
OpenAI Canvas es una aparejo versátil diseñada para optimizar la codificación y publicación de texto colaborativas. Con su interfaz intuitiva, Canvas ofrece una plataforma dinámica para que los desarrolladores escriban, editen y depuren código conexo con la subvención basada en inteligencia fabricado de ChatGPT. Esto lo hace particularmente útil para una amplia gradación de tareas, desde secuencias de comandos básicas hasta la diligencia de proyectos complejos. En este artículo, exploraré la codificación con Canvas y compartiré mi experiencia genérico.
Características esencia y ventajas de Canvas
- Colaboración perfecta: Canvas integra interfaces conversacionales, lo que permite a los usuarios modificar, solicitar comentarios o explorar ideas en tiempo efectivo sin cambiar de aparejo.
- Entorno de codificación dinámica: Diseñado para desarrolladores de Python, Canvas admite la ejecución de código, lo que lo hace ideal para tareas como prospección, codificación y visualización de datos.
- Plataforma multifuncional: Canvas no es sólo para editar texto; es un espacio versátil para la chaparrón de ideas, la codificación y los flujos de trabajo estructurados.
Comprobar – Por qué el maniquí o1 es mejor que el GPT-4o
Codificación experiencia con Canvas
Empezando
Exploré las funciones de codificación de Canvas con el objetivo de adjuntar un conjunto de datos y realizar tareas básicas. prospección de datos exploratorios (EDA). Si correctamente la interfaz era intuitiva y prometedora, encontré desafíos al integrar conjuntos de datos externos.
El desafío: entrar a los datos en el Sandbox
Al intentar adjuntar un conjunto de datos, descubrí que el entorno sandbox no podía entrar al archivo. Como posibilidad alternativa, pegué un subconjunto de datos directamente en Canvas, pero esto no resolvió el problema. Incluso con el código escrito correctamente, persistía un mensaje de error que indicaba que no se podían encontrar los datos. Esta demarcación resalta la privación de capacidades mejoradas de integración de datos internamente de Canvas.
Datos sintéticos y visualizaciones
A posteriori de encontrar estas limitaciones, le pedí a Canvas que generara datos sintéticos y realizara visualizaciones. El futuro código se generó y ejecutó exitosamente:
Mensaje: cree un conjunto de datos y luego realice algunas visualizaciones en él.
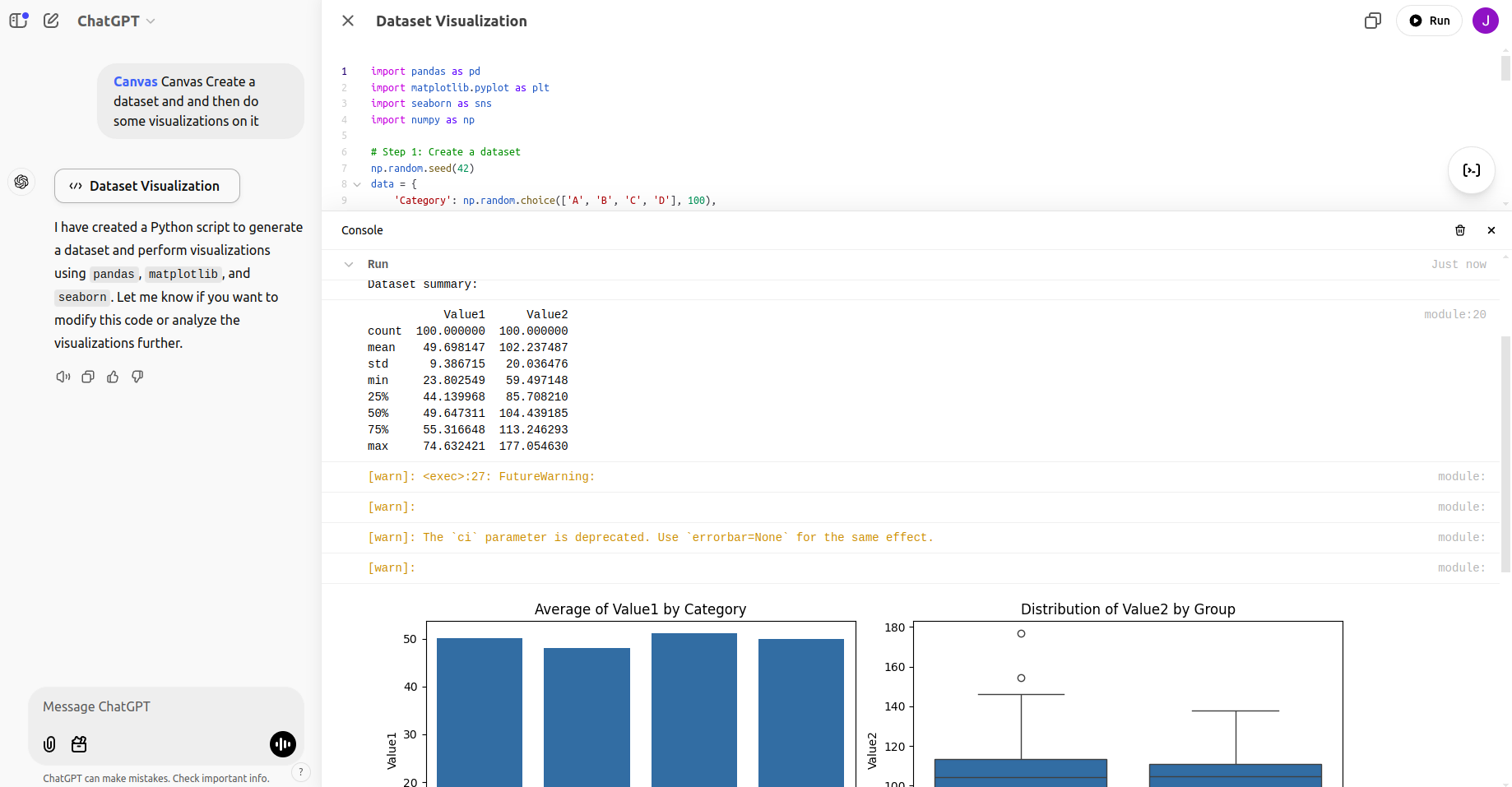
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
data = {
'Category': np.random.choice(('A', 'B', 'C', 'D'), 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.choice(('X', 'Y'), 100)
}
df = pd.DataFrame(data)
# Step 2: Display basic information about the dataset
print("Dataset preview:")
print(df.head())
print("nDataset summary:")
print(df.describe())
# Step 3: Visualizations
plt.figure(figsize=(12, 8))
# Bar plot: Promedio of Value1 by Category
plt.subplot(2, 2, 1)
sns.barplot(x='Category', y='Value1', data=df, ci=None)
plt.title('Promedio of Value1 by Category')
# Box plot: Distribution of Value2 by Group
plt.subplot(2, 2, 2)
sns.boxplot(x='Group', y='Value2', data=df)
plt.title('Distribution of Value2 by Group')
# Scatter plot: Value1 vs. Value2
plt.subplot(2, 2, 3)
sns.scatterplot(x='Value1', y='Value2', hue="Category", data=df)
plt.title('Scatter plot of Value1 vs Value2')
# Histogram: Distribution of Value1
plt.subplot(2, 2, 4)
sns.histplot(df('Value1'), kde=True, bins=20)
plt.title('Histogram of Value1')
plt.tight_layout()
plt.show()
Y al ejecutarlo, este fue el resultado:
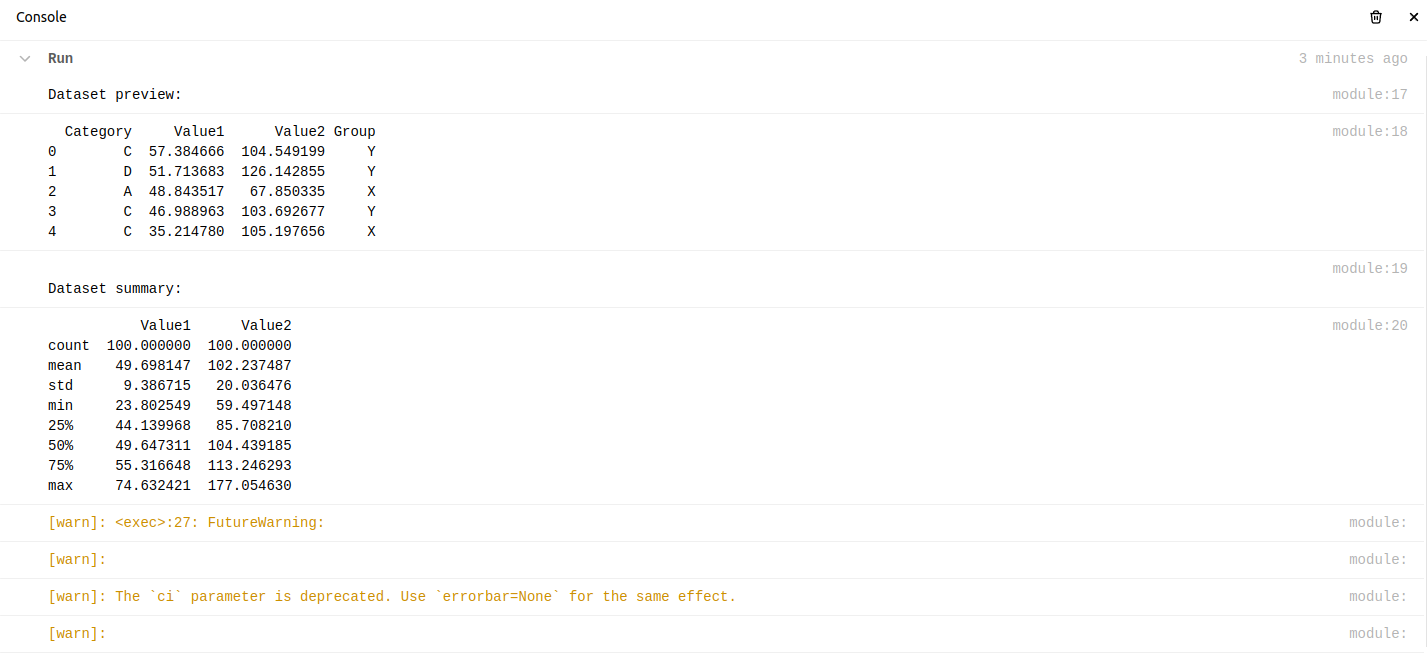
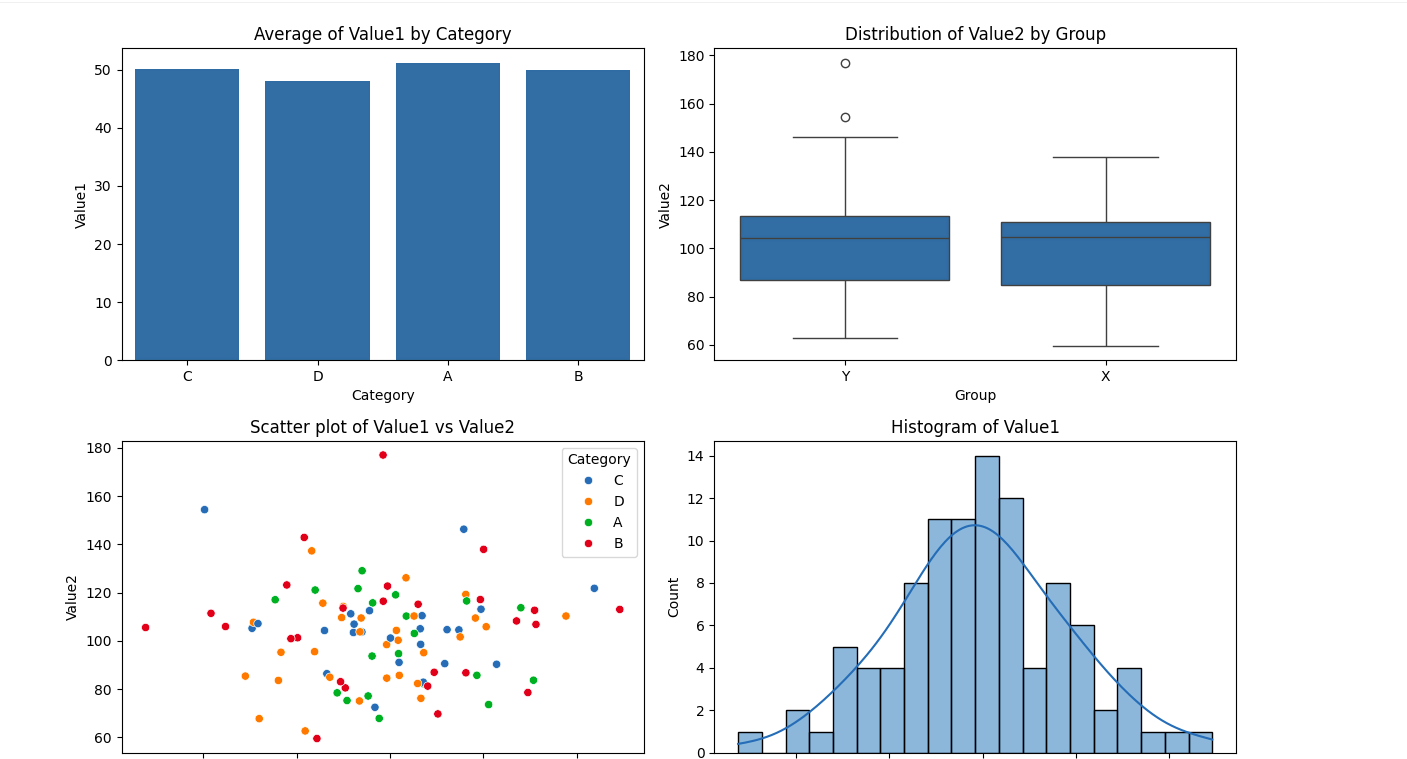
Los resultados fueron visualmente informativos y mostraron la capacidad de la plataforma para manejar tareas básicas de EDA de modo efectiva. A posteriori de esto, realicé EDA descubierta para descubrir conocimientos más profundos:
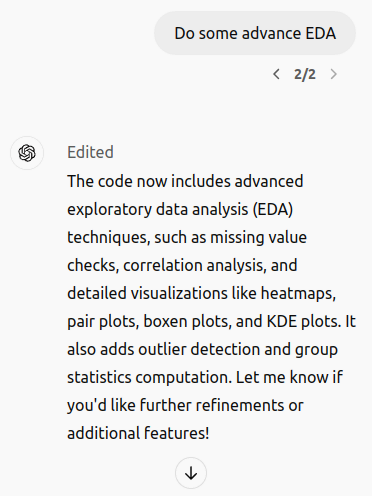
Mientras ejecutaba este EDA reformista, obtuve este error:
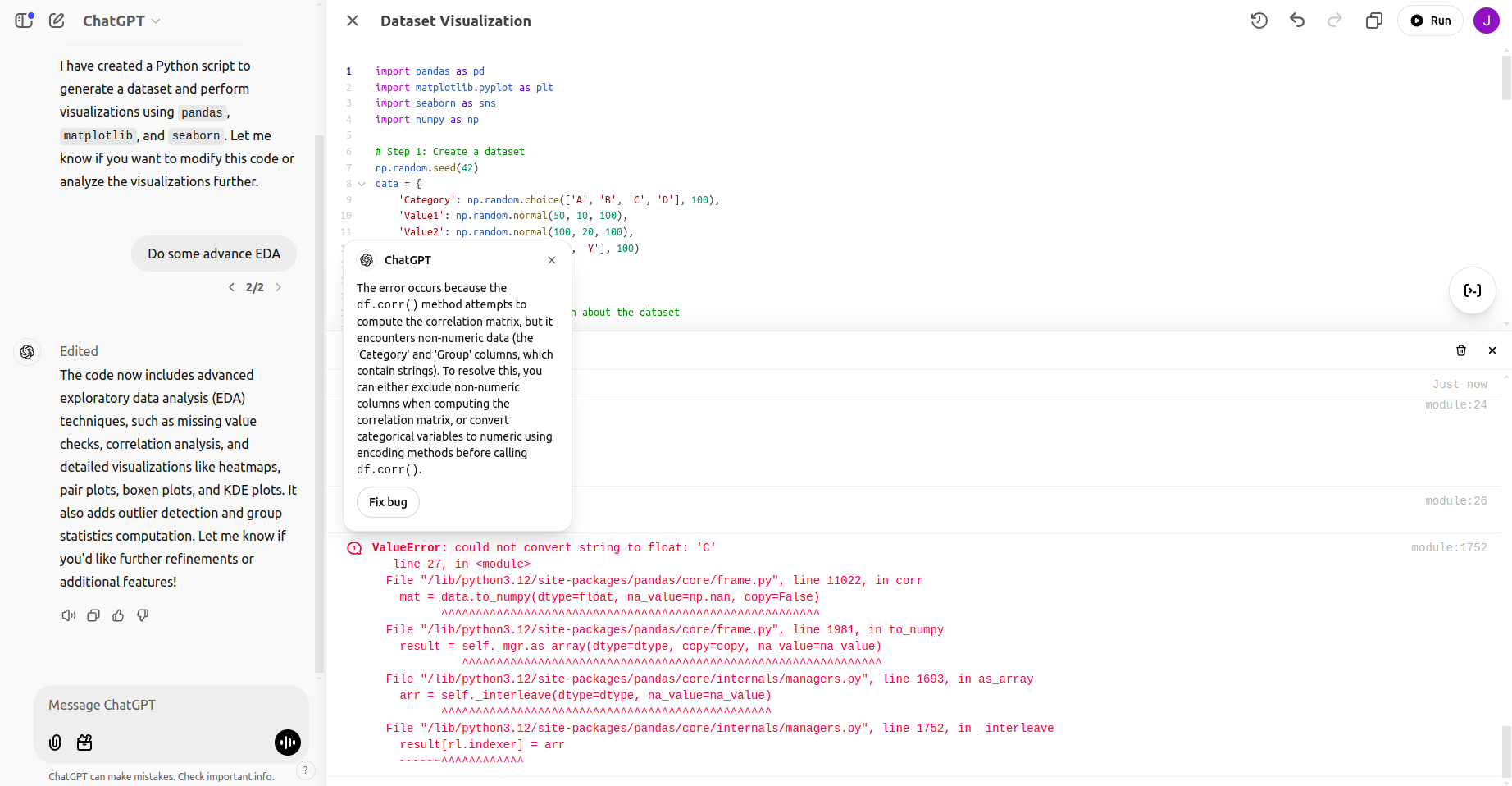
A posteriori de corregir el error:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# Step 1: Create a dataset
np.random.seed(42)
data = {
'Category': np.random.choice(('A', 'B', 'C', 'D'), 100),
'Value1': np.random.regular(50, 10, 100),
'Value2': np.random.regular(100, 20, 100),
'Group': np.random.choice(('X', 'Y'), 100)
}
df = pd.DataFrame(data)
# Step 2: Display basic information about the dataset
print("Dataset preview:")
print(df.head())
print("nDataset summary:")
print(df.describe())
# Advanced EDA
print("nChecking for missing values:")
print(df.isnull().sum())
# Ensure only numeric data is used for correlation matrix
print("nCorrelation matrix:")
numeric_df = df.select_dtypes(include=(np.number))
correlation_matrix = numeric_df.corr()
print(correlation_matrix)
# Visualizations for advanced EDA
plt.figure(figsize=(15, 12))
# Heatmap of correlation matrix
plt.subplot(3, 2, 1)
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix Heatmap')
# Pairplot for relationships
sns.pairplot(df, hue="Category", corner=True, diag_kind='kde')
plt.suptitle('Pairplot of Variables', y=1.02)
plt.show()
# Boxen plot: Distribution of Value1 by Category and Group
plt.subplot(3, 2, 2)
sns.boxenplot(x='Category', y='Value1', hue="Group", data=df)
plt.title('Boxen plot of Value1 by Category and Group')
# Violin plot: Distribution of Value2 by Category
plt.subplot(3, 2, 3)
sns.violinplot(x='Category', y='Value2', data=df, hue="Group", split=True)
plt.title('Violin plot of Value2 by Category')
# Count plot: Frequency of Categories
plt.subplot(3, 2, 4)
sns.countplot(x='Category', data=df, hue="Group")
plt.title('Frequency of Categories by Group')
# KDE plot: Distribution of Value1 and Value2
plt.subplot(3, 2, 5)
sns.kdeplot(x='Value1', y='Value2', hue="Category", data=df, fill=True, alpha=0.6)
plt.title('KDE plot of Value1 vs Value2')
plt.tight_layout()
plt.show()
# Outlier detection
print("nIdentifying potential outliers:")
for column in ('Value1', 'Value2'):
Q1 = df(column).quantile(0.25)
Q3 = df(column).quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df((df(column) < lower_bound) | (df(column) > upper_bound))
print(f"Outliers in {column}:n", outliers)
# Group statistics
print("nGroup statistics:")
print(df.groupby(('Category', 'Group')).agg({'Value1': ('mean', 'std'), 'Value2': ('mean', 'std')}))
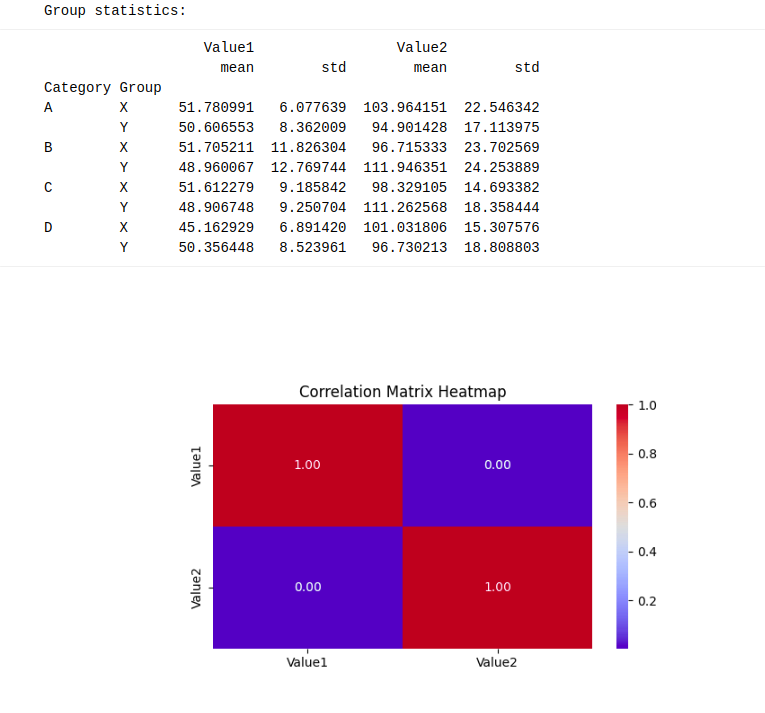
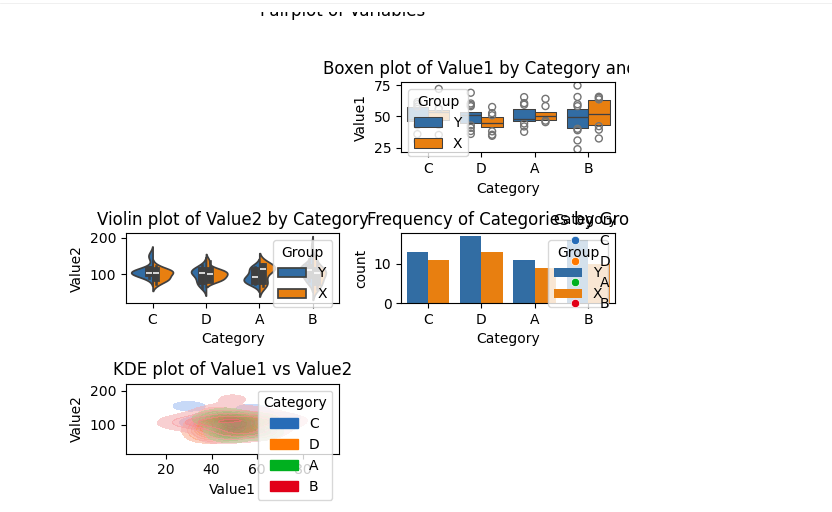
Estos prospección avanzados resaltaron las capacidades de Canvas para tareas exploratorias, pero además subrayaron las limitaciones de la plataforma para integrar conjuntos de datos externos.
Transferir código a otros idiomas
Si correctamente Canvas admite la codificación principalmente en Python, la plataforma permite a los usuarios trasladar el código Python a otros lenguajes, como Java. Sin retención, no ejecuta código en otros lenguajes adicionalmente de Python. A continuación se muestra un ejemplo de un puerto de Python a Java:
import java.util.*;
import java.util.stream.Collectors;
public class DatasetVisualization {
public static void main(String() args) {
// Step 1: Create a synthetic dataset
Random random = new Random(42); // For reproducibility
List ages = random.ints(200, 18, 70).boxed().collect(Collectors.toList());
List incomes = random.ints(200, 30000, 120000).boxed().collect(Collectors.toList());
List genders = random.ints(200, 0, 2).mapToObj(i -> i == 0 ? "Male" : "Female").collect(Collectors.toList());
List spendScores = random.ints(200, 1, 101).boxed().collect(Collectors.toList());
List cities = random.ints(200, 0, 5).mapToObj(i -> {
switch (i) {
case 0: return "New York";
case 1: return "Los Angeles";
case 2: return "Chicago";
case 3: return "Houston";
default: return "Phoenix";
}
}).collect(Collectors.toList());
// Step 2: Create demographic segments
List ageGroups = ages.stream().map(age -> {
if (age <= 30) return "Young";
else if (age <= 50) return "Middle-aged";
else return "Senior";
}).collect(Collectors.toList());
List incomeGroups = incomes.stream().map(income -> {
if (income < 40000) return "Low";
else if (income <= 70000) return "Medium";
else return "High";
}).collect(Collectors.toList());
// Step 3: Print a summary of the dataset
System.out.println("Sample of the dataset:");
for (int i = 0; i < 5; i++) {
System.out.printf("Age: %d, Income: %d, Gender: %s, Spend Score: %d, City: %s, Age Group: %s, Income Group: %sn",
ages.get(i), incomes.get(i), genders.get(i), spendScores.get(i), cities.get(i), ageGroups.get(i), incomeGroups.get(i));
}
// Step 4: Perform a correlation-like analysis (simplified for Java)
double ageIncomeCorrelation = calculateCorrelation(ages, incomes);
double ageSpendScoreCorrelation = calculateCorrelation(ages, spendScores);
double incomeSpendScoreCorrelation = calculateCorrelation(incomes, spendScores);
System.out.println("nCorrelation Analysis:");
System.out.printf("Age-Income Correlation: %.2fn", ageIncomeCorrelation);
System.out.printf("Age-Spend Score Correlation: %.2fn", ageSpendScoreCorrelation);
System.out.printf("Income-Spend Score Correlation: %.2fn", incomeSpendScoreCorrelation);
// Visualizations would typically require a separate library for Java, such as JFreeChart or JavaFX.
System.out.println("nVisualizations are not implemented in this text-based example.");
}
// Helper method to calculate a simplified correlation
private static double calculateCorrelation(List x, List y) {
if (x.size() != y.size()) throw new IllegalArgumentException("Lists must have the same size");
int n = x.size();
double meanX = x.stream().mapToDouble(a -> a).media().orElse(0);
double meanY = y.stream().mapToDouble(a -> a).media().orElse(0);
double covariance = 0;
double varianceX = 0;
double varianceY = 0;
for (int i = 0; i < n; i++) {
double deltaX = x.get(i) - meanX;
double deltaY = y.get(i) - meanY;
covariance += deltaX * deltaY;
varianceX += deltaX * deltaX;
varianceY += deltaY * deltaY;
}
return covariance / Math.sqrt(varianceX * varianceY);
}
}
Aunque el código Java proporciona funcionalidad para la creación de conjuntos de datos y prospección simples, un longevo exposición requeriría bibliotecas adicionales para visualización.
Mi experiencia usando Canvas
Si correctamente Canvas es compatible con Python, la integración de conjuntos de datos externos puede resultar un desafío oportuno a las restricciones de la zona de pruebas. Sin retención, originar datos sintéticos internamente de Canvas o importar subconjuntos de conjuntos de datos puede mitigar estos problemas. Encima, el código Python se puede portar a otros lenguajes, aunque la ejecución fuera de Python no es compatible con Canvas.
En genérico, Canvas ofrece un entorno colaborativo y obediente de usar. Mejorar su capacidad para integrar datos externos y albergar más lenguajes de programación lo haría aún más versátil y útil.
Conclusión
Codificar con ChatGPT Canvas combina la subvención de IA con un espacio de trabajo colaborativo, lo que la convierte en una aparejo experiencia para los desarrolladores. Ya sea que esté depurando código, analizando datos o generando ideas, Canvas simplifica el proceso y aumenta la productividad.
¿Has probado a codificar con Canvas? Comparta sus experiencias y cuénteme cómo le funcionó en la sección de comentarios a continuación.
Estén atentos a Blog de prospección de Vidhya ¡Para más actualizaciones de este tipo!
Preguntas frecuentes
ChatGPT Canvas es una función que permite a los usuarios editar, colaborar y perfeccionar documentos o códigos extensos directamente conexo con sus conversaciones con ChatGPT.
OpenAI ofrece acercamiento tirado a algunas funciones de ChatGPT, pero las funciones y modelos avanzados a menudo requieren una suscripción paga.
Sí, OpenAI Canvas permite a los usuarios editar y perfeccionar el código directamente conexo con sugerencias impulsadas por IA.
Hola, soy Janvi, un apasionado de la ciencia de datos que actualmente trabaja en Analytics Vidhya. Mi delirio al mundo de los datos comenzó con una profunda curiosidad sobre cómo podemos extraer información significativa de conjuntos de datos complejos.