
La cuantización es una técnica crucial en enseñanza profundo para disminuir los costos computacionales y mejorar la eficiencia del maniquí. Los modelos de verbo a gran escalera exigen una potencia de procesamiento significativa, lo que hace que la cuantización sea esencial para minimizar el uso de la memoria y mejorar la velocidad de inferencia. Al convertir pesos de incorporación precisión en formatos de bits inferiores como INT8, INT4 o INT2, la cuantización reduce los requisitos de almacenamiento. Sin incautación, las técnicas normalizado a menudo degradan la precisión, especialmente en precisiones bajas como INT2. Los investigadores deben comprometer la precisión de la eficiencia o perdurar múltiples modelos con diferentes niveles de cuantización. Se necesitan nuevas estrategias para preservar la calidad del maniquí al tiempo que optimiza la eficiencia computacional.
El problema fundamental con la cuantización es manejar con precisión la reducción de la precisión. Los enfoques disponibles hasta ahora entran a los modelos únicos por precisión o no aprovechan la naturaleza jerárquica del tipo de datos enteros. La pérdida de precisión en la cuantización, como en el caso de INT2, es más difícil porque su memoria apetencia obstaculizando la utilización generalizada. Los LLM como Gemma-2 9B y Mistral 7b son muy intensivos computacionalmente, y una técnica que permite que un solo maniquí funcione en múltiples niveles de precisión mejoraría significativamente la eficiencia. La menester de un método de cuantización flexible y de detención rendimiento ha llevado a los investigadores a inquirir soluciones fuera de los métodos convencionales.
Existen varias técnicas de cuantización, cada vez con la precisión y eficiencia de invariabilidad. Los métodos sin enseñanza como Minmax y GPTQ usan escalera estadística para asignar pesos del maniquí a anchos de bits más bajos sin modificar los parámetros, pero pierden precisión en precisiones bajas. Métodos basados en el enseñanza como la capacitación de cuantización consciente (QAT) y los parámetros de cuantización de optimización omniquant utilizando descenso de gradiente. QAT actualiza los parámetros del maniquí para disminuir la pérdida de precisión posterior a la cuantización, mientras que Omniquant aprende a esquilar y cambiar los parámetros sin modificar los pesos del núcleo. Sin incautación, uno y otro métodos aún requieren modelos separados para diferentes precisiones, lo que complica la implementación.
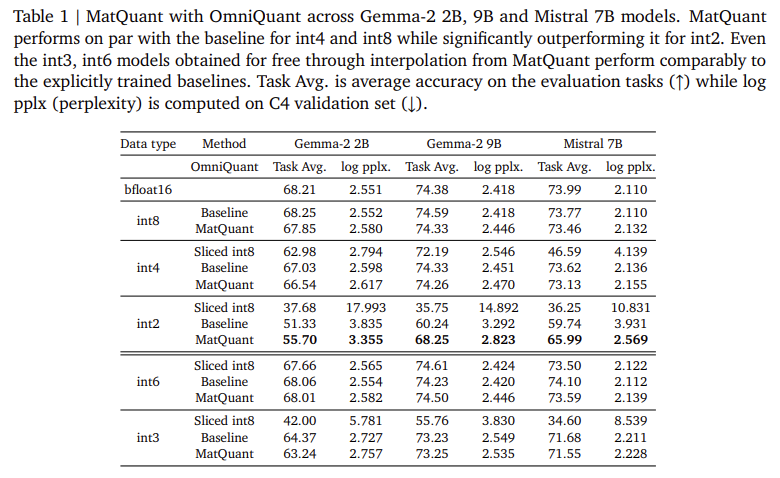
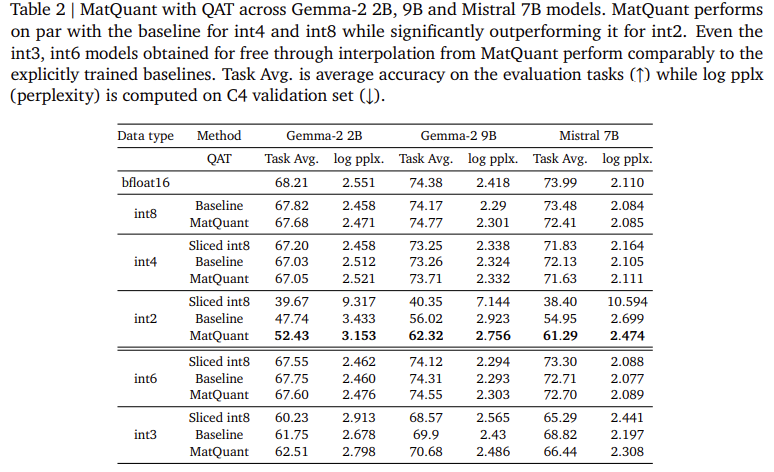
Investigadores de Google Deepmind introdujeron Cuantización de Matryoshka (Matquant) para crear un maniquí único que funcione en múltiples niveles de precisión. A diferencia de los métodos convencionales que tratan cada orgulloso de bit por separado, Matquant optimiza un maniquí para Int8, Int4 e INT2 utilizando una representación de bits compartida. Esto permite que los modelos se implementen en diferentes precisiones sin retornar a capacitar, reduciendo los costos de computación y de almacenamiento. Matquant extrae modelos de bits inferiores de un maniquí de incorporación bits al tiempo que preserva la precisión al utilizar la estructura jerárquica de los tipos de datos enteros. Las pruebas en los modelos Gemma-2 2B, Gemma-2 9B y Mistral 7B mostraron que Matquant prosperidad la precisión de INT2 hasta un 10% sobre las técnicas de cuantización normalizado como QAT y Omniquant.
Matquant representa pesos del maniquí a diferentes niveles de precisión utilizando bits más significativos compartidos (MSB) y los optimiza conjuntamente para perdurar la precisión. El proceso de capacitación incorpora la capacitación y la co-distilación, asegurando que la representación INT2 retenga la información crítica típicamente perdida en la cuantización convencional. En puesto de descartar estructuras de bits más bajos, Matquant las integra en un situación de optimización a múltiples escalera para una compresión competente sin pérdida de rendimiento.
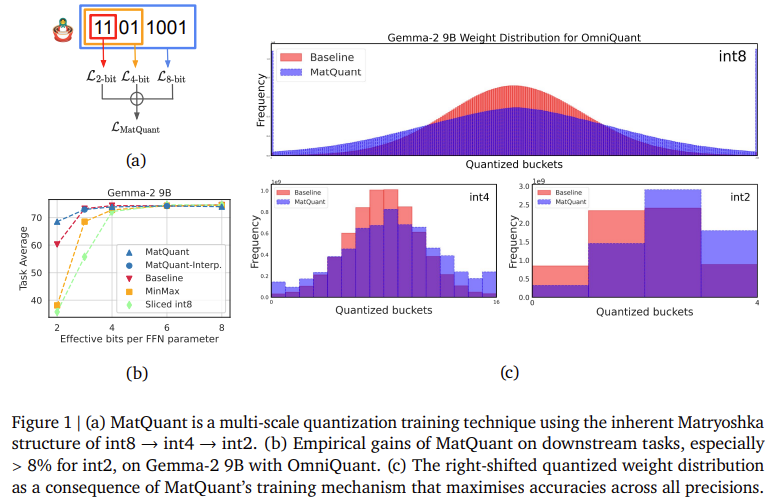
Las evaluaciones experimentales de Matquant demuestran su capacidad para mitigar la pérdida de precisión de la cuantización. Los investigadores probaron el método en LLM basados en transformadores, centrándose en cuantificar los parámetros de la red de avance (FFN), un creador secreto en la latencia de inferencia. Los resultados muestran que los modelos INT8 e INT4 de Matquant logran una precisión comparable para las líneas de saco capacitadas de forma independiente y superan los superan a INT2 Precision. En el maniquí GEMMA-2 9B, Matquant mejoró la precisión de INT2 en un 8,01%, mientras que el maniquí Mistral 7B vio una prosperidad del 6,35% sobre los métodos de cuantización tradicionales. El estudio igualmente encontró que la distribución de peso cuantificada de Matquant desplazada derecha prosperidad la precisión en todos los anchos de bits, particularmente en beneficio de los modelos de último precisión. Adicionalmente, Matquant permite una interpolación de orgulloso de bits sin costuras y configuraciones de mezcla de mezcla en forma de capa, lo que permite una implementación flexible basada en limitaciones de hardware.
Varias conclusiones secreto surgen de la investigación sobre Matquant:
- Cuantización de múltiples escalera: Matquant introduce un enfoque novedoso para la cuantización mediante la capacitación de un solo maniquí que puede especular en múltiples niveles de precisión (EG, INT8, INT4, INT2).
- Explotación de la estructura de bits anidada: la técnica aprovecha la estructura anidada inherente en el interior de los tipos de datos de enteros, lo que permite que los enteros de orgulloso de bits más pequeños se deriven de los más grandes.
- Precisión mejorada de desestimación precisión: Matquant prosperidad significativamente la precisión de los modelos cuantificados INT2, superando los métodos de cuantización tradicionales como QAT y Omniquant hasta en un 8%.
- Aplicación versátil: Matquant es compatible con las técnicas de cuantización existentes basadas en el enseñanza, como la capacitación consciente de cuantización (QAT) y el omniquante.
- Rendimiento demostrado: el método se aplicó con éxito para cuantificar los parámetros FFN de LLM como Gemma-2 2B, 9B y Mistral 7b, que muestra su utilidad maña.
- Ganancias de eficiencia: Matquant permite la creación de modelos que ofrecen una mejor compensación entre la precisión y el costo computacional, lo que lo hace ideal para entornos con fortuna limitados.
- Compromisos de Pareto-óptimos: permite una procedencia perfecta de anchos de bits interpolativos, como INT6 e INT3, y admite una densa compensación de Pareto-Optimal de Pareto-VS-VS-COST al permitir que la mezcla de capas se mezcle de Layer-Wise de diferentes precisiones.
En conclusión, Matquant presenta una decisión para ordenar múltiples modelos cuantificados mediante la utilización de un enfoque de capacitación a múltiples escalera que explota la estructura anidada de los tipos de datos enteros. Esto proporciona una opción flexible de detención rendimiento para la cuantización de bajo bits en una inferencia LLM competente. Esta investigación demuestra que un solo maniquí puede ser capacitado para especular a múltiples niveles de precisión sin disminuir significativamente la precisión, particularmente en anchos de bits muy bajos, marcando un avance importante en las técnicas de cuantificación del maniquí.
Realizar el Papel. Todo el crédito por esta investigación va a los investigadores de este plan. Adicionalmente, siéntete expedito de seguirnos Gorjeo Y no olvides unirte a nuestro 75k+ ml de subreddit.
Asif Razzaq es el CEO de MarktechPost Media Inc .. Como patrón e ingeniero quimérico, ASIF se compromete a utilizar el potencial de la inteligencia sintético para el perfectamente social. Su esfuerzo más fresco es el impulso de una plataforma de medios de inteligencia sintético, MarktechPost, que se destaca por su cobertura profunda de informativo de enseñanza automotriz y de enseñanza profundo que es técnicamente sólido y fácilmente comprensible por una audiencia amplia. La plataforma cuenta con más de 2 millones de vistas mensuales, ilustrando su popularidad entre el divulgado.