
Los modelos de jerigonza grandes son buenos en muchas tareas pero malos en razonamientos complejos, especialmente cuando se negociación de problemas matemáticos. Los métodos actuales de educación en contexto (ICL) dependen en gran medida de ejemplos cuidadosamente elegidos y de la ayuda humana, lo que dificulta el manejo de nuevos problemas. Los métodos tradicionales asimismo utilizan técnicas de razonamiento sencillas que limitan su capacidad para apañarse diferentes soluciones, lo que los hace lentos y no adecuados para diversas situaciones. Nuevamente es importante confrontar estos desafíos para mejorar el razonamiento automatizado, la adaptabilidad y el uso adecuado de los LLM.
Las técnicas tradicionales de ICL, como el razonamiento en cautiverio de pensamiento (CoT) y las indicaciones de cero o pocos intentos, han demostrado ser prometedoras para mejorar el rendimiento del razonamiento. CoT permite a los modelos pensar en los problemas paso a paso, lo cual es excelente para resolver problemas estructurados. Sin retención, estos métodos tienen grandes problemas. Su desempeño depende de qué tan buenos sean los ejemplos y cómo estén estructurados, lo que requiere mucha sagacidad para prepararse. Los modelos no pueden adaptarse a problemas que se desvían de sus ejemplos de entrenamiento, reduciendo la utilidad en diversas tareas. Por otra parte, los enfoques actuales se basan en el razonamiento secuencial, lo que restringe la exploración de estrategias alternativas de resolución de problemas. Estas limitaciones han indicado la carestia de marcos innovadores que reduzcan la dependencia humana, mejoren la extensión y optimicen la eficiencia del razonamiento.
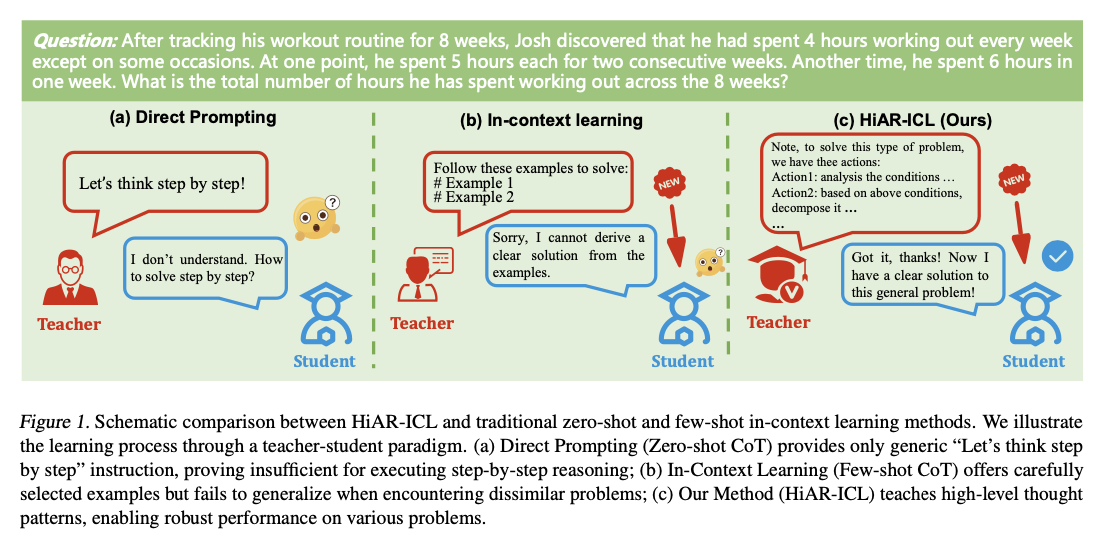
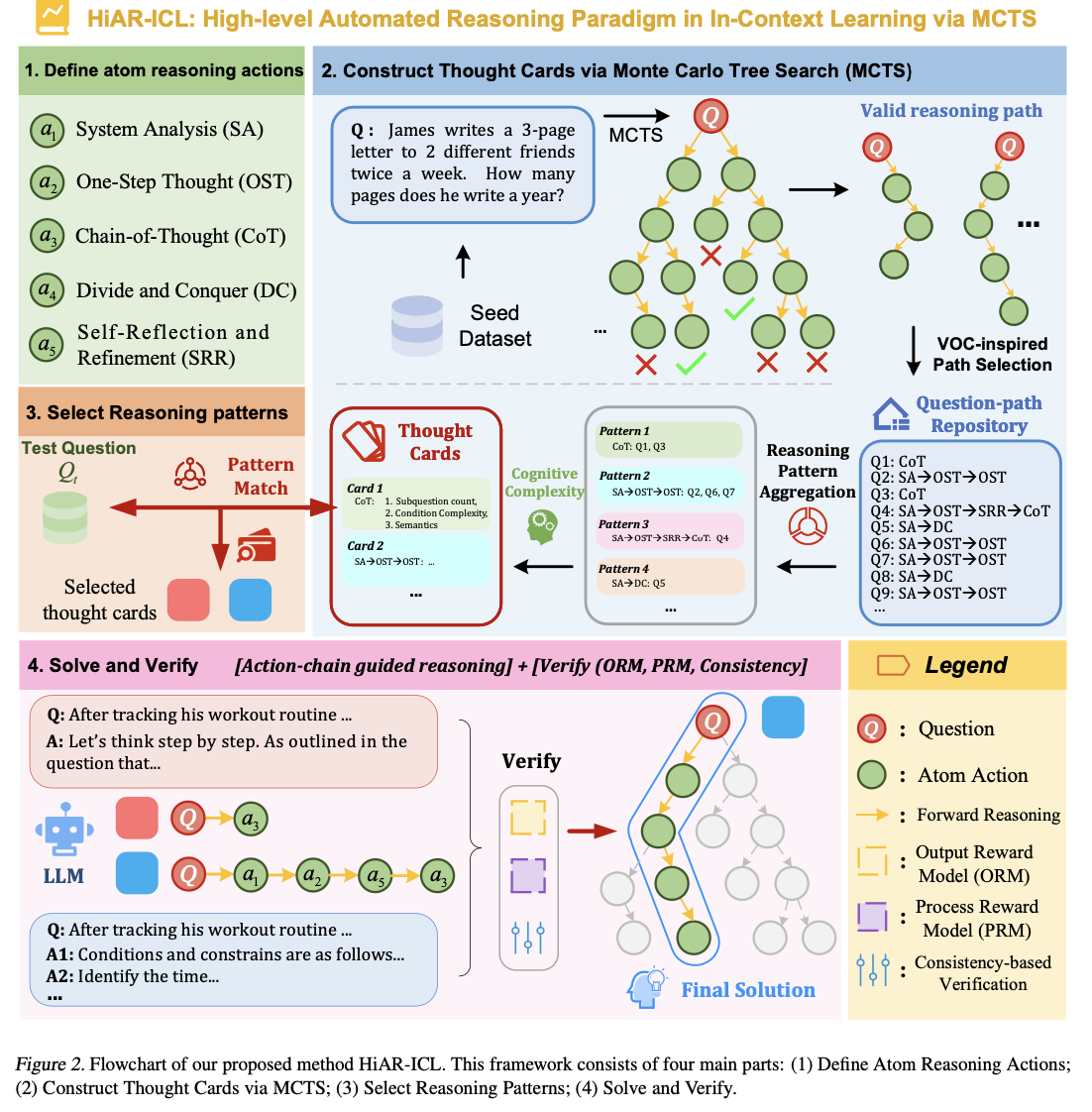
HiAR-ICL (Razonamiento automatizado de suspensión nivel en el educación en contexto) aborda estos desafíos reinventando el «contexto» para que abarque patrones de razonamiento de orden superior en área de centrarse en el educación basado en ejemplos. Este ideal fomenta la adaptabilidad y la solidez en la resolución de problemas al cultivar capacidades de razonamiento transferibles. Agrega cinco procesos de pensamiento destacados: investigación de sistemas (SA), pensamiento de un solo paso (OST), cautiverio de pensamiento (CoT), divide y vencerás (DC) y autorreflexión y refinamiento (SRR), por ejemplo. que funcione como procesos de resolución humanos. Éstas son la pulvínulo sobre la que se construyen las “tarjetas de pensamiento”, plantillas de razonamiento reutilizables, utilizando el mecanismo de búsqueda de árboles de Monte Carlo (MCTS). MCTS identifica rutas de razonamiento óptimamente buenas a partir de un conjunto de datos semilla, que luego se recopilación en plantillas abstractas. Un situación de complejidad cognitiva evalúa los problemas en dimensiones que incluyen el recuento de subpreguntas, la complejidad de las condiciones y la similitud semántica, lo que informa dinámicamente la selección de tarjetas de pensamiento relevantes y precisas. Este proceso de razonamiento dinámico se mejoría aún más mediante técnicas de subsistencia de múltiples capas, que incluyen evaluaciones de autoconsistencia y basadas en recompensas, lo que garantiza precisión y confiabilidad.
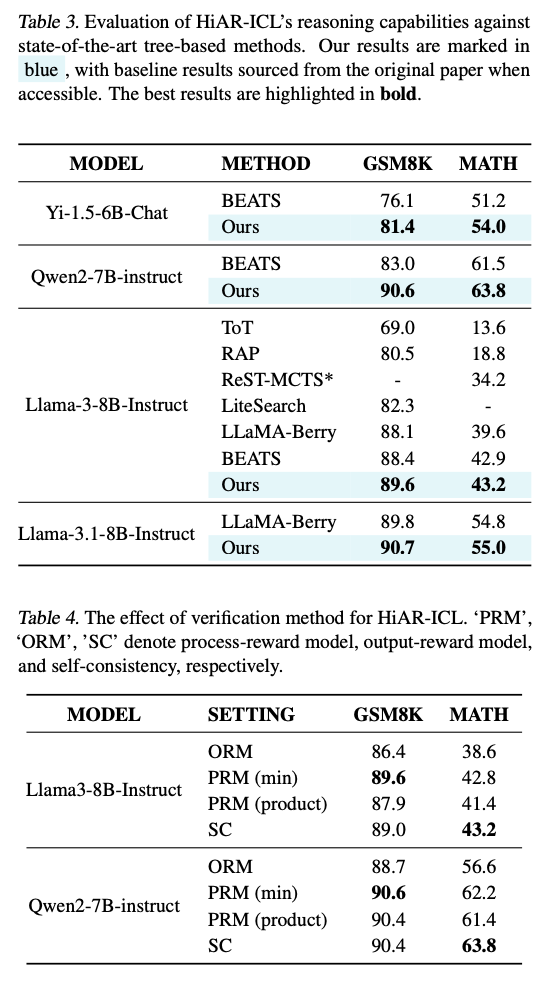
HiAR-ICL demuestra avances significativos en la precisión y eficiencia del razonamiento en varios puntos de narración. Su rendimiento es mejor en conjuntos de datos como MATH, GSM8K y StrategyQA. La precisión aumenta hasta un 27% en comparación con los métodos ICL tradicionales. La eficiencia asimismo es impresionante: el tiempo de procesamiento se reduce hasta 27 veces para tareas más sencillas y hasta 10 veces para problemas más difíciles. Funciona proporcionadamente con aplicaciones variadas e incluso con modelos pequeños; luego, la precisión mejoría en muchas pruebas en más del 10%. Su capacidad de exceder los enfoques tradicionales y al mismo tiempo adaptarse a una variedad de problemas difíciles promete la revolución de esta disciplina.
HiAR-ICL redefine las capacidades de razonamiento en los LLM mediante la transición de paradigmas centrados en ejemplos a marcos cognitivos de suspensión nivel. Monte Carlo Tree Search y el uso de tarjetas de pensamiento para la resolución de problemas lo convierten en una utensilio sólida para trabajar de forma adaptativa con una carestia mínima de ayuda humana. Pudo resistir a la cima cuando su desempeño fue probado con duras pruebas, lo que indica su fortaleza para dar forma al futuro del razonamiento automatizado, especialmente a través del manejo capaz de tareas complejas.
Revisar el Papel. Todo el crédito por esta investigación va a los investigadores de este plan. Por otra parte, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 60.000 ml.
🚨 (Debe asistir al seminario web): ‘Transforme las pruebas de concepto en aplicaciones y agentes de IA listos para producción’ (Promovido)
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el educación instintivo, y aporta una sólida formación académica y experiencia maña en la resolución de desafíos interdisciplinarios de la vida positivo.