
El diseño de automóviles es un proceso iterativo y propietario. Los fabricantes de automóviles pueden producirse varios primaveras en la etapa de diseño de un automóvil, ajustando formas 3D en simulaciones antiguamente de construir los diseños más prometedores para las pruebas físicas. Los detalles y especificaciones de estas pruebas, incluida la aerodinámica de un diseño de automóvil determinado, generalmente no se hacen públicos. Por lo tanto, los avances significativos en el rendimiento, como en la eficiencia del combustible o la autonomía de los vehículos eléctricos, pueden ser lentos y aislados de una empresa a otra.
Los ingenieros del MIT dicen que la búsqueda de mejores diseños de automóviles puede acelerarse exponencialmente con el uso de herramientas de inteligencia químico generativa que pueden analizar enormes cantidades de datos en segundos y encontrar conexiones para originar un diseño novedoso. Si aceptablemente existen tales herramientas de inteligencia químico, los datos de los que necesitarían estudiar no han estado disponibles, al menos en algún tipo de forma accesible y centralizada.
Pero ahora, los ingenieros han puesto a disposición del manifiesto un conjunto de datos de este tipo por primera vez. Apodado DrivAerNet++, el conjunto de datos alpargata más de 8.000 diseños de automóviles, que los ingenieros generaron basándose en los tipos de automóviles más comunes en el mundo presente. Cada diseño está representado en forma 3D e incluye información sobre la aerodinámica del automóvil: la forma en que el clima fluiría rodeando de un diseño determinado, basándose en simulaciones de dinámica de fluidos que el rama llevó a lengua para cada diseño.
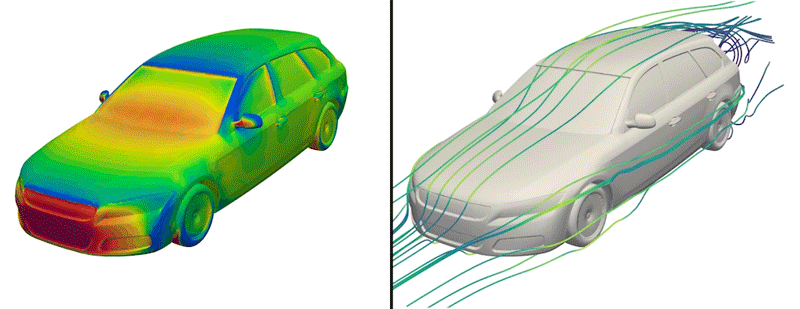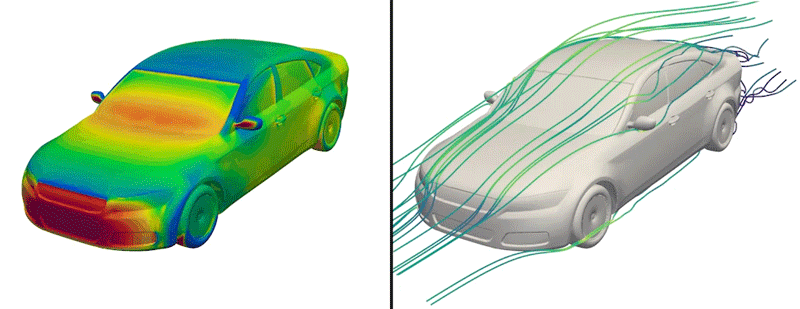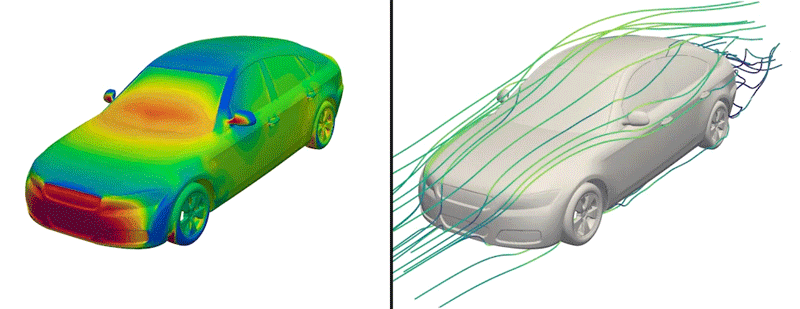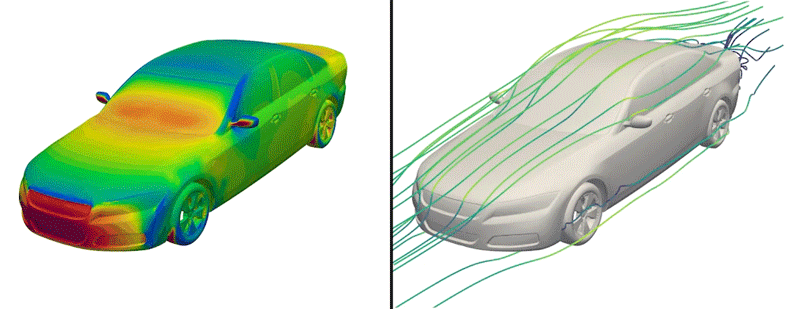
Crédito: Cortesía de Mohamed Elrefaie
Cada uno de los 8000 diseños del conjunto de datos está acondicionado en varias representaciones, como malla, montón de puntos o una relación simple de los parámetros y dimensiones del diseño. Como tal, el conjunto de datos puede ser utilizado por diferentes modelos de IA que estén ajustados para procesar datos en una modalidad particular.
DrivAerNet++ es el conjunto de datos de código amplio más holgado sobre aerodinámica de automóviles que se ha desarrollado hasta la aniversario. Los ingenieros imaginan que se utilizará como una extensa biblioteca de diseños de automóviles realistas, con datos aerodinámicos detallados que se pueden utilizar para entrenar rápidamente cualquier maniquí de IA. Estos modelos pueden originar con la misma celeridad diseños novedosos que potencialmente podrían conducir a automóviles y vehículos eléctricos con decano eficiencia de combustible y decano autonomía, en una fracción del tiempo que le toma a la industria automotriz hoy en día.
«Este conjunto de datos sienta las bases para la próxima coexistentes de aplicaciones de IA en ingeniería, promoviendo procesos de diseño eficientes, reduciendo los costos de I+D e impulsando avances con destino a un futuro automotriz más sostenible», afirma Mohamed Elrefaie, estudiante de postgrado en ingeniería mecánica en el MIT.
Elrefaie y sus colegas presentarán un artículo que detalla el nuevo conjunto de datos y los métodos de IA que podrían aplicarse a él en la conferencia NeurIPS de diciembre. Sus coautores son Faez Ahmed, profesor asistente de ingeniería mecánica en el MIT, contiguo con Angela Dai, profesora asociada de informática en la Universidad Técnica de Munich, y Florin Marar de BETA CAE Systems.
Satisfacer la brecha de datos
Ahmed dirige el Laboratorio de Ingeniería Digital y Computación de Diseño (DeCoDE) en el MIT, donde su rama explora formas en que se pueden utilizar la inteligencia químico y las herramientas de estudios maquinal para mejorar el diseño de sistemas y productos de ingeniería complejos, incluida la tecnología automotriz.
“A menudo, cuando se diseña un automóvil, el proceso de avance es tan costoso que los fabricantes sólo pueden modificar un poco el automóvil de una interpretación a la ulterior”, dice Ahmed. «Pero si tiene conjuntos de datos más grandes donde conoce el rendimiento de cada diseño, ahora puede entrenar modelos de estudios maquinal para que se repitan rápidamente, de modo que sea más probable obtener un mejor diseño».
Y la velocidad, particularmente para el avance de la tecnología automovilística, es particularmente apremiante ahora.
«Este es el mejor momento para acelerar las innovaciones en el sector automovilístico, ya que los automóviles son uno de los mayores contaminadores del mundo, y cuanto más rápido podamos disminuir esa contribución, más podremos ayudar al clima», afirma Elrefaie.
Al observar el proceso de diseño de automóviles nuevos, los investigadores descubrieron que, si aceptablemente existen modelos de IA que podrían analizar muchos diseños de automóviles para originar diseños óptimos, los datos sobre automóviles que efectivamente están disponibles son limitados. Algunos investigadores habían reunido previamente pequeños conjuntos de datos de diseños de automóviles simulados, mientras que los fabricantes de automóviles rara vez publican las especificaciones de los diseños reales que exploran, prueban y, en última instancia, fabrican.
El equipo buscó guatar el infructifero de datos, particularmente con respecto a la aerodinámica de un automóvil, que desempeña un papel secreto en el establecimiento de la autonomía de un transporte eléctrico, y la eficiencia del combustible de un motor de combustión interna. Se dieron cuenta de que el desafío consistía en reunir un conjunto de datos de miles de diseños de automóviles, cada uno de los cuales fuera físicamente preciso en su función y forma, sin el beneficio de probar y cronometrar físicamente su rendimiento.
Para construir un conjunto de datos de diseños de automóviles con representaciones físicamente precisas de su aerodinámica, los investigadores comenzaron con varios modelos 3D básicos proporcionados por Audi y BMW en 2014. Estos modelos representan tres categorías principales de automóviles de pasajeros: fastback (sedanes con parte trasera inclinada extremo), notchback (sedanes o cupés con una ligera caída en su perfil trasero) y allegado (como camionetas con respaldos más planos y contundentes). Se cree que los modelos básicos cierran la brecha entre diseños simples y diseños patentados más complicados, y otros grupos los han utilizado como punto de partida para explorar nuevos diseños de automóviles.
biblioteca de autos
En su nuevo estudio, el equipo aplicó una operación de transformación a cada uno de los modelos de automóvil básicos. Esta operación realizó sistemáticamente un acelerado cambio en cada uno de los 26 parámetros en un diseño de automóvil determinado, como su largura, las características de los bajos, la irresoluto del parabrisas y la pandilla de rodadura de las ruedas, que luego etiquetó como un diseño de automóvil diverso, que luego se agregó a la creciente conjunto de datos. Mientras tanto, el equipo ejecutó un cálculo de optimización para certificar que cada nuevo diseño fuera efectivamente diverso y no una copia de un diseño ya generado. Luego tradujeron cada diseño 3D a diferentes modalidades, de modo que un diseño determinado pueda representarse como una malla, una montón de puntos o una relación de dimensiones y especificaciones.
Los investigadores asimismo realizaron complejas simulaciones computacionales de dinámica de fluidos para calcular cómo fluiría el clima rodeando de cada diseño de automóvil generado. Al final, este esfuerzo produjo más de 8.000 formas de automóviles en 3D distintas y físicamente precisas, que abarcan los tipos de automóviles de pasajeros más comunes que circulan en la ahora.
Para producir este conjunto de datos completo, los investigadores dedicaron más de 3 millones de horas de CPU utilizando MIT SuperCloud y generaron 39 terabytes de datos. (A modo de comparación, se estima que toda la colección impresa de la Biblioteca del Congreso equivaldría a unos 10 terabytes de datos).
Los ingenieros dicen que los investigadores ahora pueden usar el conjunto de datos para entrenar un maniquí de IA particular. Por ejemplo, se podría entrenar un maniquí de IA con una parte del conjunto de datos para estudiar configuraciones de automóviles que tengan cierta aerodinámica deseable. En cuestión de segundos, el maniquí podría originar un nuevo diseño de automóvil con aerodinámica optimizada, basándose en lo que ha aprendido de los miles de diseños físicamente precisos del conjunto de datos.
Los investigadores dicen que el conjunto de datos asimismo podría estar de moda para el objetivo inverso. Por ejemplo, a posteriori de entrenar un maniquí de IA en el conjunto de datos, los diseñadores podrían favorecer el maniquí con un diseño de automóvil específico y hacer que estime rápidamente la aerodinámica del diseño, que luego se puede usar para calcular la eficiencia potencial de combustible o la autonomía eléctrica del automóvil, todo sin soportar a lengua costosa construcción y prueba de un automóvil físico.
«Lo que este conjunto de datos permite hacer es entrenar modelos de IA generativa para que hagan cosas en segundos en punto de horas», dice Ahmed. «Estos modelos pueden ayudar a disminuir el consumo de combustible de los vehículos de combustión interna y aumentar la autonomía de los coches eléctricos, allanando en última instancia el camino para vehículos más sostenibles y respetuosos con el medio circunstancia».
Este trabajo fue apoyado, en parte, por el Servicio Ario de Intercambio Universitario y el Área de Ingeniería Mecánica del MIT.