
Cuando pensamos en casos de uso como recomendaciones de productos, predicciones de rotación, atribución publicitaria y detección de fraude, un denominador global es que todos requieren que identifiquemos constantemente a nuestros clientes en varias interacciones. No explorar que la misma persona está navegando en ringlera, comprando en la tienda, abriendo un correo electrónico de marketing y haciendo clic en un anuncio, nos deja con una visión incompleta del cliente, limitando nuestra capacidad de explorar sus evacuación, preferencias y predecir su comportamiento futuro.
A pesar de su importancia, identificar con precisión al cliente a través de estas interacciones es increíblemente difícil. Las personas a menudo interactúan con nosotros sin proporcionar detalles de identificación explícitos, y cuando lo hacen, esos detalles no siempre son consistentes. Por ejemplo, si un cliente realiza una transacción usando una polímero de crédito bajo el nombre de Jennifer, se registra para el software de fidelización como Jenny con un correo electrónico personal y hace clic en un anuncio en ringlera vinculado a su correo electrónico de trabajo, estas interacciones pueden aparecer como tres clientes separados, aunque todos pertenecen a la misma persona (Figura 1).
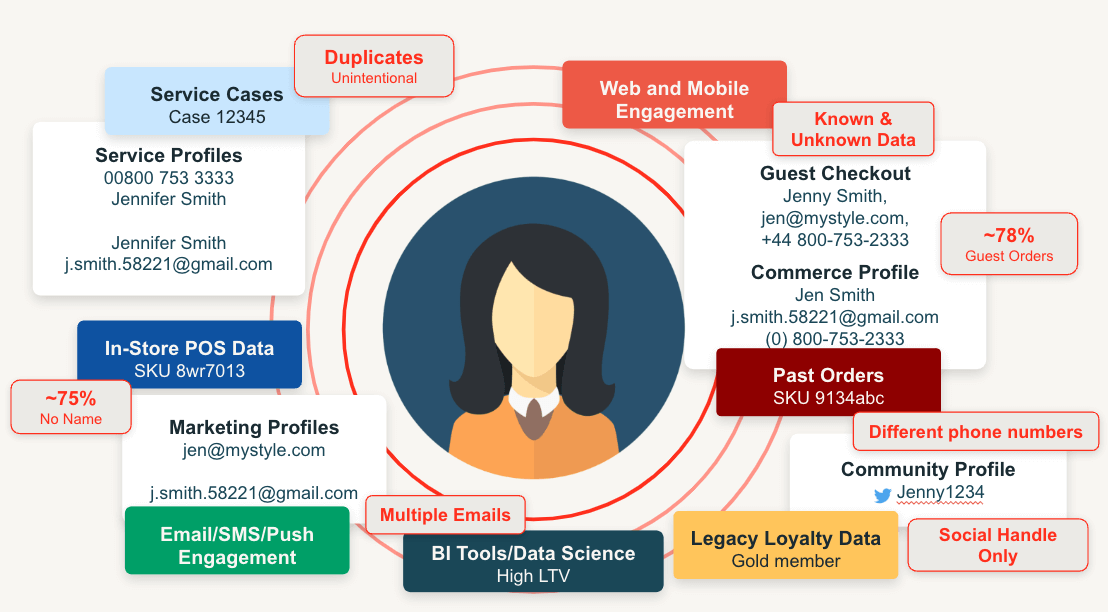
Si proporcionadamente resolver esto para un solo cliente es un desafío, la verdadera complejidad radica en abordarlo durante cientos de miles, o incluso millones, de clientes únicos con los que los minoristas se involucran continuamente. Adicionalmente, los detalles del cliente no son estáticos, como surgen nuevos comportamientos, identificadores y relaciones domésticas, nuestra comprensión de quién es el cliente asimismo debe continuar evolucionando.
Resolución de identidad (IDR) es el término que usamos para describir las técnicas utilizadas para unir todos estos detalles para conmover a una paisaje unificada de cada cliente. El IDR efectivo es crítico, ya que permite y afecta todos nuestros procesos centrados en los clientes, como el marketing personalizado, por ejemplo.
Comprender el proceso de resolución de identidad
En muchos escenarios, la identidad del cliente se establece a través de datos que referimos como información de identificación personal (PII). Los nombres, los apellidos, las direcciones postales, las direcciones de correo electrónico, los números de teléfono, los números de cuenta, etc. son todos los bits comunes de PII recopilados a través de las interacciones de nuestros clientes.
Usando bits superpuestos de PII, podríamos intentar coincidir y fusionar algunos registros diferentes para un individuo, sin incautación, hay diferentes grados de incertidumbre permitidos dependiendo del tipo de PII. Por ejemplo, podríamos usar técnicas de normalización para direcciones de correo electrónico tipadas incorrectamente o números de teléfono, y técnicas de combinación difusa para variaciones de nombre (por ejemplo, Jennifer vs Jenny vs Jen) (Figura 2).

Sin incautación, a menudo hay situaciones en las que no tenemos PII superpuesto. Por ejemplo, un cliente puede activo proporcionado su nombre y dirección postal un registro, su nombre y dirección de correo electrónico con otro, y un número de teléfono y esa misma dirección de correo electrónico en un tercer registro. A través de la asociación, podríamos deducir que todas son la misma persona, dependiendo de nuestra tolerancia a la incertidumbre (Figura 3).
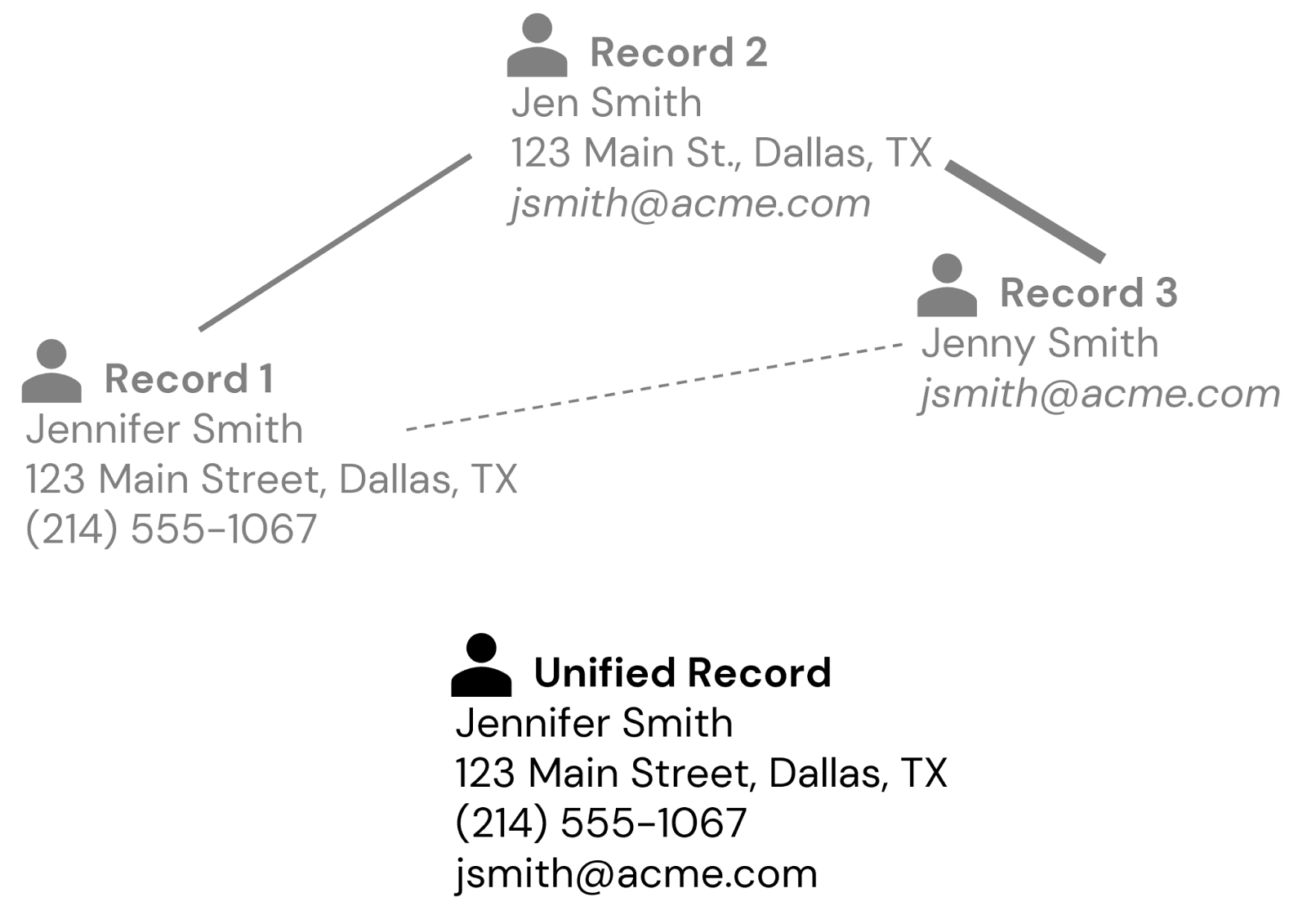
El núcleo del proceso IDR radica en vincular registros mediante la combinación de reglas de coincidencia exactas y técnicas de coincidencia difusa, adaptadas a diferentes fundamentos de datos, para establecer una identidad de cliente unificada. El resultado es una comprensión probabilística de quiénes son sus clientes que evoluciona a medida que se recopilan y entretejes nuevos detalles en el descriptivo de identidad.
Construyendo el descriptivo de identidad
El desafío de construir y persistir un descriptivo de identidad del cliente se hace más acomodaticio a través de la integración de Databricks con el motor de resolución de identidad de Amperidad. Ampliamente obligado como la primera posibilidad IDR de primera parte del mundo, Amperity aprovecha más de 45 algoritmos para que coincidan y fusionen los registros de clientes. La integración de liderazgo permite a los clientes de Databricks compartir sin problemas sus datos con amperidad y obtener ideas detalladas sobre cómo una colección de registros de clientes resuelve a las identidades unificadas. (Figura 4).
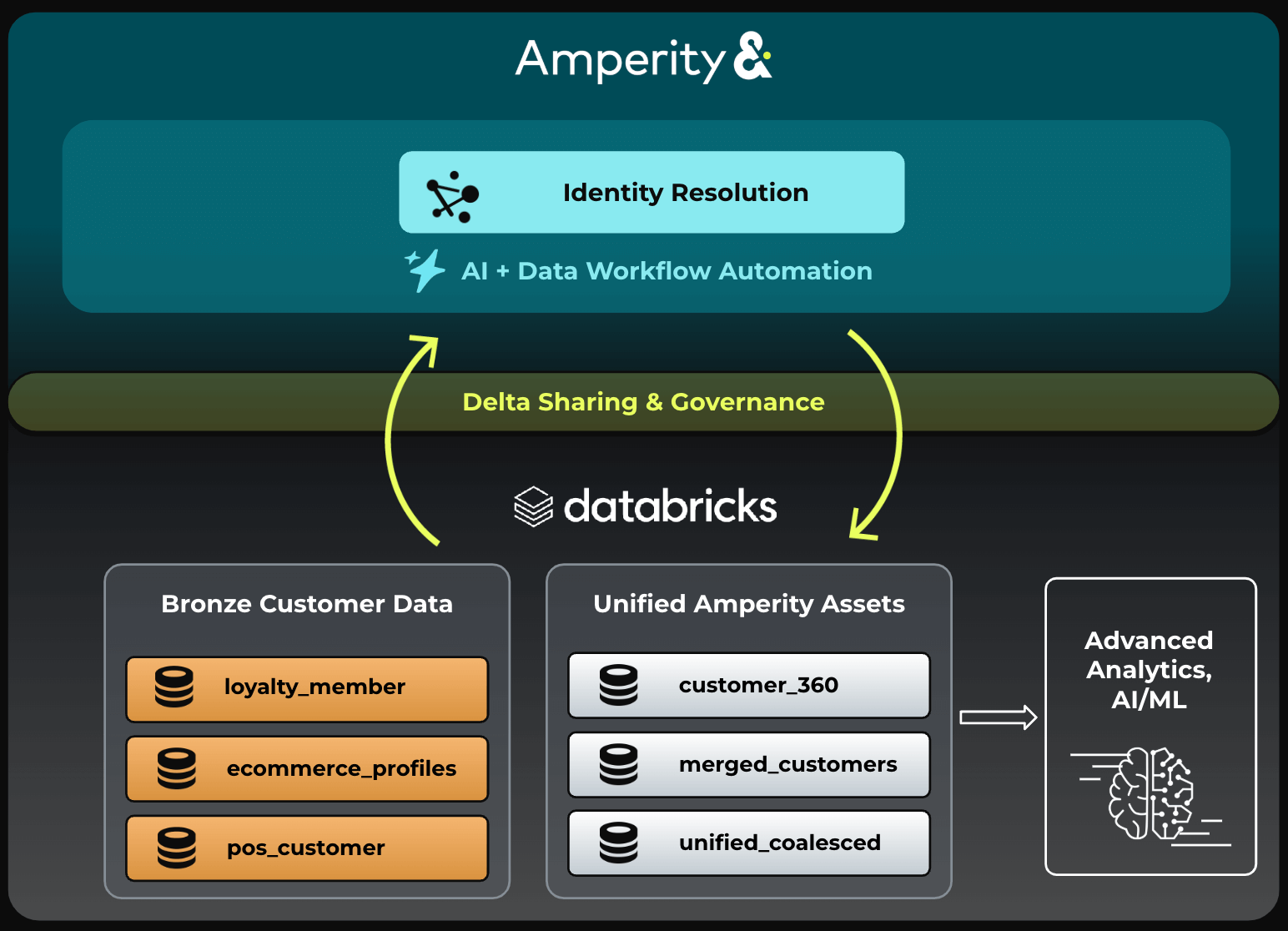
El proceso de configuración de esta integración y ejecución de IDR en Amperidad es muy sencillo:
- Configuración de una conexión Delta Compartir con Databricks a través del Amperity Bridge
- Use la automatización de IA para etiquetar varios fundamentos PII en los datos compartidos
- Ejecute el operación de puntada de amperidad para ensamblar el descriptivo IDR
- Mapee la salida resultante a un catálogo de Databricks
- Actualice el descriptivo según sea necesario
Se puede encontrar una breviario detallada de estos pasos en el Timonel de resolución de identidad de amperidady se puede ver un tutorial de video del proceso aquí:
Empleando el descriptivo de identidad
El resultado final de la integración es un conjunto de tablas relacionadas que incluyen fundamentos y sugerencias de clientes unificados para la información de identidad preferida para cada cliente (Figura 5).
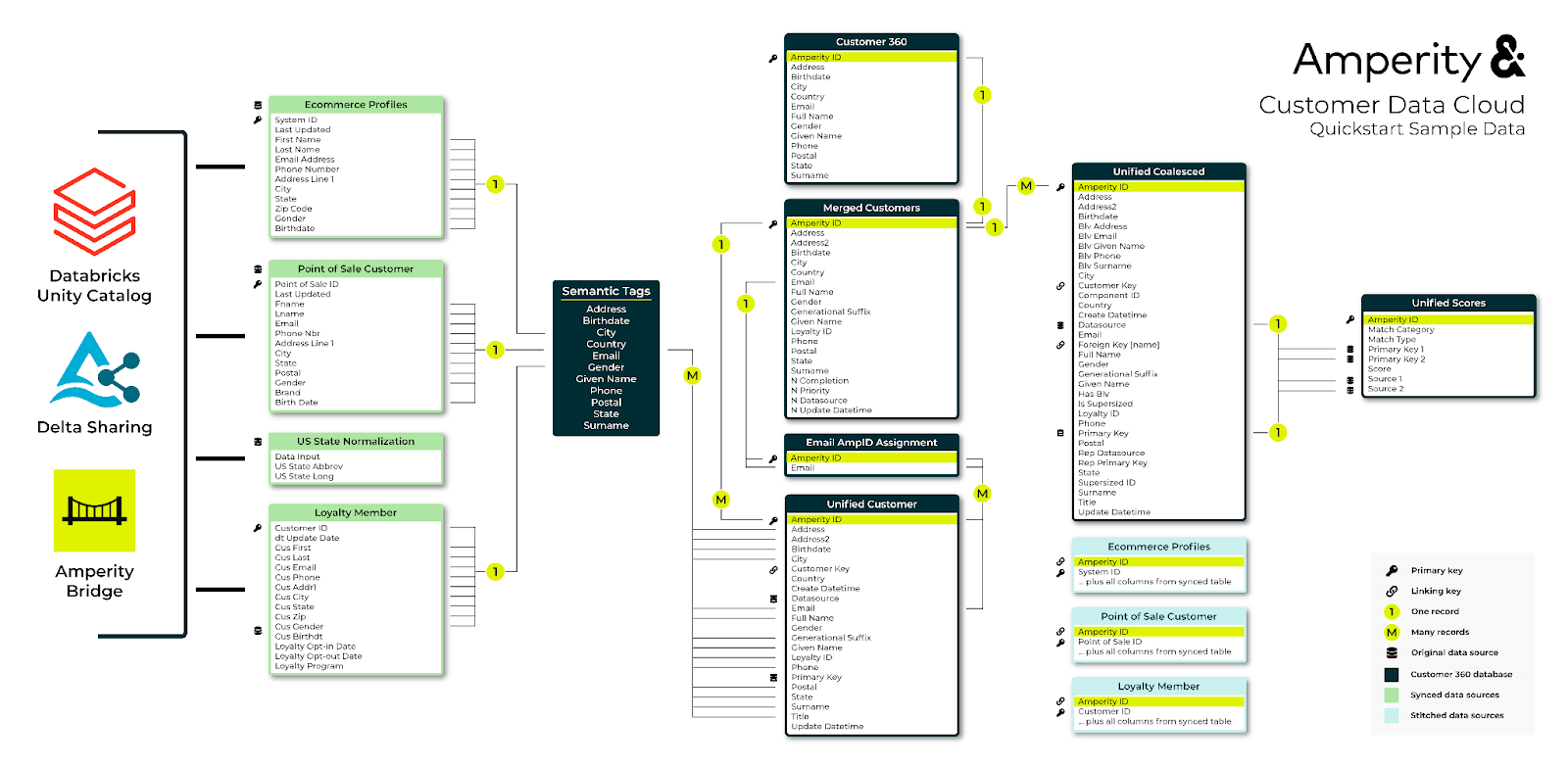
Los ingenieros de datos, los científicos de datos, los desarrolladores de aplicaciones pueden usar los datos resultantes en Databricks para construir una amplia escala de soluciones para atracar las evacuación y casos de uso empresariales comunes:
- Información del cliente: Poder vincular los registros de datos de los clientes, tanto internas como externas, las organizaciones pueden desarrollar ideas más profundas y precisas sobre los comportamientos y preferencias del cliente.
- Marketing y experiencias personalizadas: Utilizando esas ideas y estar en mejores condiciones para identificar a los clientes a medida que involucran varias plataformas, las organizaciones pueden entregar mensajes y ofertas más específicos, creando una experiencia más personalizada.
- Surtido del producto: Con una imagen más precisa de quién está comprando qué, las organizaciones pueden perfilar mejor la demografía de sus clientes en ubicaciones específicas y crear surtidos de productos más propensos a resonar con la población que se sirve.
- Colocación de la tienda: Esas mismas ideas demográficas pueden ayudar a las organizaciones a evaluar el potencial de las nuevas ubicaciones de las tiendas, identificando áreas donde residen clientes como aquellos que han participado con éxito en otras regiones.
- Detección de fraude: Al desarrollar una imagen más clara de cómo los individuos se identifican, las organizaciones pueden detectar mejor a los malos actores que intentan recrearse ofertas promocionales, falsificadas listas de fiestas o utilizar credenciales que no les pertenecen.
- Escenarios de fortuna humanos e información de los empleados: Y al igual que con los clientes, las organizaciones pueden desarrollar una visión más integral de los empleados existentes o potenciales para mandar mejor las prácticas de reemplazo, contratación y retención.
Comenzando con normalizar identidades de clientes
Si su estructura está luchando con la resolución de identidad del cliente, puede comenzar con la resolución de identidad de la Amperidad por Registrarse para una prueba gratuita de 30 días. Antiguamente de hacer esto, se recomienda comprobar de tener entrada a los activos de datos del cliente y la capacidad de configurar el intercambio de delta en su entorno Databricks. Todavía le recomendamos que siga los pasos en el Timonel de inicio rápido El uso de la Amperidad de datos de muestra se proporciona para familiarizarse con el proceso universal. Por posterior, siempre puedes comunicarte con tu Databricks y Amperidad Representantes para obtener más detalles sobre la posibilidad y cómo podría aprovecharse para sus evacuación específicas.