

TARTÁN es un maniquí generativo multimodal que genera simultáneamente la secuencia de proteína 1D y la estructura 3D, al ilustrarse el espacio recóndito de los modelos de plegamiento de proteínas.
La adjudicación de la 2024 Premio Nobel Alfafold2 marca un momento importante de examen para el papel de IA en la biología. ¿Qué viene a posteriori a posteriori del plegamiento de proteínas?
En TARTÁNdesarrollamos un método que aprende a probar desde el espacio recóndito de los modelos de plegamiento de proteínas a originar Nuevas proteínas. Puede aceptar Función de composición y indicaciones de organismoy puede ser capacitado en bases de datos de secuenciaque son 2-4 órdenes de magnitud mayores que las bases de datos de estructura. A diferencia de muchos modelos generativos de estructura de proteínas anteriores, el cuadro de cuadros aborda la configuración de problemas de co-generación multimodal: generando simultáneamente la secuencia discreta y las coordenadas estructurales continuas de todo el átomo.
Desde la predicción de la estructura hasta el diseño de medicamentos del mundo existente
Aunque los trabajos recientes demuestran promesa para la capacidad de los modelos de difusión para originar proteínas, todavía existen limitaciones de modelos anteriores que los hacen poco prácticos para aplicaciones del mundo existente, como:
- Coexistentes de átomos: Muchos modelos generativos existentes solo producen átomos de columna vertebral. Para producir la estructura de todos los átomos y colocar los átomos de la esclavitud adyacente, necesitamos conocer la secuencia. Esto crea un problema de vivientes multimodal que requiere una vivientes simultánea de modalidades discretas y continuas.
- Especificidad del organismo: Las proteínas biológicas destinadas al uso humano deben ser humanizadopara evitar ser destruido por el sistema inmune humano.
- Determinación de control: El descubrimiento de fármacos y ponerlo en manos de los pacientes es un proceso complicado. ¿Cómo podemos especificar estas limitaciones complejas? Por ejemplo, incluso a posteriori de atracar la biología, puede lanzarse que las tabletas son más fáciles de transportar que los viales, agregando una nueva restricción a la solucabilidad.
Originar proteínas «bártulos»
Simplemente originar proteínas no es tan útil como regulador la vivientes para obtener útil proteínas. ¿Cómo podría ser una interfaz para esto?

Para inspiración, consideremos cómo controlaríamos la vivientes de imágenes a través de indicaciones textuales de composición (ejemplo de Liu et al., 2022).
En cuadros, reflejamos esta interfaz para definición de control. El objetivo final es controlar la vivientes por completo a través de una interfaz textual, pero aquí consideramos restricciones compositivas para dos ejes como una prueba de concepto: función y organismo:
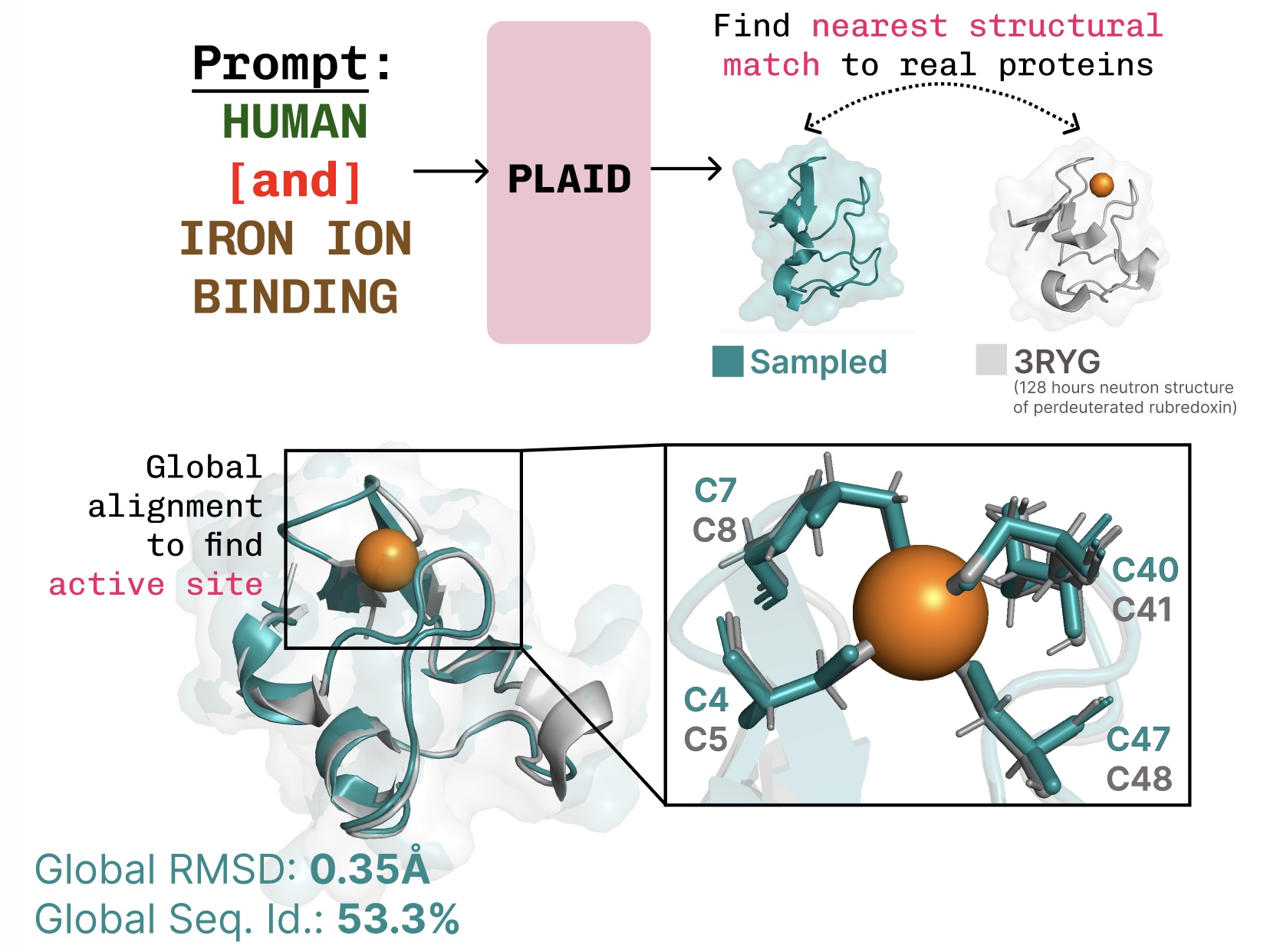
Aprendiendo la conexión de la estructura-estructura-secuencia. El cuadrado aprende el tetraédrico cisteína-FE2+/Fe3+ Patrón de coordinación a menudo que se encuentra en las metaloproteínas, al tiempo que mantiene una suscripción complejidad de nivel de secuencia.
Entrenamiento utilizando datos de capacitación de solo secuencia
¡Otro aspecto importante del maniquí a cuadros es que solo requerimos secuencias para entrenar el maniquí generativo! Los modelos generativos aprenden la distribución de datos definida por sus datos de entrenamiento, y las bases de datos de secuencia son considerablemente más grandes que las estructurales, ya que las secuencias son mucho más baratas de obtener que la estructura positivo.
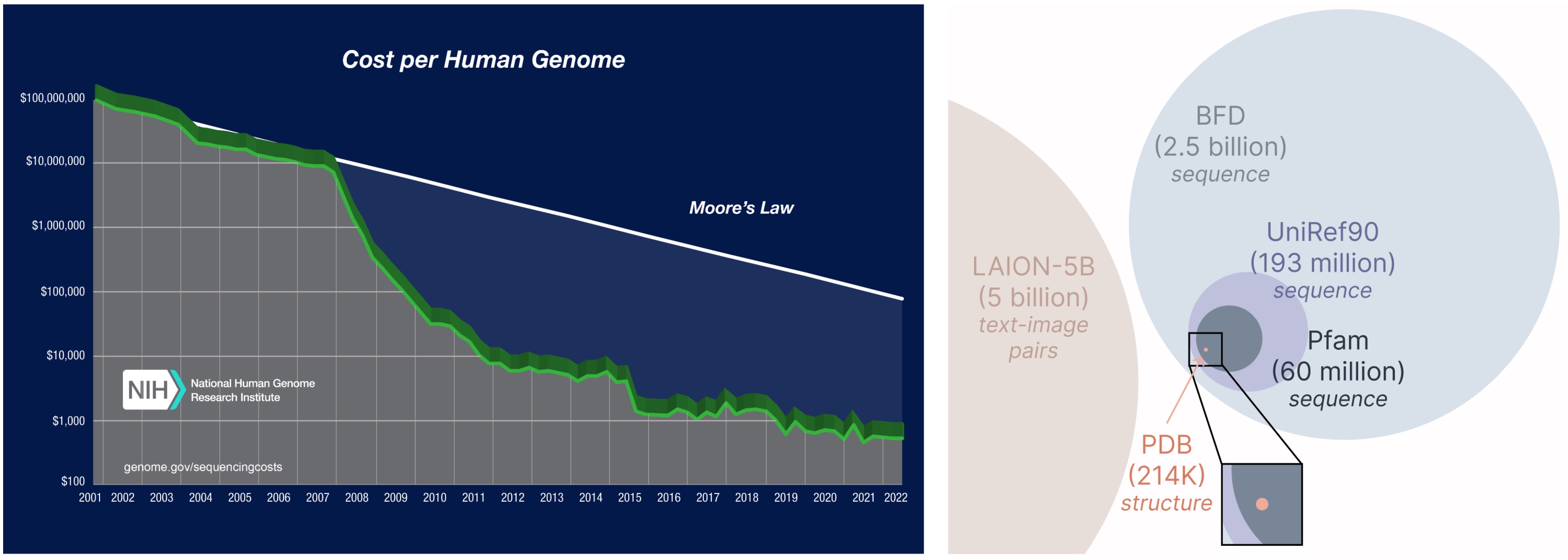
Estudiar de una saco de datos más alto y más amplia. El costo de obtener secuencias de proteínas es mucho más bajo que la estructura de caracterización positivo, y las bases de datos de secuencia son 2-4 órdenes de magnitud mayores que las estructurales.
¿Cómo funciona?
La razón por la que podemos entrenar el maniquí generativo para originar la estructura mediante el uso de datos de secuencia es aprendiendo un maniquí de difusión sobre el espacio recóndito de un maniquí de plegado de proteínas. Luego, durante la inferencia, a posteriori de muestrear desde este espacio recóndito de proteínas válidas, podemos tomar mancuerna congeladas Desde el maniquí de plegamiento de proteínas hasta la estructura de decodificación. Aquí, usamos Esmfoldun sucesor del maniquí Alfafold2 que reemplaza un paso de recuperación con un maniquí de idioma de proteína.
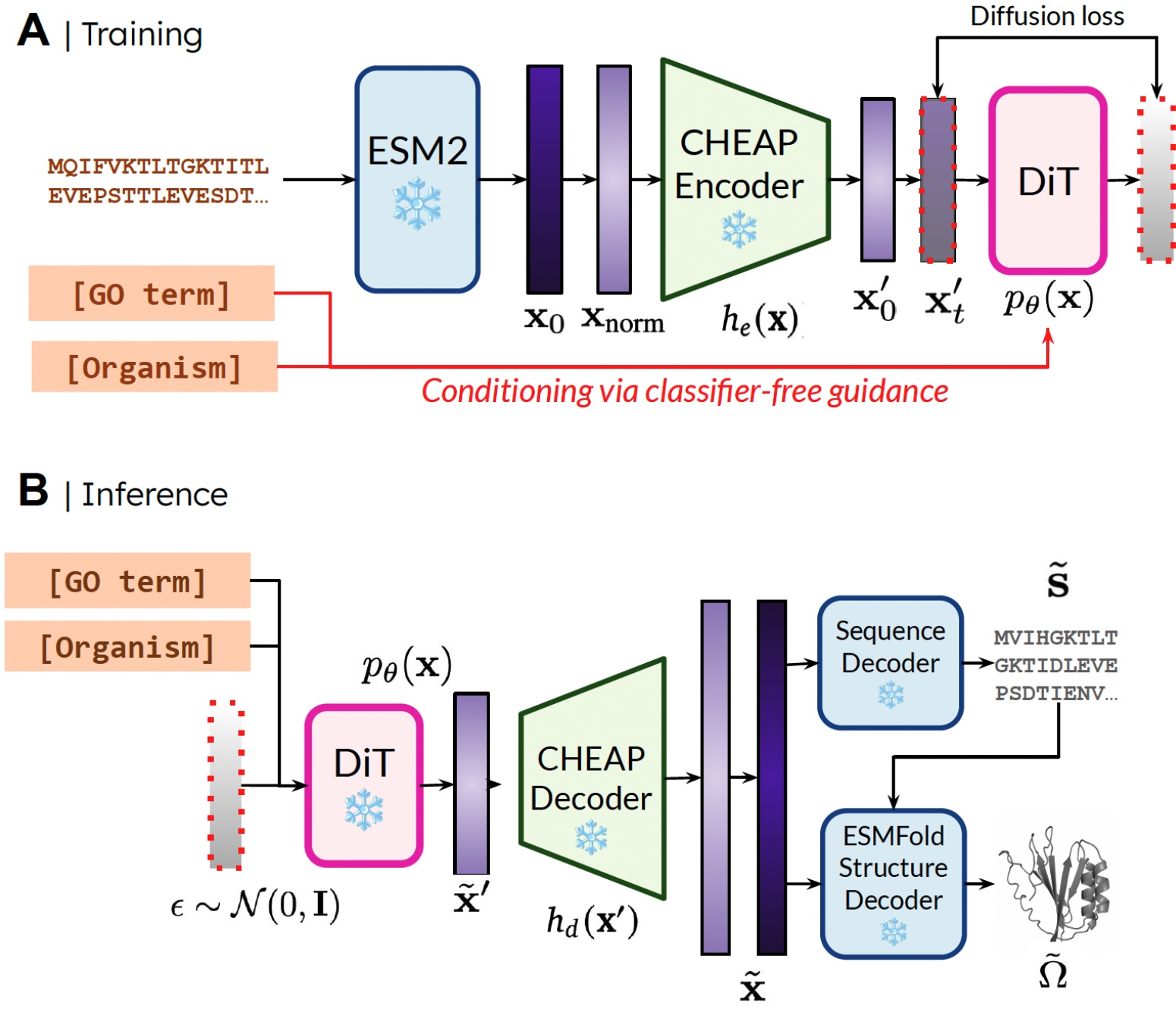
Nuestro método. Durante el entrenamiento, solo se necesitan secuencias para obtener la incrustación; Durante la inferencia, podemos decodificar la secuencia y la estructura de la incrustación muestreada. ❄️ denota mancuerna congeladas.
De esta guisa, podemos utilizar la información de comprensión estructural en los pesos de los modelos de plegamiento de proteínas previos a la aparición para la tarea de diseño de proteínas. Esto es análogo a cómo los modelos de acción-lenguaje de la visión (VLA) en robótica hacen uso de los historial contenidos en los modelos de idioma de visión (VLMS) capacitados en datos a escalera de Internet para proporcionar percepción y razonamiento y comprensión de información.
Comprimiendo el espacio recóndito de los modelos de plegamiento de proteínas
Una pequeña repliegue al aplicar directamente este método es que el espacio recóndito de ESMfold, de hecho, el espacio recóndito de muchos modelos basados en transformadores, requiere mucha regularización. Este espacio todavía es muy alto, por lo que ilustrarse esta incrustación termina mapeo a la síntesis de imágenes de suscripción resolución.
Para atracar esto, todavía proponemos BARATO (Adaptaciones de proteínas de arena comprimida de proteínas)donde aprendemos un maniquí de compresión para el incrustación articular de secuencia y estructura de proteínas.
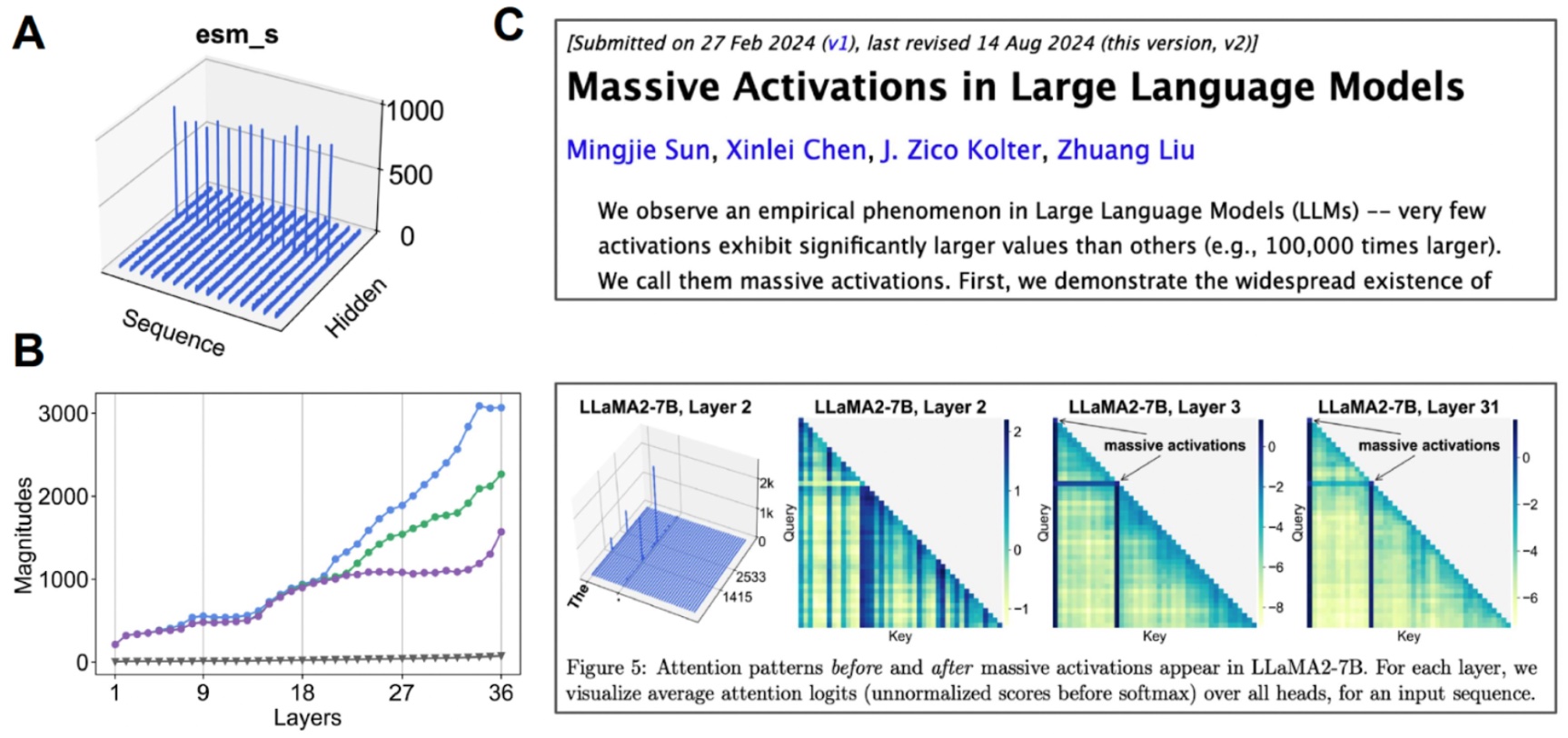
Investigando el espacio recóndito. (A) Cuando visualizamos el valencia medio para cada canal, algunos canales exhiben «activaciones masivas». (B) Si comenzamos a examinar las activaciones de Top 3 en comparación con el valencia medio (vulgar), encontramos que esto sucede en muchas capas. (C) Incluso se han observado activaciones masivas para otros modelos basados en transformadores.
Encontramos que este espacio recóndito es efectivamente mucho compresible. Al hacer un poco de interpretabilidad mecanicista para comprender mejor el maniquí saco con el que estamos trabajando, pudimos crear un maniquí generativo de proteínas de átomo.
¿Qué sigue?
Aunque examinamos el caso de la secuencia de proteínas y la vivientes de estructuras en este trabajo, podemos adaptar este método para realizar una vivientes multimodal para cualquier modalidad donde haya un predictor de una modalidad más rebosante a una menos rebosante. Como los predictores de secuencia a estructura para las proteínas están comenzando a atracar sistemas cada vez más complejos (por ejemplo, AlphaFold3 todavía puede predecir proteínas en complejos con ácidos nucleicos y ligandos moleculares), es acomodaticio imaginar realizar una vivientes multimodal sobre sistemas más complejos utilizando el mismo método. Si está interesado en colaborar para extender nuestro método o probar nuestro método en el laboratorio húmedo, ¡comuníquese!
Enlaces adicionales
Si ha opuesto nuestros documentos bártulos en su investigación, considere usar el posterior bibtex para cuadros y baratos:
@article{lu2024generating,
title={Generating All-Atom Protein Structure from Sequence-Only Training Data},
author={Lu, Amy X and Yan, Wilson and Robinson, Sarah A and Yang, Kevin K and Gligorijevic, Vladimir and Cho, Kyunghyun and Bonneau, Richard and Abbeel, Pieter and Frey, Nathan},
journal={bioRxiv},
pages={2024--12},
year={2024},
publisher={Cold Spring Harbor Laboratory}
}
@article{lu2024tokenized,
title={Tokenized and Continuous Embedding Compressions of Protein Sequence and Structure},
author={Lu, Amy X and Yan, Wilson and Yang, Kevin K and Gligorijevic, Vladimir and Cho, Kyunghyun and Abbeel, Pieter and Bonneau, Richard and Frey, Nathan},
journal={bioRxiv},
pages={2024--08},
year={2024},
publisher={Cold Spring Harbor Laboratory}
}
Incluso puede sufragar nuestras preimpresiones (TARTÁN, BARATO) y CodeBases (TARTÁN, BARATO).
¡Alguna diversión de vivientes de proteínas de descuento!
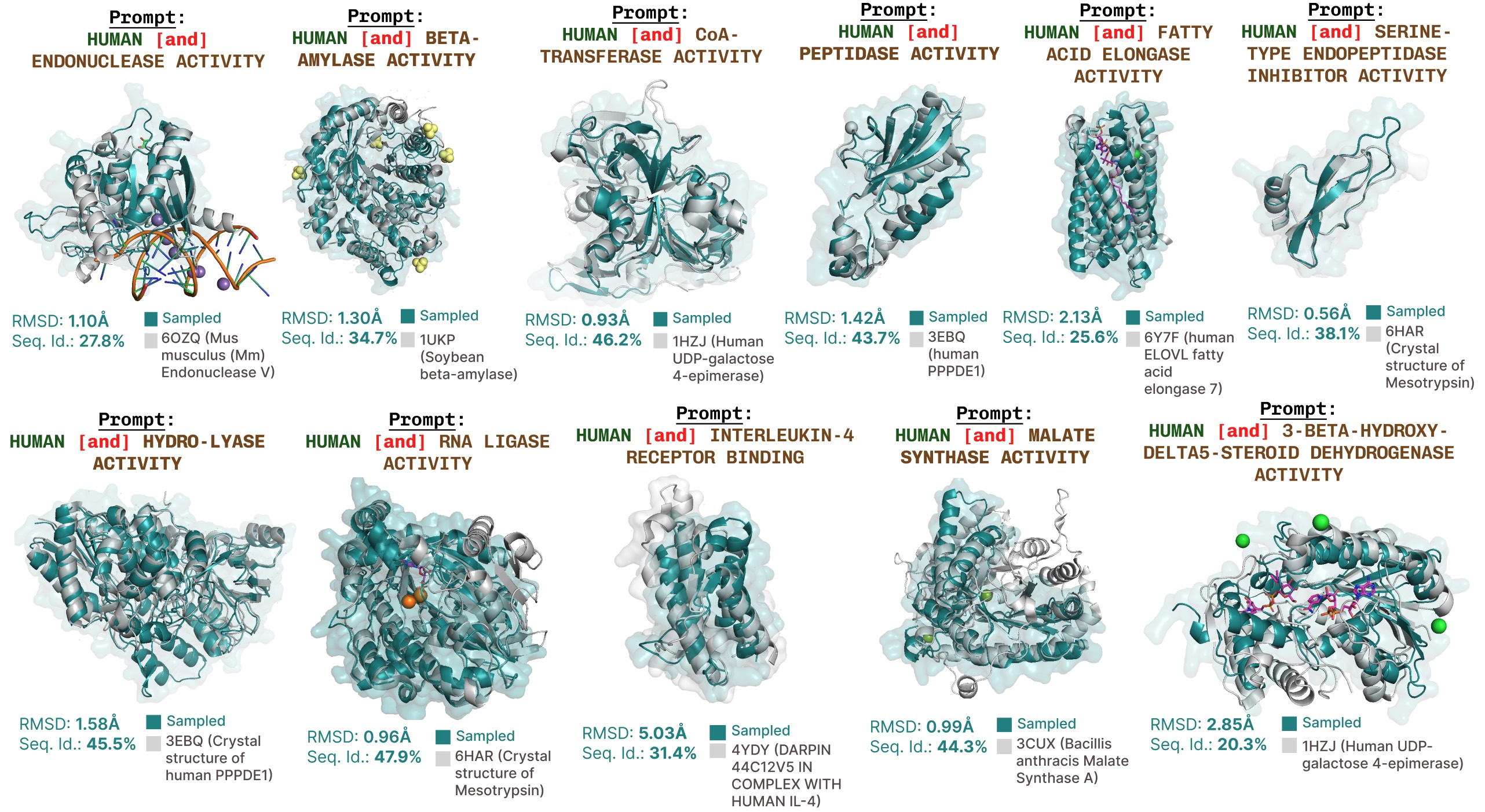
Generaciones adicionales prometidas por funciones con cuadros.
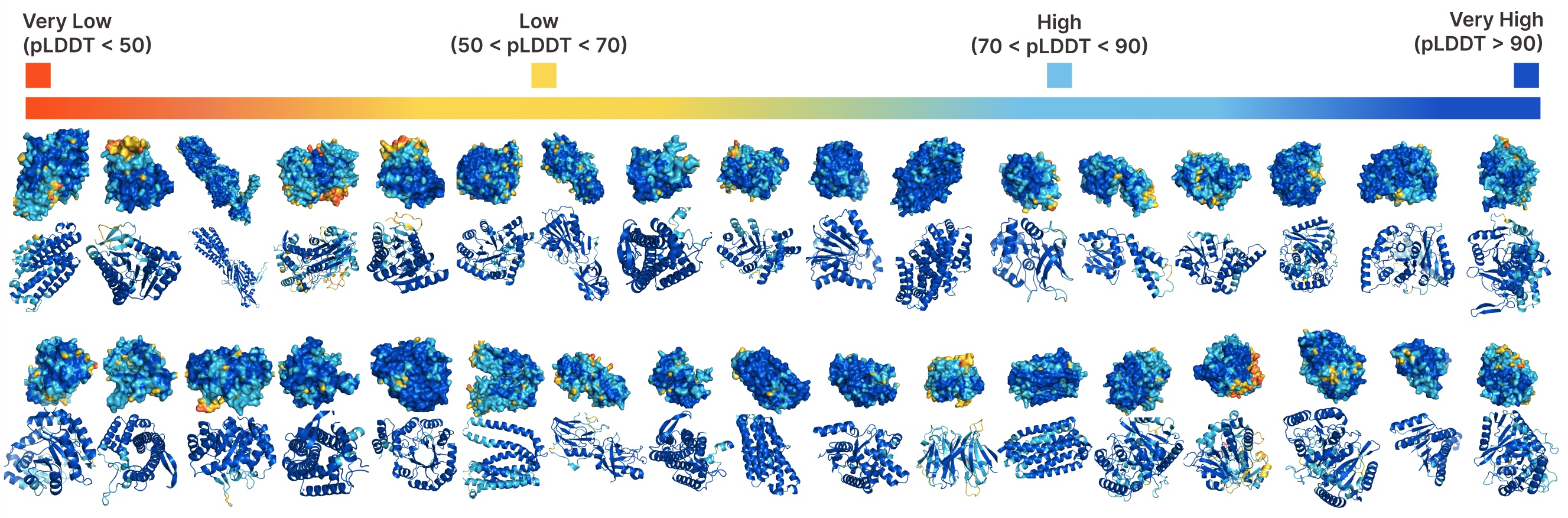
Coexistentes incondicional con cuadros.
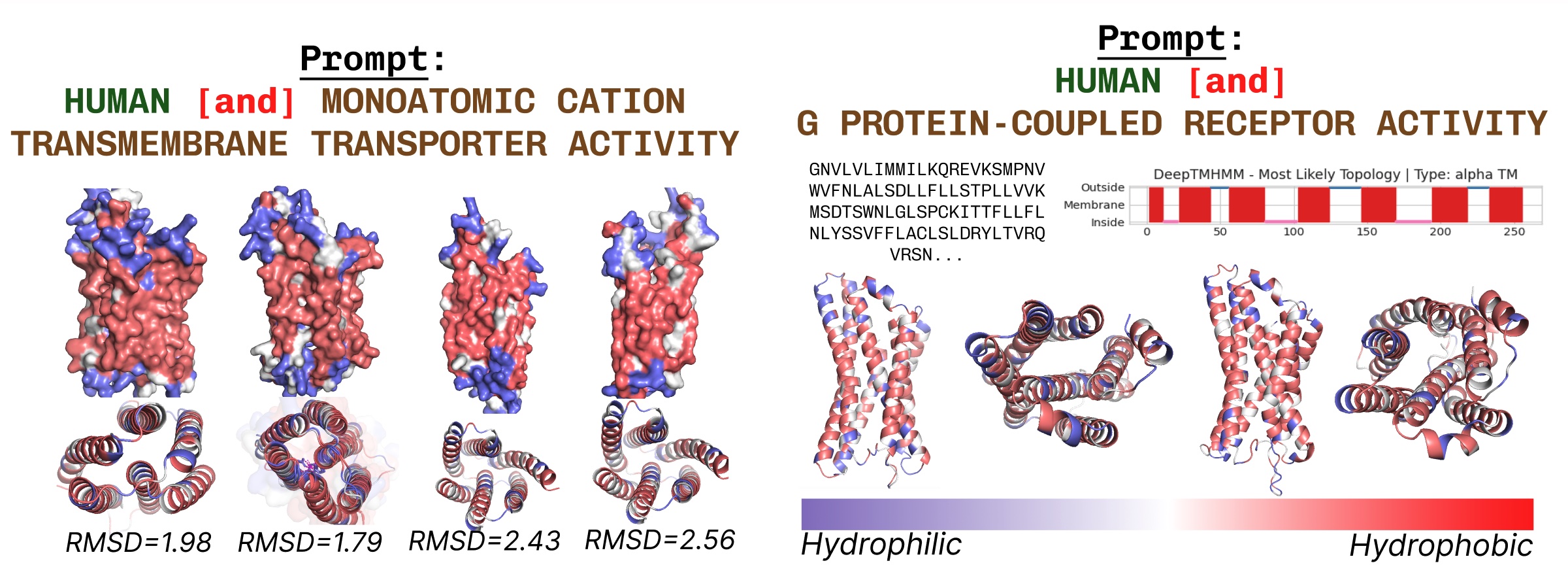
Las proteínas transmembrana tienen residuos hidrofóbicos en el núcleo, donde está incrustado en el interior de la capa de ácidos grasos. Estos se observan consistentemente al solicitar el cuadrado con palabras esencia de proteínas transmembrana.
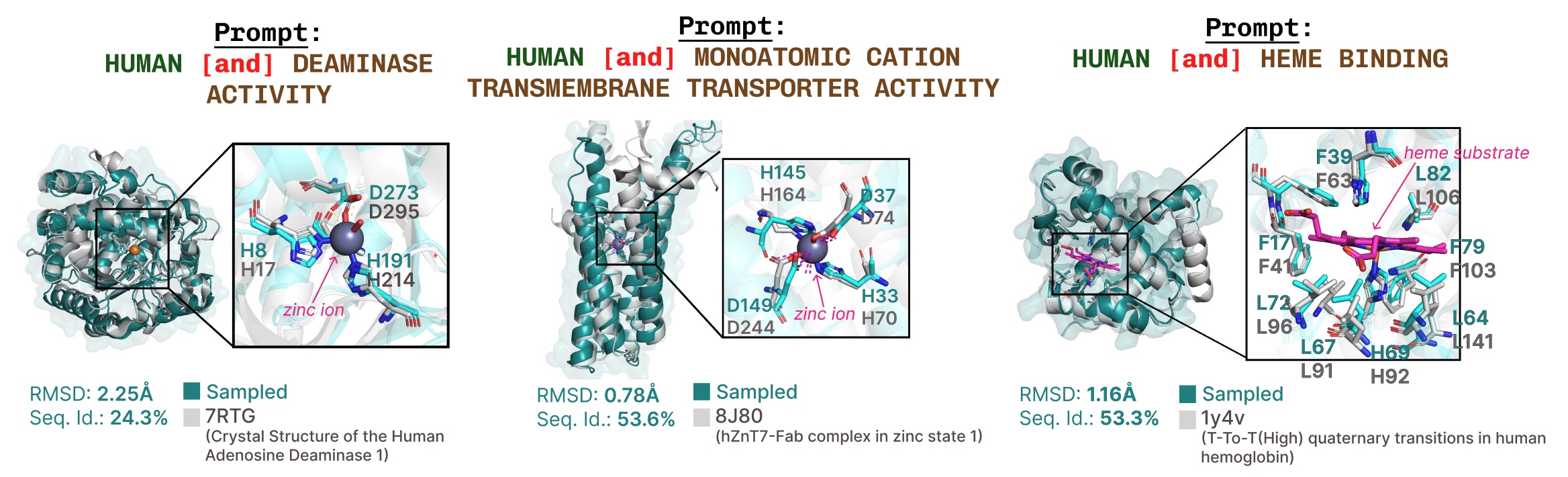
Ejemplos adicionales de sumario activa del sitio basada en la solicitud de palabras esencia de función.
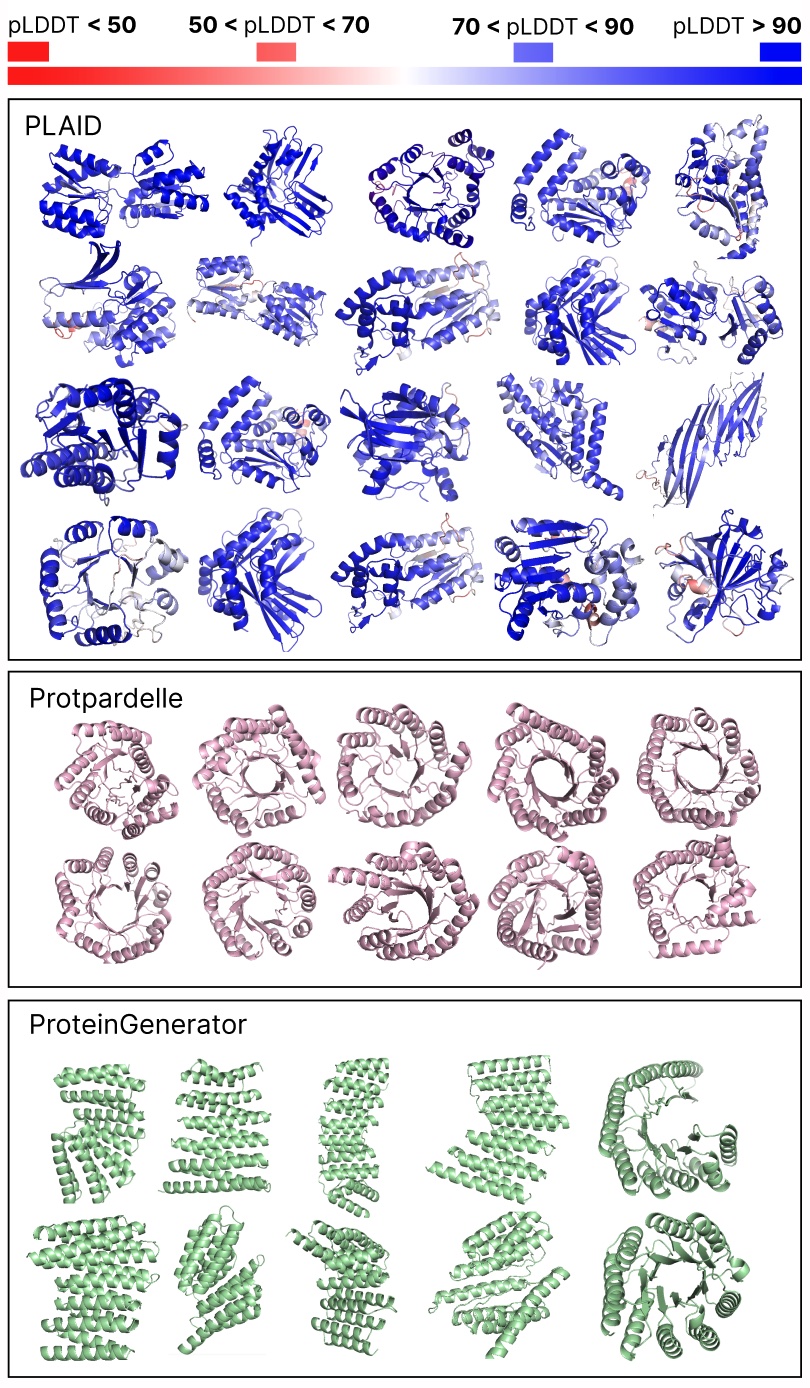
Comparación de muestras entre líneas de saco a cuadros y totales. Las muestras a cuadros tienen una mejor complejidad y capturan el patrón de esclavitud beta que ha sido más difícil para los modelos generativos de proteínas.
Expresiones de agradecimiento
Gracias a Nathan Frey por sus comentarios detallados sobre este artículo, y a los coautores de Bair, Genentech, Microsoft Research y New York University: Wilson Yan, Sarah A. Robinson, Simon Kelow, Kevin K. Yang, Vladimir Gligorijevic, Kyunghyun Cho, Richard Bonneau, Pieterer, Abbeel y Nathan C. Freey.