
Los modelos de verbo egregio de vídeo (VLLM) han surgido como herramientas transformadoras para analizar el contenido de vídeo. Estos modelos destacan en el razonamiento multimodal, integrando datos visuales y textuales para interpretar y replicar a escenarios de vídeo complejos. Sus aplicaciones van desde preguntas y respuestas sobre vídeos hasta resúmenes y descripciones de vídeos. Con su capacidad para procesar entradas a gran escalera y proporcionar horizontes detalladas, son cruciales en tareas que requieren una comprensión destacamento de la dinámica visual.
Un desafío esencia en los VLLM es tramitar los costos computacionales del procesamiento de una gran cantidad de datos visuales a partir de entradas de video. Los vídeos conllevan inherentemente una entrada superfluidad, ya que los fotogramas a menudo capturan información superpuesta. Estos fotogramas generan miles de tokens cuando se procesan, lo que genera un consumo de memoria significativo y velocidades de inferencia más lentas. Topar este problema es fundamental para que los VLLM sean eficientes sin comprometer su capacidad para realizar tareas de razonamiento complejas.
Los métodos actuales han intentado mitigar las limitaciones computacionales mediante la preparación de técnicas de poda de tokens y el diseño de modelos livianos. Por ejemplo, los métodos de poda como FastV aprovechan las puntuaciones de atención para resumir los tokens menos relevantes. Sin retención, estos enfoques a menudo se basan en estrategias de poda estáticas de un solo uso, que pueden eliminar inadvertidamente tokens críticos necesarios para apoyar una entrada precisión. Adicionalmente, las técnicas de reducción de parámetros frecuentemente comprometen la capacidad de razonamiento de los modelos, limitando su aplicación a tareas exigentes.
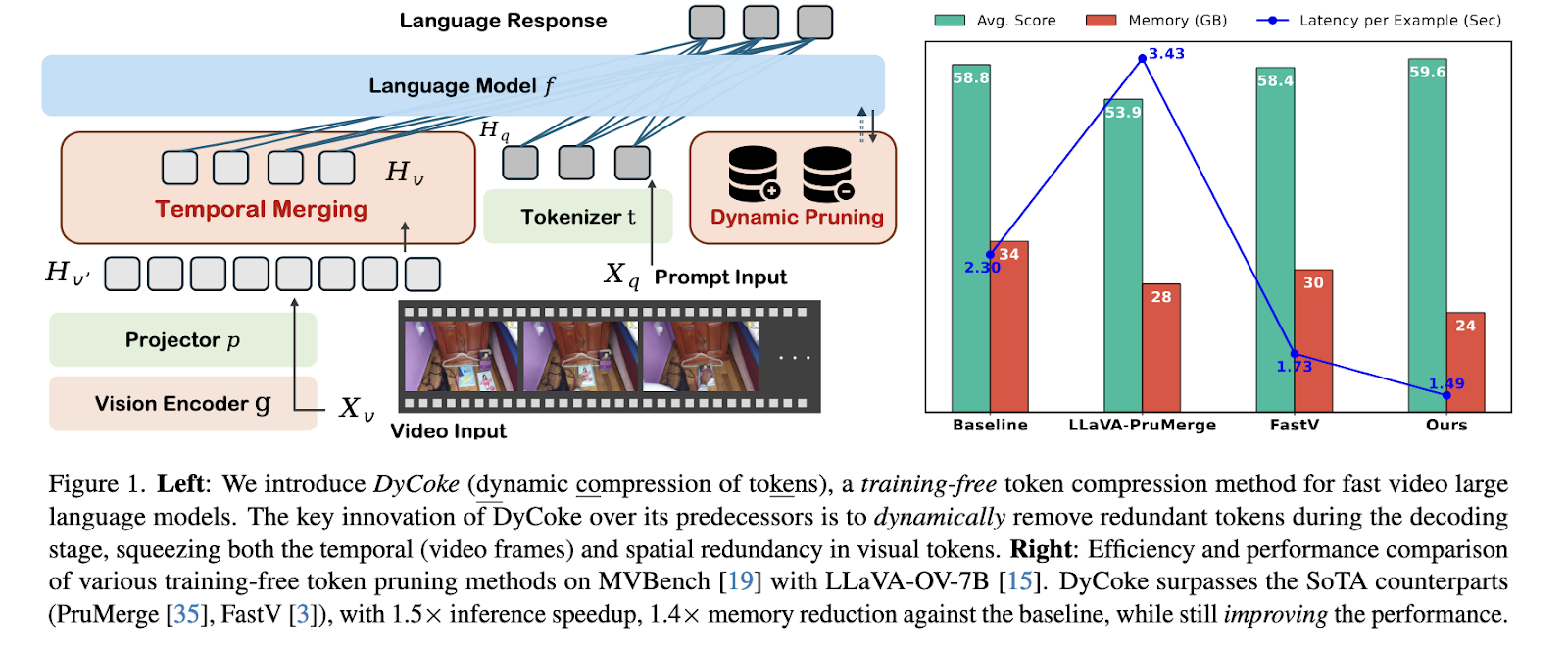
Investigadores de la Universidad de Westlake, Salesforce AI Research, Apple AI/ML y Rice University presentaron DyCoke, un método novedoso diseñado para comprimir dinámicamente tokens en grandes modelos de verbo de vídeo. DyCoke adopta un enfoque sin capacitación y se distingue por tocar las redundancias temporales y espaciales en las entradas de video. Al implementar mecanismos de poda dinámicos y adaptativos, el método optimiza la eficiencia computacional preservando al mismo tiempo un parada rendimiento. Esta innovación tiene como objetivo hacer que los VLLM sean escalables para aplicaciones del mundo verdadero sin requerir ajustes ni capacitación adicional.
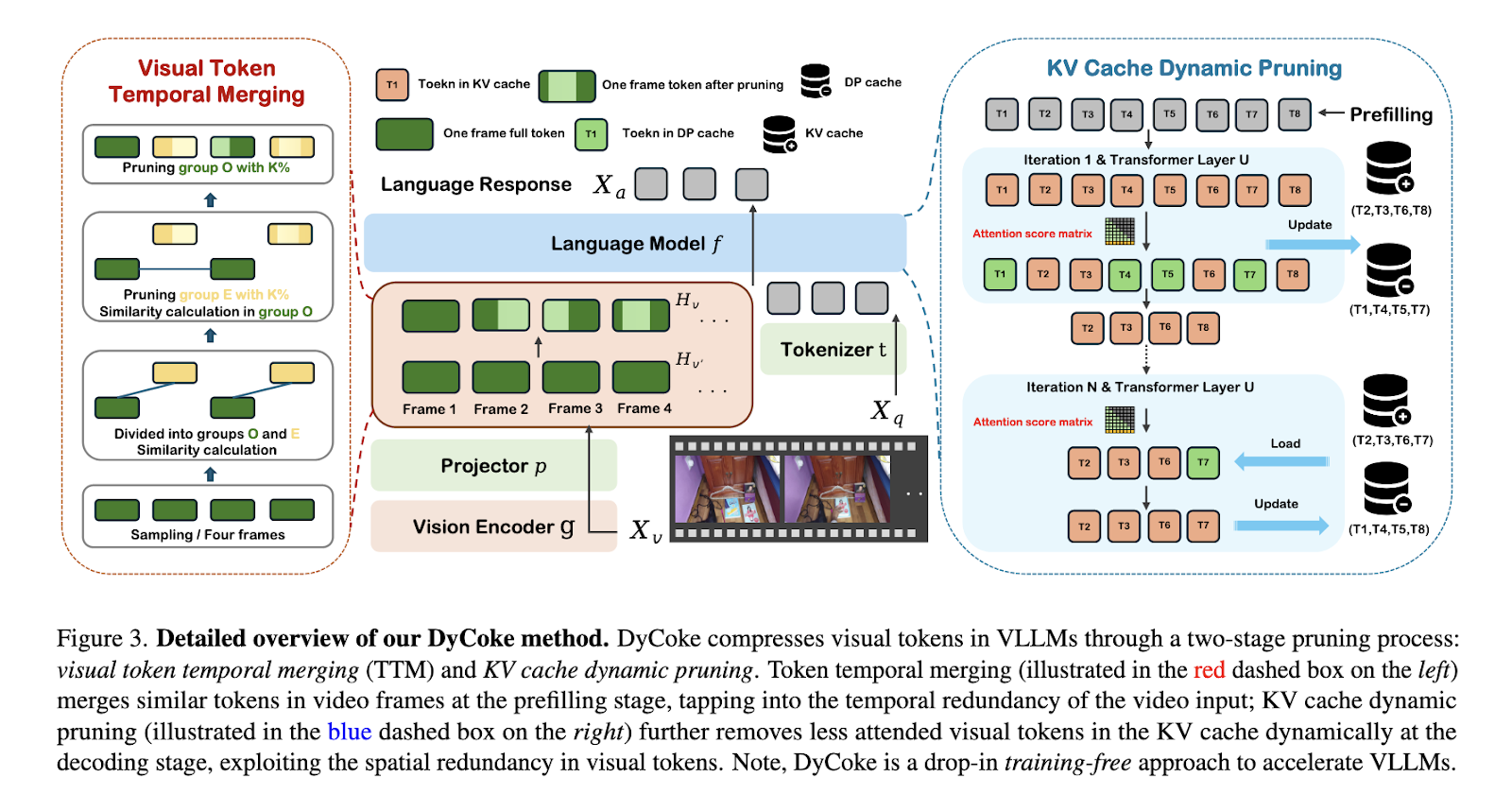
DyCoke emplea un proceso de dos etapas para la compresión de tokens. La fusión de tokens temporales consolida tokens redundantes en fotogramas de vídeo adyacentes en la primera etapa. Este módulo agrupa marcos en ventanas de muestreo e identifica información superpuesta, fusionando tokens para retener solo los distintos y representativos. Por ejemplo, se reduce eficazmente la superfluidad visual en fondos estáticos o acciones repetidas. Durante la escalón de decodificación, la segunda etapa emplea una técnica de poda dinámica en la gusto de títulos esencia (KV). Los tokens se evalúan y retienen dinámicamente en función de sus puntuaciones de atención. Este paso garantiza que solo queden los tokens más críticos, mientras que los tokens irrelevantes se almacenan en una gusto de poda dinámica para su posible reutilización. Al refinar iterativamente la gusto KV en cada paso de decodificación, DyCoke alinea la carga computacional con el significado verdadero de los tokens.
Los resultados de DyCoke destacan su eficiencia y robustez. En puntos de narración como MVBench, que incluye 20 tareas complejas como registro de acciones e interacción de objetos, DyCoke logró una apresuramiento de inferencia de hasta 1,5 veces y una reducción de 1,4 veces en el uso de memoria en comparación con los modelos de narración. Específicamente, el método redujo la cantidad de tokens retenidos hasta un 14,25% en algunas configuraciones, con una degradación mínima del rendimiento. En el conjunto de datos VideoMME, DyCoke se destacó en el procesamiento de largas secuencias de vídeo, demostrando una eficiencia superior al tiempo que mantenía o superaba la precisión de los modelos sin comprimir. Por ejemplo, con una tasa de poda de 0,5 logró una reducción de latencia de hasta un 47%. Superó a métodos de última engendramiento como FastV a la hora de apoyar la precisión en tareas como el razonamiento secundario y la navegación egocéntrica.
La contribución de DyCoke va más allá de la velocidad y la eficiencia de la memoria. Simplifica las tareas de razonamiento en video al resumir la superfluidad temporal y espacial en las entradas visuales, equilibrando efectivamente el rendimiento y la utilización de capital. A diferencia de los métodos anteriores que requerían una amplia formación, DyCoke funciona como una posibilidad plug-and-play, lo que la hace accesible para una amplia tonalidad de modelos de verbo de vídeo. Su capacidad para ajustar dinámicamente la retención de tokens garantiza que se conserve la información crítica, incluso en escenarios de inferencia exigentes.

En normal, DyCoke representa un importante paso delante en la crecimiento de las VLLM. Topar los desafíos computacionales inherentes al procesamiento de video permite que estos modelos funcionen de forma más válido sin comprometer sus capacidades de razonamiento. Esta innovación avanza en la comprensión del vídeo de última engendramiento y abre nuevas posibilidades para implementar VLLM en escenarios del mundo verdadero donde los capital computacionales suelen ser limitados.
Corroborar el papel y GitHub. Todo el crédito por esta investigación va a los investigadores de este tesina. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
Nikhil es asesor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida formación en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.