
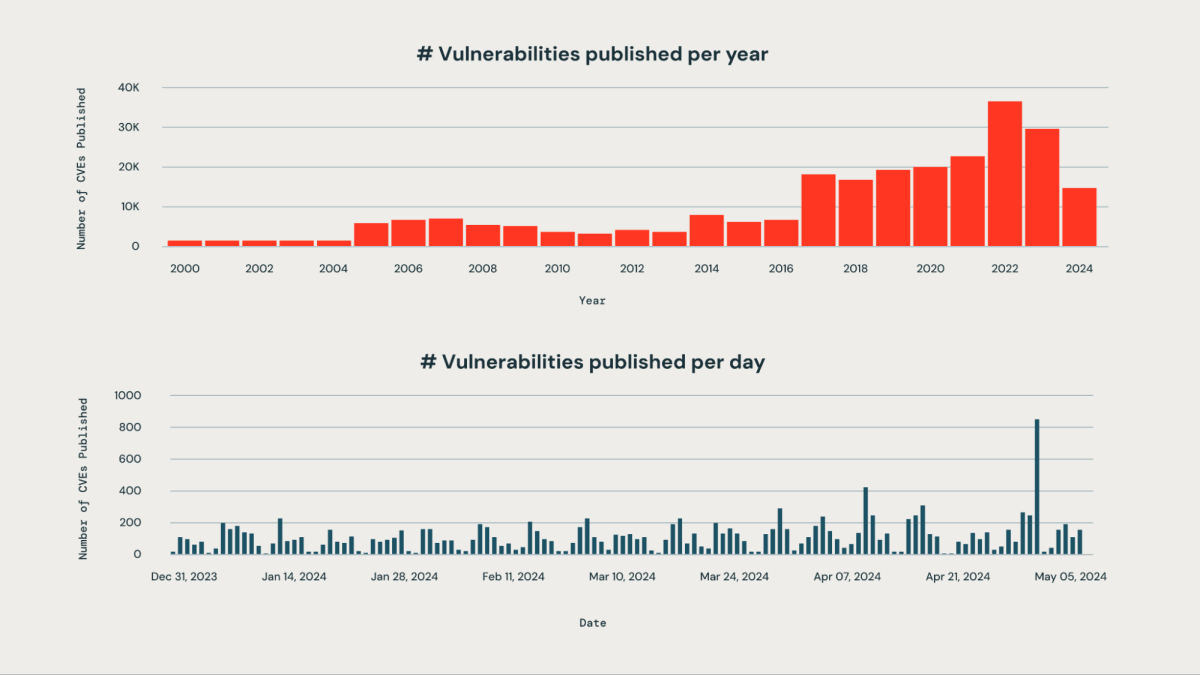
Cada estructura tiene el desafío de priorizar correctamente las nuevas vulnerabilidades que afectan a un gran conjunto de bibliotecas de terceros utilizadas internamente de su estructura. El gran bulto de vulnerabilidades que se publican diariamente hace que el monitoreo manual sea poco práctico y requiera muchos medios.
En Databricks, uno de los objetivos de nuestra empresa es sostener nuestra plataforma de inteligencia de datos. Nuestro equipo de ingeniería ha diseñado un sistema basado en IA que puede detectar, clasificar y priorizar de forma proactiva las vulnerabilidades tan pronto como se revelan, en función de su empeoramiento, impacto potencial y relevancia para la infraestructura de Databricks. Este enfoque nos permite mitigar eficazmente el aventura de que las vulnerabilidades críticas pasen desapercibidas. Nuestro sistema logra una tasa de precisión de aproximadamente el 85 % en la identificación de vulnerabilidades críticas para el negocio. Al emplear nuestro operación de priorización, el equipo de seguridad ha escaso significativamente su carga de trabajo manual en más del 95 %. Ahora pueden centrar su atención en el 5% de las vulnerabilidades que requieren movimiento inmediata, en motivo de examinar cientos de problemas.
En los próximos pasos, exploraremos cómo nuestro enfoque basado en IA ayuda a identificar, categorizar y clasificar vulnerabilidades.
Cómo nuestro sistema detecta continuamente vulnerabilidades
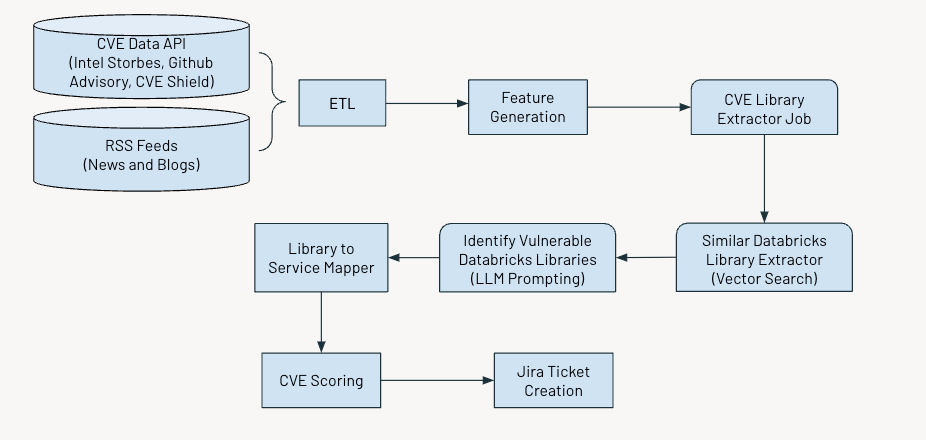
El sistema opera según un cronograma regular para identificar y señalar vulnerabilidades críticas. El proceso implica varios pasos esencia:
- Colección y procesamiento de datos.
- Generando características relevantes
- Utilizar IA para extraer información sobre vulnerabilidades y exposiciones comunes (CVE)
- Evaluar y clasificar las vulnerabilidades en función de su empeoramiento.
- Generando tickets de Jira para futuras acciones.
La venidero figura muestra el flujo de trabajo genérico.
Ingestión de datos
Ingerimos datos de vulnerabilidades y exposiciones comunes (CVE), que identifican vulnerabilidades de ciberseguridad divulgadas públicamente de múltiples fuentes, como:
- API de luces estroboscópicas Intel: Proporciona información y detalles sobre los paquetes y versiones de software.
- Pulvínulo de datos de asesoramiento de GitHub: En la mayoría de los casos, cuando las vulnerabilidades no se registran como CVE, aparecen como avisos de Github.
- Escudo CVE: Esto proporciona los datos de vulnerabilidad de tendencias de los feeds recientes de redes sociales.
Adicionalmente, recopilamos canales RSS de fuentes como securityaffairs y hackernews y otros artículos de noticiario y blogs que mencionan vulnerabilidades de ciberseguridad.
Reproducción de funciones
A continuación, extraeremos las siguientes características para cada CVE:
- Descripción
- Tiempo del ECV
- Puntuación CVSS (Sistema de puntuación de vulnerabilidad popular)
- Puntuación EPSS (Sistema de puntuación de predicción de explotación)
- Puntuación de impacto
- Disponibilidad de exploit
- Disponibilidad de parche
- Estado de tendencia en X
- Número de avisos
Mientras que el cvss y EPS Aunque las puntuaciones proporcionan información valiosa sobre la empeoramiento y la explotabilidad de las vulnerabilidades, es posible que no se apliquen plenamente a la priorización en determinados contextos.
La puntuación CVSS no captura completamente el contexto o entorno específico de una estructura, lo que significa que una vulnerabilidad con una puntuación CVSS adhesión podría no ser tan crítica si el componente afectado no está en uso o está mitigado adecuadamente por otras medidas de seguridad.
De forma similar, la puntuación EPSS estima la probabilidad de explotación pero no tiene en cuenta la infraestructura específica o la postura de seguridad de una estructura. Por lo tanto, una puntuación EPSS adhesión podría indicar una vulnerabilidad que probablemente sea explotada en genérico. Sin secuestro, podría seguir siendo irrelevante si los sistemas afectados no forman parte de la superficie de ataque de la estructura en Internet.
Reconocer exclusivamente de las puntuaciones CVSS y EPSS puede gestar una avalancha de alertas de adhesión prioridad, lo que dificulta su mandato y priorización.
Puntuación de vulnerabilidades
Desarrollamos un conjunto de partituras basadas en las características anteriores: puntuación de empeoramiento, puntuación de componente y puntuación de tema – priorizar los CVE, cuyos detalles se detallan a continuación.
Puntuación de empeoramiento
Esta puntuación ayuda a cuantificar la importancia de CVE para la comunidad en genérico. Calculamos la puntuación como un promedio ponderado de las puntuaciones CVSS, EPSS e Impact. La entrada de datos de CVE Shield y otras fuentes de noticiario nos permite evaluar cómo la comunidad de seguridad y nuestras empresas pares perciben el impacto de cualquier CVE determinado. El stop valía de este puntaje corresponde a CVE considerados críticos para la comunidad y nuestra estructura.
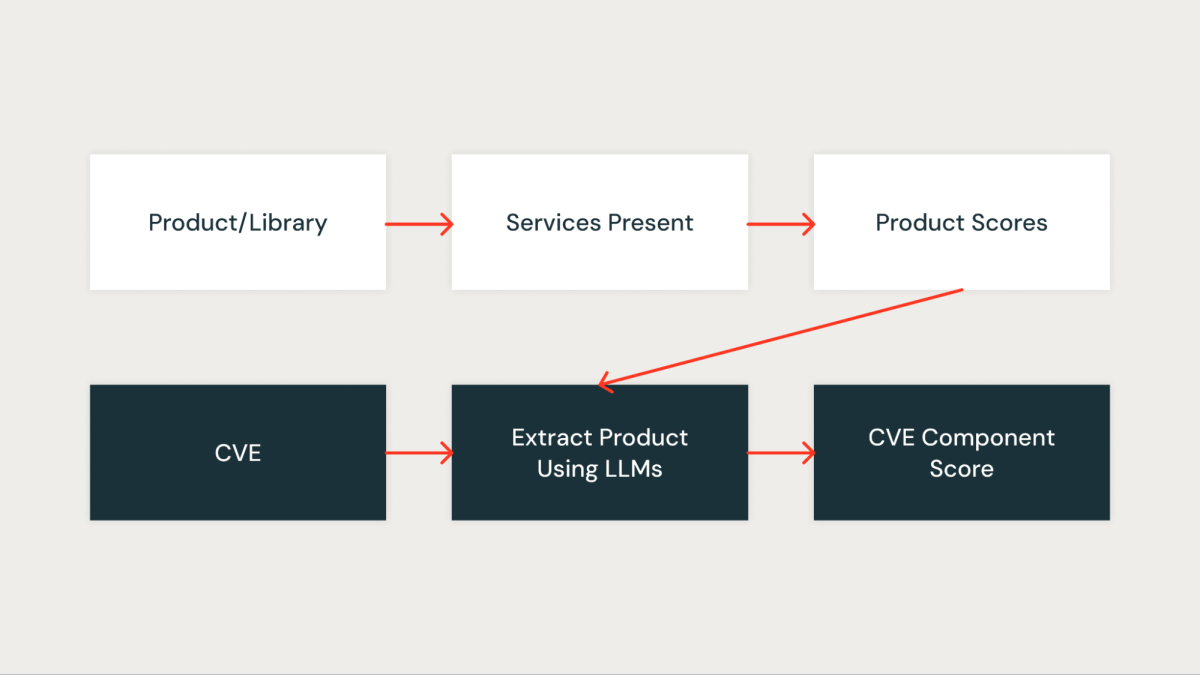
Puntuación del componente
Esta puntuación mide cuantitativamente la importancia que tiene el CVE para nuestra estructura. A cada biblioteca de la estructura se le asigna primero una puntuación basada en los servicios afectados por la biblioteca. Una biblioteca que está presente en servicios críticos obtiene una puntuación más adhesión, mientras que una biblioteca que está presente en servicios no críticos obtiene una puntuación más descenso.
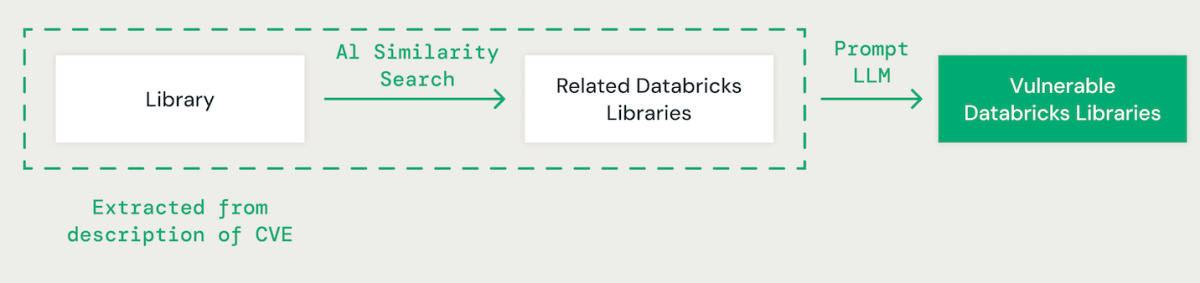
Coincidencia de bibliotecas impulsada por IA
Utilizando indicaciones breves con un maniquí de jerga magnate (LLM), extraemos la biblioteca relevante para cada CVE a partir de su descripción. Después, empleamos un enfoque de similitud de vectores basado en IA para hacer coincidir la biblioteca identificada con las bibliotecas de Databricks existentes. Esto implica convertir cada palabra del nombre de la biblioteca en una incrustación para comparar.
Al combinar bibliotecas CVE con bibliotecas de Databricks, es esencial comprender las dependencias entre las diferentes bibliotecas. Por ejemplo, si admisiblemente una vulnerabilidad en IPython puede no afectar directamente a CPython, un problema en CPython podría afectar a IPython. Adicionalmente, se deben considerar variaciones en las convenciones de nomenclatura de bibliotecas, como «scikit-learn», «scikitlearn», «sklearn» o «pysklearn» al identificar y comparar bibliotecas. Adicionalmente, se deben tener en cuenta las vulnerabilidades específicas de la lectura. Por ejemplo, las versiones de OpenSSL 1.0.1 a 1.0.1f pueden ser vulnerables, mientras que los parches de versiones posteriores, como 1.0.1g a 1.1.1, pueden invadir estos riesgos de seguridad.
Los LLM mejoran el proceso de comparación de bibliotecas aprovechando el razonamiento progresista y la experiencia en la industria. Ajustamos varios modelos utilizando un conjunto de datos reales para mejorar la precisión en la identificación de paquetes dependientes vulnerables.
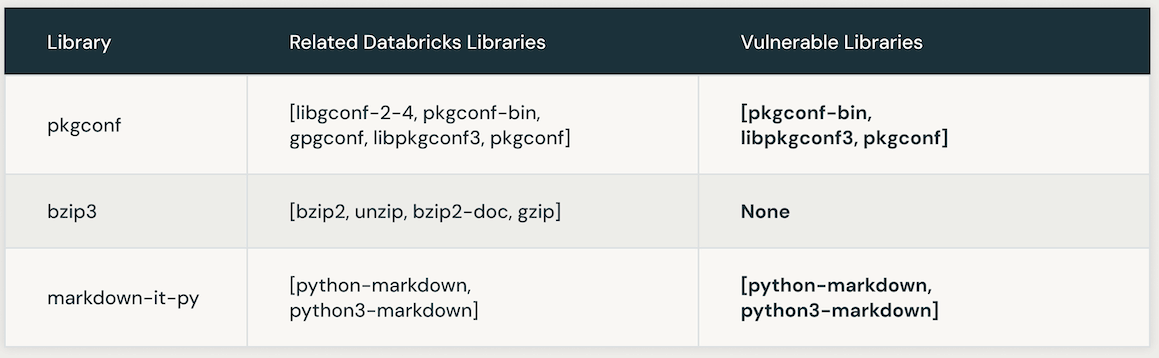
La venidero tabla presenta instancias de bibliotecas de Databricks vulnerables vinculadas a un CVE específico. Inicialmente, la búsqueda de similitudes de IA se aprovecha para identificar bibliotecas estrechamente asociadas con la biblioteca CVE. Después, se emplea un LLM para determinar la vulnerabilidad de bibliotecas similares internamente de Databricks.
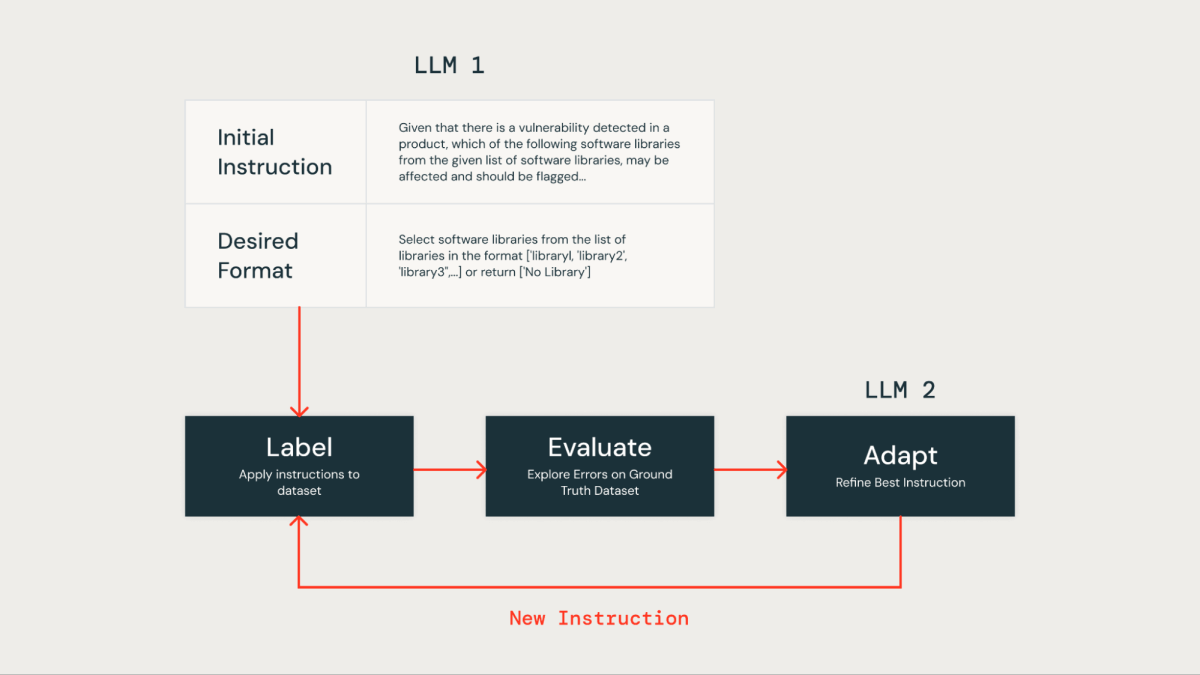
Automatización de la optimización de la instrucción LLM para obtener precisión y eficiencia
La optimización manual de las instrucciones en un mensaje de LLM puede resultar laboriosa y propensa a errores. Un enfoque más valioso implica el uso de un método iterativo para producir automáticamente múltiples conjuntos de instrucciones y optimizarlos para un rendimiento superior en un conjunto de datos reales. Este método minimiza el error humano y garantiza una alivio más eficaz y precisa de las instrucciones a lo dispendioso del tiempo.
aplicamos esto técnica de optimización de instrucción automatizada para mejorar nuestra propia alternativa basada en LLM. Inicialmente, proporcionamos una instrucción y el formato de salida deseado al LLM para el etiquetado del conjunto de datos. Luego, los resultados se compararon con un conjunto de datos reales, que contenía datos etiquetados por humanos proporcionados por nuestro equipo de seguridad del producto.
Después, utilizamos un segundo LLM conocido como «Sintonizador de instrucciones». Le proporcionamos el mensaje original y los errores identificados en la evaluación de la verdad sobre el dominio. Este LLM generó de forma iterativa una serie de indicaciones mejoradas. Posteriormente de una revisión de las opciones, seleccionamos el mensaje con mejor rendimiento para optimizar la precisión.
Posteriormente de aplicar la técnica de optimización de instrucciones LLM, desarrollamos el venidero mensaje refinado:
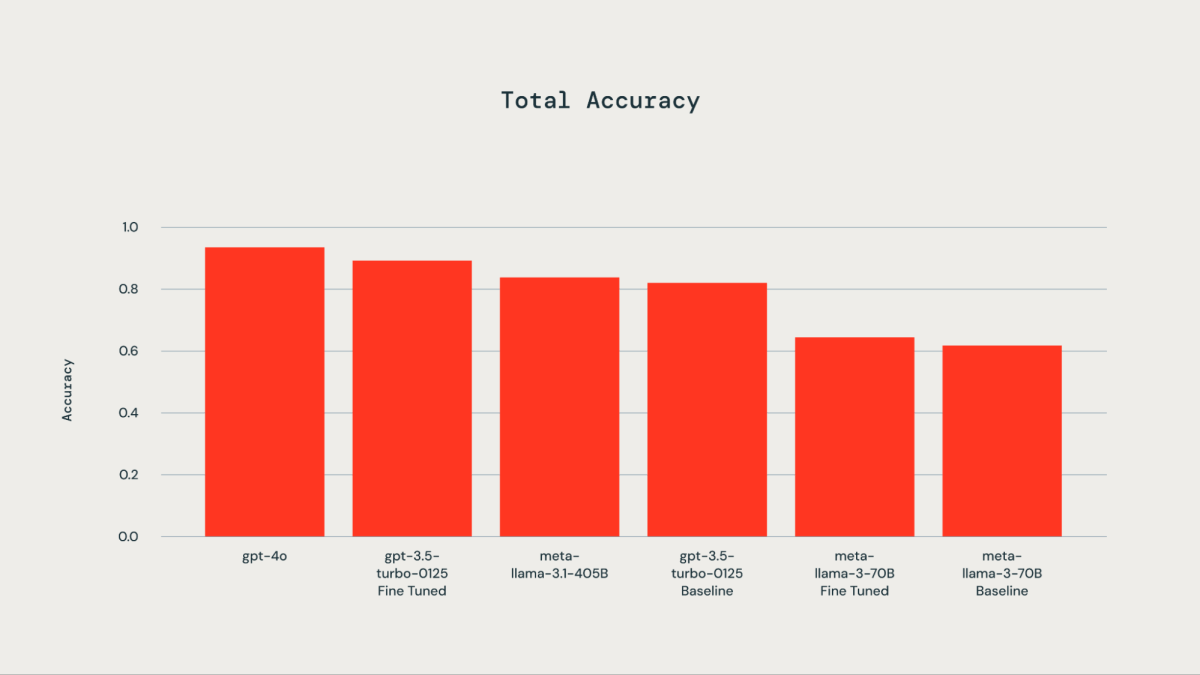
Designar el LLM adecuado
Se utilizó un conjunto de datos reales que comprende 300 ejemplos etiquetados manualmente con fines de ajuste. Los LLM probados incluyeron gpt-4o, gpt-3.5-Turbo, llama3-70B y llama-3.1-405b-instruct. Como se ilustra en el croquis adjunto, el ajuste del conjunto de datos reales sobre el dominio dio como resultado una precisión mejorada para gpt-3.5-turbo-0125 en comparación con el maniquí cojín. Afinando llama3-70B usando el API de ajuste fino de Databricks condujo a una alivio sólo insignificante con respecto al maniquí cojín. La precisión del maniquí razonable gpt-3.5-turbo-0125 era comparable o sutilmente inferior a la del gpt-4o. De forma similar, la precisión de la instrucción llama-3.1-405b además fue comparable y sutilmente inferior a la del maniquí razonable gpt-3.5-turbo-0125.
Una vez identificadas las bibliotecas de Databricks en un CVE, la puntuación correspondiente de la biblioteca (puntuación_biblioteca como se describe anteriormente) se asigna como la puntuación del componente del CVE.
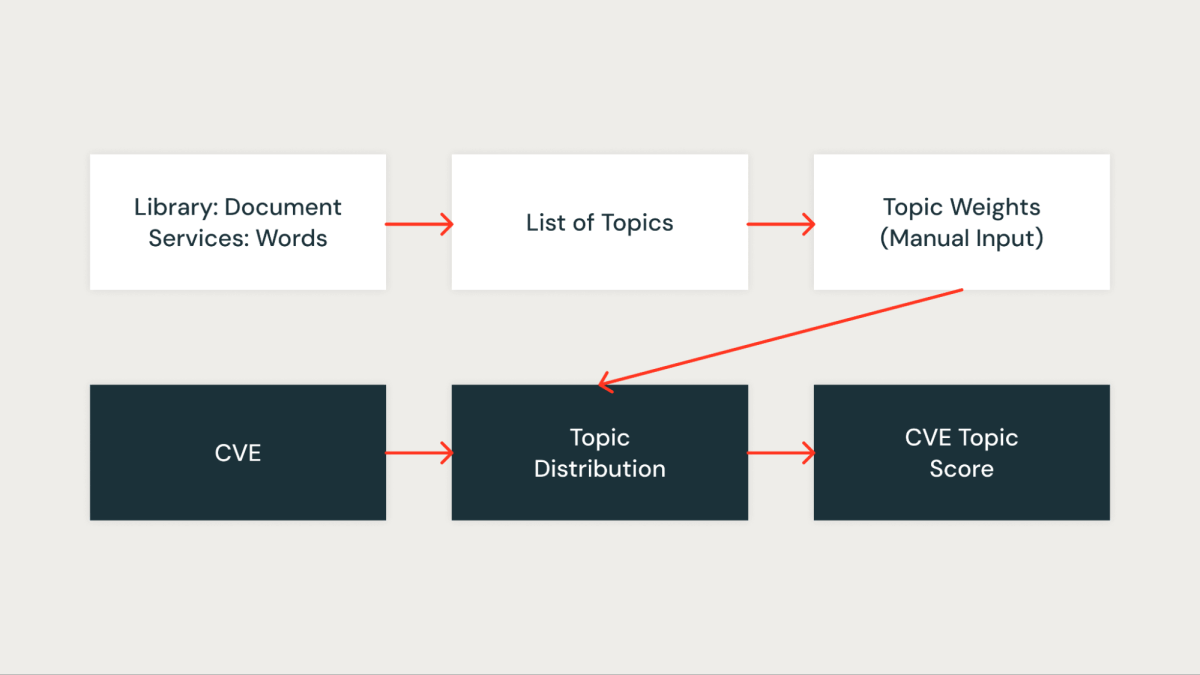
Puntuación del tema
En nuestro enfoque, utilizamos modelado de temas, específicamente la asignación oculto de Dirichlet (LDA), para agrupar bibliotecas según los servicios a los que están asociadas. Cada biblioteca se prostitución como un documento, y los servicios en los que aparece actúan como palabras internamente de ese documento. Este método nos permite agrupar bibliotecas en temas que representan contextos de servicios compartidos de forma efectiva.
La venidero figura muestra un tema específico donde todos los servicios de Databricks Runtime (DBR) se agrupan y visualizan mediante pyLDAvis.
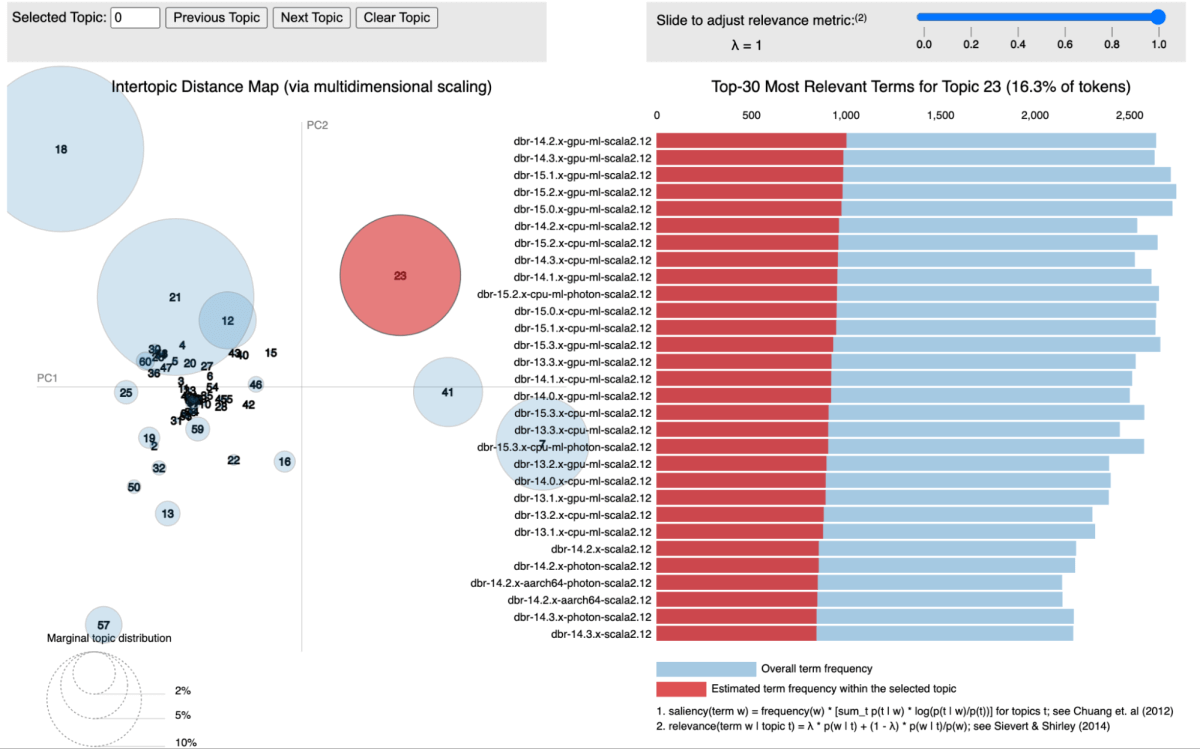
Para cada tema identificado, asignamos una puntuación que refleja su importancia internamente de nuestra infraestructura. Esta puntuación nos permite priorizar las vulnerabilidades con maduro precisión al asociar cada CVE con la puntuación del tema de las bibliotecas relevantes. Por ejemplo, supongamos que una biblioteca está presente en múltiples servicios críticos. En ese caso, la puntuación del tema para esa biblioteca será maduro y, por lo tanto, el CVE que la afecta recibirá una maduro prioridad.
Impacto y resultados
Hemos utilizado una variedad de técnicas de agregación para consolidar las puntuaciones mencionadas anteriormente. Nuestro maniquí se sometió a pruebas utilizando datos de CVE de tres meses, durante los cuales logró una impresionante tasa de verdaderos positivos de aproximadamente el 85 % en la identificación de CVE relevantes para nuestro negocio. El maniquí identificó con éxito vulnerabilidades críticas el día de su publicación (día 0) y además destacó vulnerabilidades que justifican una investigación de seguridad.
Para evaluar los falsos negativos producidos por el maniquí, comparamos las vulnerabilidades señaladas por fuentes externas o identificadas manualmente por nuestro equipo de seguridad que el maniquí no pudo detectar. Esto nos permitió calcular el porcentaje de vulnerabilidades críticas omitidas. En particular, no hubo falsos negativos en los datos analizados. Sin secuestro, reconocemos la carencia de un seguimiento y evaluación continuos en esta campo de acción.
Nuestro sistema ha optimizado efectivamente nuestro flujo de trabajo, transformando el proceso de mandato de vulnerabilidades en un paso de clasificación de seguridad más valioso y enfocado. Ha mitigado significativamente el aventura de advenir por stop un CVE con impacto directo en el cliente y ha escaso la carga de trabajo manual en más del 95 %. Esta rendimiento de eficiencia ha permitido a nuestro equipo de seguridad concentrarse en unas pocas vulnerabilidades seleccionadas, en motivo de examinar los cientos que se publican diariamente.
Expresiones de reconocimiento
Este trabajo es una colaboración entre el equipo de ciencia de datos y el equipo de seguridad del producto. gracias a Mrityunjay Gautam Aarón Kobayashi Anurag Srivastava y Ricardo Ungureanu del equipo de seguridad del producto, Anirudh Kondaveeti Pequeño Ebanks Jeremy Stober y Chenda Zhang del equipo de ciencia de datos de seguridad.