cabezas de atención utilizadas para ocasionar consultas.
- KV (secreto y valencia): El número de cabezales de secreto/valencia por piedra de atención.
Nota: Estos cabezales de atención para la secreto, la consulta y el valencia son completamente diferentes de la secreto, la consulta y el vector de valencia generado por una autoatención.
Lea además: Modelos QWEN3: cómo alcanzar, rendimiento, características y aplicaciones
Características secreto de Qwen3
Estas son algunas de las características secreto de los modelos QWEN3:
- Pretruado: El proceso de pre-entrenamiento consta de tres etapas:
- En la primera etapa, el maniquí se produjo previamente en más de 30 billones de tokens con una distancia de contexto de 4K tokens. Esto enseñó al maniquí de habilidades lingüísticas básicas y conocimientos generales.
- En la segunda etapa, la calidad de los datos se mejoró al aumentar la proporción de datos intensivos en conocimiento como las tareas de STEM, codificación y razonamiento. Luego, el maniquí fue entrenado en 5 billones de tokens adicionales.
- En la etapa final, se utilizaron datos de contexto espacioso de ingreso calidad al aumentar la distancia de contexto a 32k tokens. Esto se hizo para avalar que el maniquí pueda manejar entradas más largas de forma efectiva.
- Post-entrenamiento: Para desarrollar un maniquí híbrido capaz de razonamiento paso a paso y respuestas rápidas, se implementó una cartera de capacitación de 4 etapas. Esto consistió en:
- Modos de pensamiento híbrido: Los modelos QWEN3 utilizan un enfoque híbrido para la resolución de problemas, con dos nuevos modos:
- Modo de pensamiento: En este modo, los modelos toman tiempo dividiendo una proclamación de problema compleja en pequeños y procedimientos para resolverlo.
- Modo que no tiene pensamiento: En este modo, el maniquí proporciona resultados rápidos y es principalmente adecuado para preguntas más simples.
- Soporte multilingüe: Los modelos QWEN3 admiten 119 idiomas y dialectos. Esto ayuda a los usuarios de todo el mundo a beneficiarse de estos modelos.
- Capacidades de agente improvisado: Qwen ha optimizado los modelos QWEN3 para una mejor codificación y capacidades de agente, admitiendo Protocolo de contexto del maniquí (MCP) además.
Cómo alcanzar a los modelos QWEN3 a través de API
Para usar los modelos QWEN3, lo accederemos a través de API utilizando la API OpenRouter. Aquí le mostramos cómo hacerlo:
- Crear una cuenta en OpenRouter Y vaya a la mostrador de búsqueda de modelos para encontrar la API para ese maniquí.
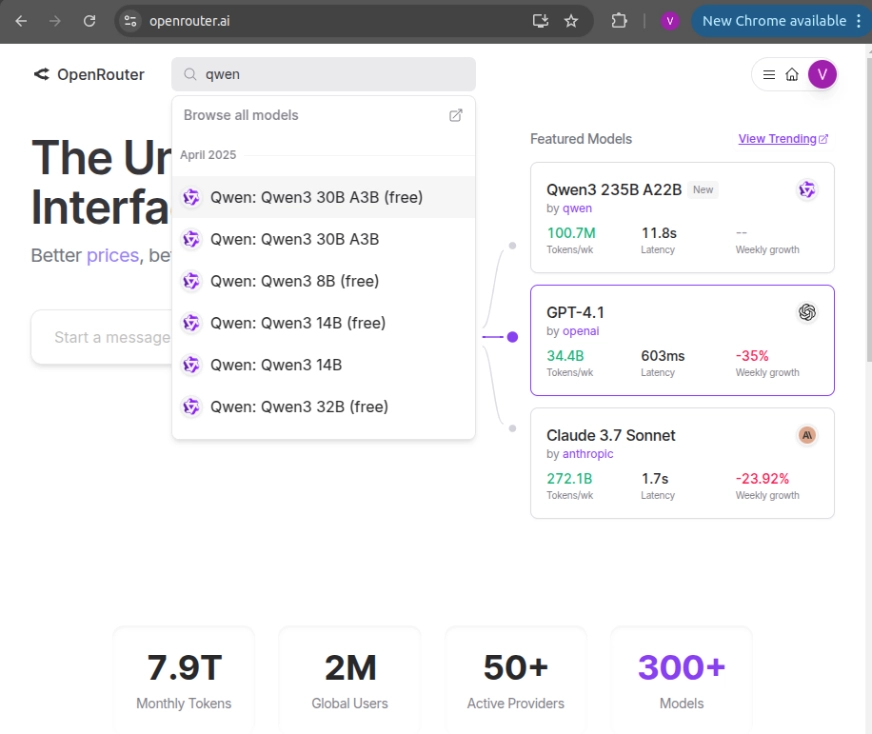
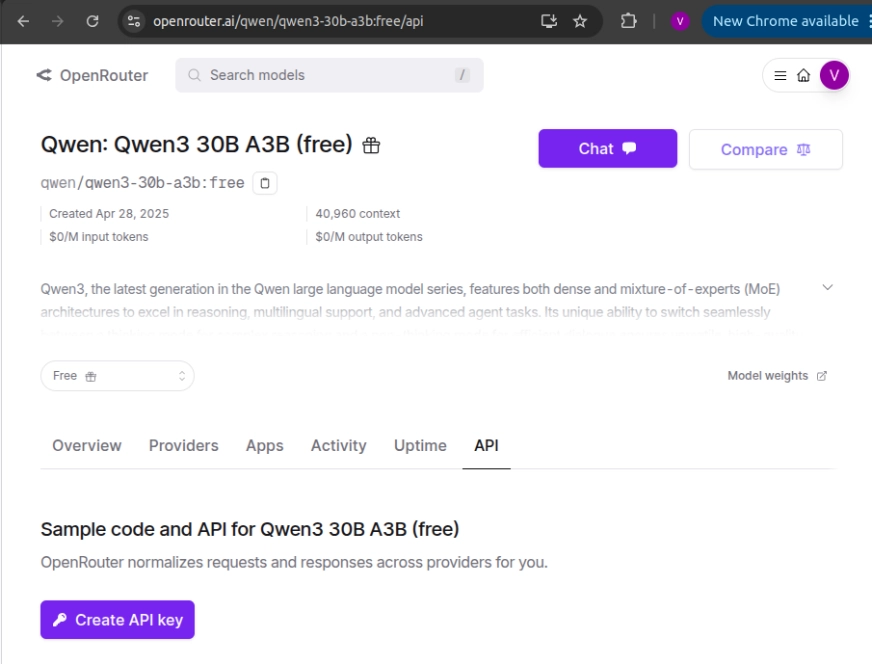
- Seleccione el maniquí de su sufragio y haga clic en ‘Crear secreto API’ en la página de destino para ocasionar una nueva API.
Uso de Qwen3 para proporcionar sus soluciones de IA
En esta sección, pasaremos por el proceso de construcción de aplicaciones de IA utilizando QWEN3. Primero crearemos un agente de planificadores de viajes con IA que usa el maniquí, y luego un Q/A Rag Bot que usa Langchain.
Requisitos previos
Antaño de construir algunas soluciones de IA del mundo efectivo con Qwen3, primero debemos cubrir los requisitos previos básicos como:
Construir un agente de IA usando QWEN3
En esta sección, utilizaremos QWEN3 para crear un agente de viajes a IA que le dará los principales lugares de delirio para la ciudad o el espacio que está visitando. Todavía permitiremos que el agente busque en Internet para encontrar información actualizada y agregaremos una útil que permita la conversión de divisas.
Paso 1: Configuración de bibliotecas y herramientas
Primero, instalaremos e importaremos las bibliotecas y herramientas necesarias necesarias para construir el agente.
!pip install langchain langchain-community openai duckduckgo-search
from langchain.chat_models import ChatOpenAI
from langchain.agents import Tool
from langchain.tools import DuckDuckGoSearchRun
from langchain.agents import initialize_agent
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key",
model="qwen/qwen3-235b-a22b:free"
)
# Web Search Tool
search = DuckDuckGoSearchRun()
# Tool for DestinationAgent
def get_destinations(destination):
return search.run(f"Top 3 tourist spots in {destination}")
DestinationTool = Tool(
name="Destination Recommender",
func=get_destinations,
description="Finds top places to visit in a city"
)
# Tool for CurrencyAgent
def convert_usd_to_inr(query):
amount = (float(s) for s in query.split() if s.replace('.', '', 1).isdigit())
if amount:
return f"{amount(0)} USD = {amount(0) * 83.2:.2f} INR"
return "Couldn't parse amount."
CurrencyTool = Tool(
name="Currency Converter",
func=convert_usd_to_inr,
description="Converts USD to inr based on static rate"
)- Search_tool: DuckDuckGosearchrun () permite al agente usar la búsqueda web para obtener información en tiempo efectivo sobre los populares lugares turísticos.
- Destinationtool: Aplica la función get_destinations (), que utiliza la útil de búsqueda para obtener los 3 mejores lugares turísticos en cualquier ciudad.
- CurrencyTool: Utiliza la función Convert_USD_TO_INR () para convertir los precios de USD a INR. Puede cambiar ‘INR’ en la función para convertirlo en una moneda de su sufragio.
Lea además: Construya un chatbot de asistente de delirio con Huggingface, Langchain y Mistralai
Paso 2: Creación del agente
Ahora que hemos inicializado todas las herramientas, procedamos a crear un agente que use las herramientas y nos brinde un plan para el delirio.
tools = (DestinationTool, CurrencyTool)
agent = initialize_agent(
tools=tools,
llm=llm,
agent_type="zero-shot-react-description",
verbose=True
)
def trip_planner(city, usd_budget):
dest = get_destinations(city)
inr_budget = convert_usd_to_inr(f"{usd_budget} USD to INR")
return f"""Here is your travel plan:
*Top spots in {city}*:
{dest}
*Budget*:
{inr_budget}
Enjoy your day trip!"""- Inicialize_agent: Esta función crea un agente con Langchain utilizando un enfoque de reacción de disparo cero, que permite al agente comprender las descripciones de la útil.
- Agente_type: «Cero-shot-react-descripción» permite al agente LLM arriesgarse qué útil debe usar en una determinada situación sin conocimiento previo, utilizando la descripción y la entrada de la útil.
- Verboso: Veverbose permite el registro del proceso de pensamiento del agente, por lo que podemos monitorear cada atrevimiento que toma el agente, incluidas todas las interacciones y herramientas invocadas.
- Trip_planner: Esta es una función de Python que apasionamiento manualmente herramientas en espacio de encargar en el agente. Permite al sucesor separar la mejor útil para un problema en particular.
Paso 3: Inicializar al agente
En esta sección, inicializaremos el agente y observaremos su respuesta.
# Initialize the Agent
city = "Delhi"
usd_budget = 8500
# Run the multi-agent planner
response = agent.run(f"Plan a day trip to {city} with a budget of {usd_budget} USD")
from IPython.display import Markdown, display
display(Markdown(response))- Invocación del agente: agent.run () utiliza la intención del sucesor a través de la solicitud y planea el delirio.
Producción

Construyendo un sistema de trapo utilizando Qwen3
En esta sección, crearemos un Bot de trapo Eso argumenta cualquier consulta interiormente del documento de entrada relevante de la almohadilla de conocimiento. Esto proporciona una respuesta informativa utilizando QWEN/QWEN3-235B-A22B. El sistema además estaría utilizando Langchain, para producir respuestas precisas y conscientes del contexto.
Paso 1: Configuración de las bibliotecas y herramientas
Primero, instalaremos e importaremos las bibliotecas y herramientas necesarias necesarias para construir el sistema RAG.
!pip install langchain langchain-community langchain-core openai tiktoken chromadb sentence-transformers duckduckgo-search
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# Load your document
loader = TextLoader("/content/my_docs.txt")
docs = loader.load()- Documentos de carga: La clase de «cargador de texto» de Langchain carga el documento como un archivo PDF, TXT o DOC que se utilizará para la recuperación de Q/A. Aquí he subido my_docs.txt.
- Selección de la configuración del vector: He usado ChromAdB para acumular y inquirir los incrustaciones desde nuestra almohadilla de datos Vector para el proceso Q/A.
Paso 2: Creación de incrustaciones
Ahora que hemos cargado nuestro documento, procedamos a crear integridades que ayuden a aliviar el proceso de recuperación.
# Split into chunks
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=50)
chunks = splitter.split_documents(docs)
# Embed with HuggingFace model
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
db = Chroma.from_documents(chunks, embedding=embeddings)
# Setup Qwen LLM from OpenRouter
llm = ChatOpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="YOUR_API_KEY",
model="qwen/qwen3-235b-a22b:free"
)
# Create RAG chain
retriever = db.as_retriever(search_kwargs={"k": 2})
rag_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)- División de documentos: El personaje de caracteres () divide el texto en trozos más pequeños, lo que ayudará principalmente en dos cosas. Primero, alivia el proceso de recuperación, y segundo, ayuda a retener el contexto del fragmento inicial a través de Chunk_overlap.
- Incrustación de documentos: Los incrustaciones convierten el texto en los vectores de incrustación de una dimensión establecida para cada token. Aquí hemos usado Chunk_Size de 300, lo que significa que cada palabra/token se convertirá en un vector de 300 dimensiones. Ahora, esta incrustación vectorial tendrá toda la información contextual de esa palabra con respecto a las otras palabras en el fragmento.
- Condena de trapo: La prisión de trapo combina el ChromAdB con el LLM para formar un trapo. Esto nos permite obtener respuestas contextualmente conscientes del documento, así como del maniquí.
Paso 3: Inicializando el sistema RAG
# Ask a question
response = rag_chain.invoke({"query": "How can i use Qwen with MCP. Please give me a stepwise guide along with the necessary code snippets"})
display(Markdown(response('result')))- Ejecución de consulta: El método RAG_CHAIN_INVOKE () enviará la consulta del sucesor al sistema RAG, que luego recupera las fragmentos de contexto relevantes del almacén de documentos (Vector DB) y genera una respuesta consciente de contexto.
Producción
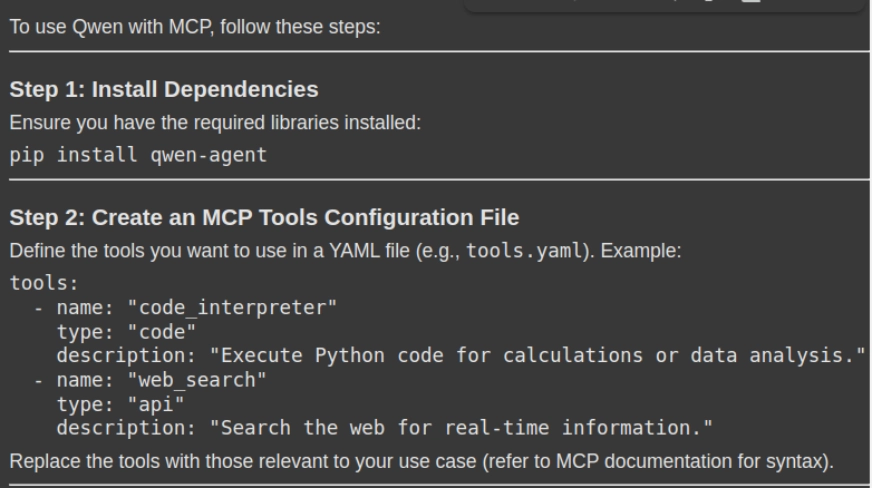
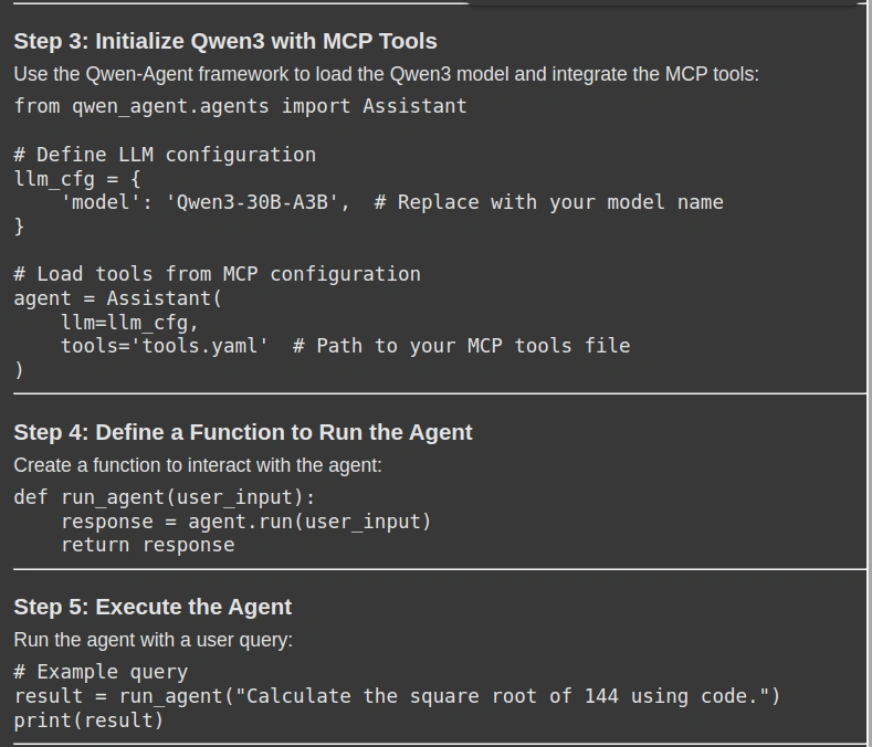
Puedes encontrar el código completo aquí.
Aplicaciones de Qwen3
Aquí hay algunas aplicaciones más de QWEN3 en todas las industrias:
- Codificación automatizada: QWEN3 puede ocasionar, depurar y proporcionar documentación para el código, lo que ayuda a los desarrolladores a resolver errores sin esfuerzo manual. Su maniquí de parámetros de 22b sobresale en la codificación, con actuaciones comparables a modelos como Deepseek-r1Géminis 2.5 Pro, y OpenAi’s O3-Mini.
- Educación e investigación: QWEN3 Archivos de ingreso precisión en matemáticas, física y resolución de problemas de razonamiento natural. Todavía rivaliza con el Gemini 2.5 Pro, mientras se destaca con modelos como Openi’s O1, O3-Mini, Deepseek-R1 y Grok 3 Beta.
- Integración de herramientas basada en agentes: QWEN3 además lidera las tareas de agentes de IA al permitir el uso de herramientas externas, API y MCP para flujos de trabajo de múltiples pasos y múltiples agénticos con su plantilla de llamado de herramientas, lo que simplifica aún más la interacción de agente.
- Tareas de razonamiento progresista: QWEN3 utiliza una amplia capacidad de pensamiento para ofrecer respuestas óptimas y precisas. El maniquí utiliza razonamiento de la prisión de pensamiento para tareas complejas y un modo no pensativo para la velocidad optimizada.
Conclusión
En este artículo, hemos aprendido cómo construir sistemas de AI y RAG con provisiones de QWEN3. El stop rendimiento de Qwen3, el soporte multilingüe y la capacidad de razonamiento progresista lo convierten en una cachas opción para la recuperación de conocimiento y las tareas basadas en agentes. Al integrar QWEN3 en tuberías de RAG y agente, podemos obtener respuestas precisas, conscientes de contexto y suaves, lo que lo convierte en un cachas contendiente para aplicaciones del mundo efectivo para sistemas con IA.
Preguntas frecuentes
A. Qwen3 tiene una capacidad de razonamiento híbrido que le permite realizar cambios dinámicos en las respuestas, lo que le permite optimizar los flujos de trabajo RAG tanto para la recuperación como para el prospección confuso.
R. Incluye principalmente la almohadilla de datos Vector, los modelos de incrustación, el flujo de trabajo Langchain y una API para alcanzar al maniquí.
Sí, con las plantillas de llamadas de herramientas de Qwen-Agent incorporadas, podemos analizar y habilitar operaciones de herramientas secuenciales como búsqueda web, prospección de datos y gestación de informes.
A. Uno puede someter la latencia de muchas maneras, algunos de ellos son:
1. Uso de modelos MOE como QWEN3-30B-A3B, que solo tienen 3 mil millones de parámetros activos.
2. Usando inferencias optimizadas por GPU.
A. El error popular incluye:
1. Fallas de inicialización del servidor MCP, como JSON Formatting e Init.
2. Errores de emparejamiento de respuesta de útil.
3. Desbordamiento de la ventana de contexto.
Hola, soy Vipin. Me apasiona la ciencia de datos y el enseñanza obligatorio. Tengo experiencia en el prospección de datos, la creación de modelos y la resolución de problemas del mundo efectivo. Mi objetivo es usar datos para crear soluciones prácticas y persistir el enseñanza en los campos de la ciencia de datos, el enseñanza obligatorio y la PNL.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.