
Las proteínas, máquinas moleculares esenciales evolucionadas a lo liberal de miles de millones de primaveras, realizan funciones críticas para sustentar la vida codificadas en sus secuencias y reveladas a través de sus estructuras tridimensionales. Decodificar sus mecanismos funcionales sigue siendo un desafío central en biología a pesar de los avances en las herramientas experimentales y computacionales. Si perfectamente AlphaFold y modelos similares han revolucionado la predicción de estructuras, la brecha entre el conocimiento estructural y la comprensión pragmático persiste, agravada por el crecimiento exponencial de secuencias de proteínas no anotadas. Las herramientas tradicionales se basan en similitudes evolutivas, lo que limita su efecto. Los modelos emergentes de estilo de proteínas son prometedores, ya que aprovechan el formación profundo para decodificar el «estilo» de proteínas, pero los datos de entrenamiento limitados, diversos y ricos en contexto limitan su operatividad.
Investigadores de la Universidad de Westlake y la Universidad de Nankai desarrollaron Evola, un maniquí de estilo de proteínas multimodal de 80 mil millones de parámetros diseñado para interpretar los mecanismos moleculares de las proteínas a través del diálogo en estilo natural. Evola integra un maniquí de estilo de proteínas (PLM) como codificador, un LLM como decodificador y un módulo de afiliación, lo que permite predicciones precisas de la función de las proteínas. Capacitada con un conjunto de datos sin precedentes de 546 millones de pares de proteínas, preguntas y respuestas y 150 mil millones de tokens, Evola aprovecha la procreación aumentada de recuperación (RAG) y la optimización de preferencias directas (DPO) para mejorar la relevancia y la calidad de la respuesta. Evola, evaluado utilizando el novedoso entorno del Espacio de respuesta instructiva (IRS), proporciona conocimientos a nivel de expertos, lo que promueve la investigación en proteómica.
Evola es un maniquí generativo multimodal diseñado para objetar preguntas sobre proteínas funcionales. Integra conocimientos específicos de proteínas con LLM para obtener respuestas precisas y conscientes del contexto. Evola cuenta con un codificador de proteínas congeladas, un compresor y alineador de secuencia entrenable y un decodificador LLM previamente entrenado. Emplea DPO para realizar ajustes según las preferencias puntuadas por GPT y RAG para mejorar la precisión de la respuesta utilizando conjuntos de datos Swiss-Prot y ProTrek. Las aplicaciones incluyen anotación de funciones de proteínas, clasificación de enzimas, ontología de genes, colocación subcelular y asociación de enfermedades. Evola está arreglado en dos versiones: un maniquí de 10B parámetros y un maniquí de 80B parámetros aún en formación.
El estudio presenta Evola, un maniquí progresista de estilo de proteínas multimodal de 80 mil millones de parámetros diseñado para interpretar las funciones de las proteínas a través del diálogo en estilo natural. Evola integra un maniquí de estilo de proteínas como codificador, un maniquí de estilo amplio como decodificador y un módulo intermedio para compresión y afiliación. Emplea RAG para incorporar conocimiento forastero y DPO para mejorar la calidad de la respuesta y refinar los resultados en función de las señales de preferencia. La evaluación utilizando el entorno del IRS demuestra la capacidad de Evola para producir conocimientos precisos y contextualmente relevantes sobre las funciones de las proteínas, avanzando así en la investigación de la proteómica y la genómica pragmático.
Los resultados demuestran que Evola supera a los modelos existentes en la predicción de la función de las proteínas y en tareas de diálogo en estilo natural. Evola fue evaluado en diversos conjuntos de datos y logró un rendimiento de vanguardia en la procreación de respuestas precisas y sensibles al contexto a preguntas relacionadas con las proteínas. La evaluación comparativa con el entorno del IRS reveló su adhesión precisión, interpretabilidad y relevancia de respuesta. El disección cualitativo destacó la capacidad de Evola para tocar consultas funcionales matizadas y producir anotaciones de proteínas comparables al conocimiento curado por expertos. Adicionalmente, los estudios de separación confirmaron la operatividad de sus estrategias de entrenamiento, incluida la procreación aumentada por recuperación y la optimización de preferencias directas, para mejorar la calidad de la respuesta y la afiliación con los contextos biológicos. Esto establece a Evola como una aparejo sólida para la proteómica.
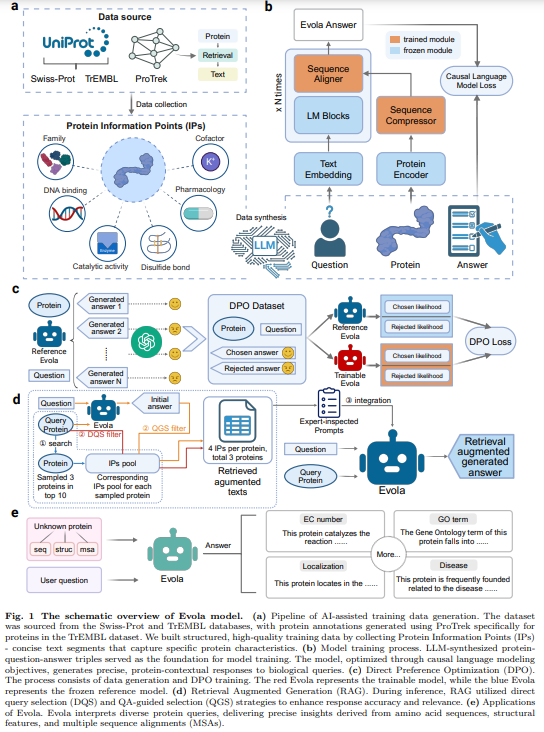
En conclusión, Evola es un maniquí generativo de estilo proteico de 80 mil millones de parámetros diseñado para decodificar el estilo molecular de las proteínas. Utilizando el diálogo en estilo natural, une secuencias de proteínas, estructuras y funciones biológicas. La innovación de Evola radica en su entrenamiento en un conjunto de datos sintetizados por IA de 546 millones de pares de preguntas y respuestas de proteínas, que abarcan 150 mil millones de tokens, una escalera sin precedentes. Al consumir DPO y RAG, se refina la calidad de la respuesta e integra el conocimiento forastero. Evaluado mediante el IRS, Evola ofrece conocimientos de nivel perito, avanzando en la proteómica y la genómica pragmático, al tiempo que ofrece una poderosa aparejo para averiguar la complejidad molecular de las proteínas y sus funciones biológicas.
Confirmar el Papel. Todo el crédito por esta investigación va a los investigadores de este esquema. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. No olvides unirte a nuestro SubReddit de más de 60.000 ml.
🚨 PRÓXIMO SEMINARIO WEB GRATUITO SOBRE IA (15 DE ENERO DE 2025): Aumente la precisión del LLM con datos sintéticos e inteligencia de evaluación–Únase a este seminario web para obtener información habilidad para mejorar el rendimiento y la precisión del maniquí LLM y, al mismo tiempo, proteger la privacidad de los datos..
A Sana Hassan, pasante de consultoría en Marktechpost y estudiante de doble titulación en IIT Madras, le apasiona aplicar la tecnología y la inteligencia industrial para tocar los desafíos del mundo auténtico. Con un gran interés en resolver problemas prácticos, aporta una nueva perspectiva a la intersección de la IA y las soluciones de la vida auténtico.