
Estamos entusiasmados de compartir los primeros modelos en el boyada Lumbre 4 están disponibles hoy en Azure Ai Foundry y Azure Databricks, que permite a las personas construir experiencias multimodales más personalizadas. Estos modelos de Meta están diseñados para integrar a la perfección los tokens de texto y visión en una columna vertebral de maniquí unificado. Este enfoque reformador permite a los desarrolladores beneficiarse los modelos LLAMA 4 en aplicaciones que exigen grandes cantidades de datos de texto, imagen y video no etiquetados, estableciendo un nuevo precedente en el crecimiento de IA.
Estamos entusiasmados de compartir los primeros modelos en el boyada de Lumbre 4 están disponibles hoy en Azure ai fundición y Azure Databricksque permite a las personas construir experiencias multimodales más personalizadas. Estos modelos de Meta están diseñados para integrar a la perfección los tokens de texto y visión en una columna vertebral de maniquí unificado. Este enfoque reformador permite a los desarrolladores beneficiarse los modelos LLAMA 4 en aplicaciones que exigen grandes cantidades de datos de texto, imagen y video no etiquetados, estableciendo un nuevo precedente en el crecimiento de IA.
Hoy, estamos trayendo modelos de Scout y Maverick de Meta’s Lumbre 4 a Azure Ai Foundry como ofertas de cuenta administrados:
- Lumbre 4 Scout Models
- Lumbre-4-Scout-17b-16E
- Lumbre-4-Scout-17b-16E-Instructo
- Lumbre 4 Modelos Maverick
- Lumbre 4-Maverick-17B-128E-Instructo-FP8
Azure AI Foundry está diseñado para casos de uso de múltiples agentes, lo que permite una colaboración perfecta entre diferentes agentes de IA. Esto abre nuevas fronteras en aplicaciones de IA, desde la resolución de problemas complejas hasta la mandato de tareas dinámicas. Imagine un equipo de agentes de IA que trabajan juntos para analizar grandes conjuntos de datos, difundir contenido creativo y proporcionar información en tiempo actual en múltiples dominios. Las posibilidades son infinitas.
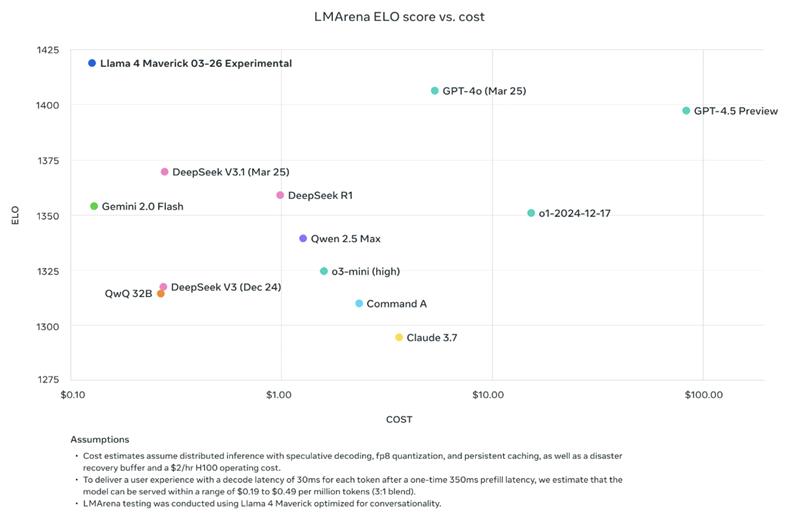
Para acomodar una variedad de casos de uso y deyección de desarrollador, los modelos LLAMA 4 vienen en opciones cada vez más grandes. Estos modelos integran mitigaciones en cada capa de crecimiento, desde la capacitación previa hasta el post-entrenamiento. Las mitigaciones de nivel de sistema sintonizables protegen a los desarrolladores de usuarios adversos, capacitándolos para crear experiencias efectos, seguras y adaptables para sus aplicaciones respaldadas por LLAMA.
Lumbre 4 Scout Models: Power and Precision
Estamos compartiendo los primeros modelos en el boyada Lumbre 4, que permitirá a las personas construir experiencias multimodales más personalizadas. Según Meta, Lumbre 4 Scout es uno de los mejores modelos multimodales de su clase y es más poderoso que los modelos Lumbre 3 de Meta, mientras se ajustan en una sola GPU H100. Y LLAMA4 Scout aumenta la duración del contexto compatible de 128K en LLAMA 3 a 10 millones de tokens líderes en la industria. Esto abre un mundo de posibilidades, incluida la epítome de documentos múltiples, analizando una amplia actividad del sucesor para tareas personalizadas y razonamiento sobre vastas bases de código.
Los casos de uso dirigido incluyen epítome, personalización y razonamiento. Gracias a su derrochador contexto y tamaño efectivo, Lumbre 4 Scout brilla en tareas que requieren condensación o exploración de información extensa. Puede difundir resúmenes o informes de entradas extremadamente largas, personalizar sus respuestas utilizando datos detallados específicos del sucesor (sin olvidar detalles anteriores) y realizar un razonamiento engorroso en grandes conjuntos de conocimientos.
Por ejemplo, Scout podría analizar todos los documentos en una biblioteca empresarial de SharePoint para objetar una consulta específica o deletrear un manual técnico de miles de páginas para proporcionar asesoramiento de problemas. Está diseñado para ser un «Scout» diligente que atraviesa una gran información y devuelve los aspectos más destacados o respuestas que necesita.
Lumbre 4 Modelos Maverick: Innovación a escalera
Como LLM de propósito común, Lumbre 4 Maverick contiene 17 mil millones de parámetros activos, 128 expertos y 400 mil millones de parámetros totales, ofreciendo ingreso calidad a un precio más bajo en comparación con LLAMA 3.3 70B. Maverick sobresale en la comprensión de la imagen y el texto con soporte para 12 idiomas, lo que permite la creación de aplicaciones de IA sofisticadas que unen las barreras del idioma. Maverick es ideal para la comprensión precisa de las imágenes y la escritura creativa, lo que lo hace admisiblemente adecuado para los casos de uso común de asistentes y chat. Para los desarrolladores, ofrece inteligencia de última procreación con ingreso velocidad, optimizada para la mejor calidad y tono de respuesta.
Los casos de uso dirigidos incluyen escenarios de chat optimizados que requieren respuestas de ingreso calidad. Meta Maverick Maverick para ser un excelente agente de conversación. Es el maniquí de chat insignia de la comunidad Meta Lumbre 4, piense en él como la contraparte multilingüe multimodal de un asistente de chatgpt.
Es particularmente adecuado para aplicaciones interactivas:
- Bots de atención al cliente que necesitan comprender las imágenes que los usuarios cargan.
- AI Socios creativos que pueden discutir y difundir contenido en varios idiomas.
- Asistentes empresariales internos que pueden ayudar a los empleados respondiendo preguntas y manejando aportes de medios ricos.
Con Maverick, las empresas pueden construir asistentes de IA de ingreso calidad que conversan lógicamente (y cortésmente) con una almohadilla de usuarios total y beneficiarse el contexto visual cuando sea necesario.
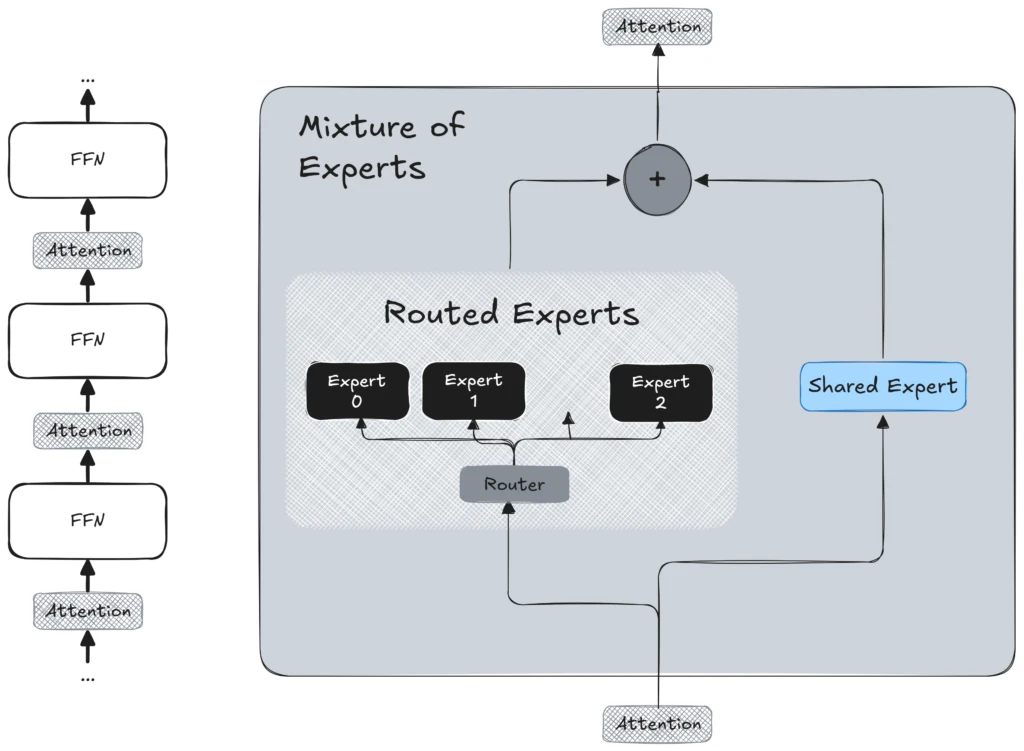
Architectural Innovations in Lumbre 4: Multimodal fusión temprana y MOE
Según Meta, dos innovaciones secreto aparecen a Lumbre 4: soporte multimodal nativo con fusión temprana y una mezcla escasa de diseño de expertos (MOE) para eficiencia y escalera.
- Transformador multimodal de fusión temprana: Lumbre 4 utiliza un enfoque de fusión temprana, tratando el texto, las imágenes y los marcos de video como una secuencia única de tokens desde el principio. Esto permite que el maniquí comprenda y genere varios medios juntos. Se destaca en tareas que involucran múltiples modalidades, como analizar documentos con diagramas o objetar preguntas sobre la transcripción y las imágenes de un video. Para las empresas, esto permite a los asistentes de IA procesar informes completos (texto + gráficos + fragmentos de video) y proporcionar resúmenes o respuestas integradas.
- Mezcla de vanguardia de la obra de expertos (MOE): Para obtener un buen rendimiento sin incurrir en gastos de computación prohibitivos, Lumbre 4 utiliza una mezcla escasa de obra de expertos (MOE). Esencialmente, esto significa que el maniquí comprende numerosos submodelos de expertos, denominados «expertos», con solo un pequeño subconjunto activo para cualquier token de entrada poliedro. Este diseño no solo mejoramiento la eficiencia del entrenamiento, sino que todavía mejoramiento la escalabilidad de la inferencia. En consecuencia, el maniquí puede manejar más consultas simultáneamente distribuyendo la carga computacional en varios expertos, permitiendo la implementación en entornos de producción sin faltar grandes GPU de una sola instancia. La Bloque MoE permite a LLAMA 4 expandir su capacidad sin aumentar los costos, ofreciendo una superioridad significativa para las implementaciones empresariales.
Compromiso con la seguridad y las mejores prácticas
Meta Built Lumbre 4 con las mejores prácticas descritas en su Consejero de uso del desarrollador: protecciones de IA. Esto incluye la integración de mitigaciones en cada capa de crecimiento del maniquí desde la capacitación previa hasta las mitigaciones de nivel posterior a la capacitación y sintonizables que protegen a los desarrolladores de los ataques adversos. Y, al hacer que estos modelos estén disponibles en Azure Ai Foundry, vienen con comprobados que los desarrolladores de barandas de seguridad esperan de Azure.
Empoderamos a los desarrolladores para crear experiencias efectos, seguras y adaptables para sus aplicaciones respaldadas por LLAMA. Explore los modelos Lumbre 4 ahora en el Azure AI Catálogo de modelos de fundición y en Azure Databricks Y comience a construir con lo postrer en IA multimodal con motor MOE, respaldada por la investigación de Meta y la fuerza de la plataforma de Azure.
La disponibilidad de metalama 4 en Azure ai fundición y Azure Databricks Ofrece a los clientes una flexibilidad incomparable para designar la plataforma que mejor se adapte a sus deyección. Esta integración perfecta permite a los usuarios beneficiarse las capacidades avanzadas de IA, mejorando sus aplicaciones con soluciones potentes, seguras y adaptables. Estamos emocionados de ver lo que construye a continuación.