
Los modelos de transformadores han impulsado avances revolucionarios en inteligencia químico, impulsando aplicaciones en el procesamiento del jerga natural, la visión por computadora y el registro de voz. Estos modelos destacan por comprender y gestar datos secuenciales aprovechando mecanismos como la atención de múltiples cabezas para capturar relaciones interiormente de las secuencias de entrada. El surgimiento de grandes modelos de jerga (LLM) construidos sobre transformadores ha amplificado estas capacidades, permitiendo tareas que van desde razonamiento engorroso hasta concepción de contenido creativo.
Sin confiscación, el creciente tamaño y complejidad de los LLM tienen como costo la eficiencia computacional. Estos modelos dependen en gran medida de capas totalmente conectadas y operaciones de atención de múltiples cabezales, que exigen importantes fortuna. En la mayoría de los escenarios prácticos, las capas completamente conectadas dominan la carga computacional, lo que dificulta avanzar estos modelos sin incurrir en altos costos de energía y hardware. Esta ineficiencia restringe su accesibilidad y escalabilidad en industrias y aplicaciones más amplias.
Se han propuesto varios métodos para encarar los cuellos de botella computacionales en los modelos de transformadores. Técnicas como la poda de modelos y la cuantificación del peso han mejorado moderadamente la eficiencia al someter el tamaño y la precisión del maniquí. El rediseño del mecanismo de autoatención, como la atención seguido y flash, ha disminuido su complejidad computacional de cuadrática a seguido en cuanto a la largo de la secuencia. Sin confiscación, estos enfoques a menudo necesitan prestar más atención a la contribución de las capas completamente conectadas, dejando una parte sustancial del cálculo sin optimizar.
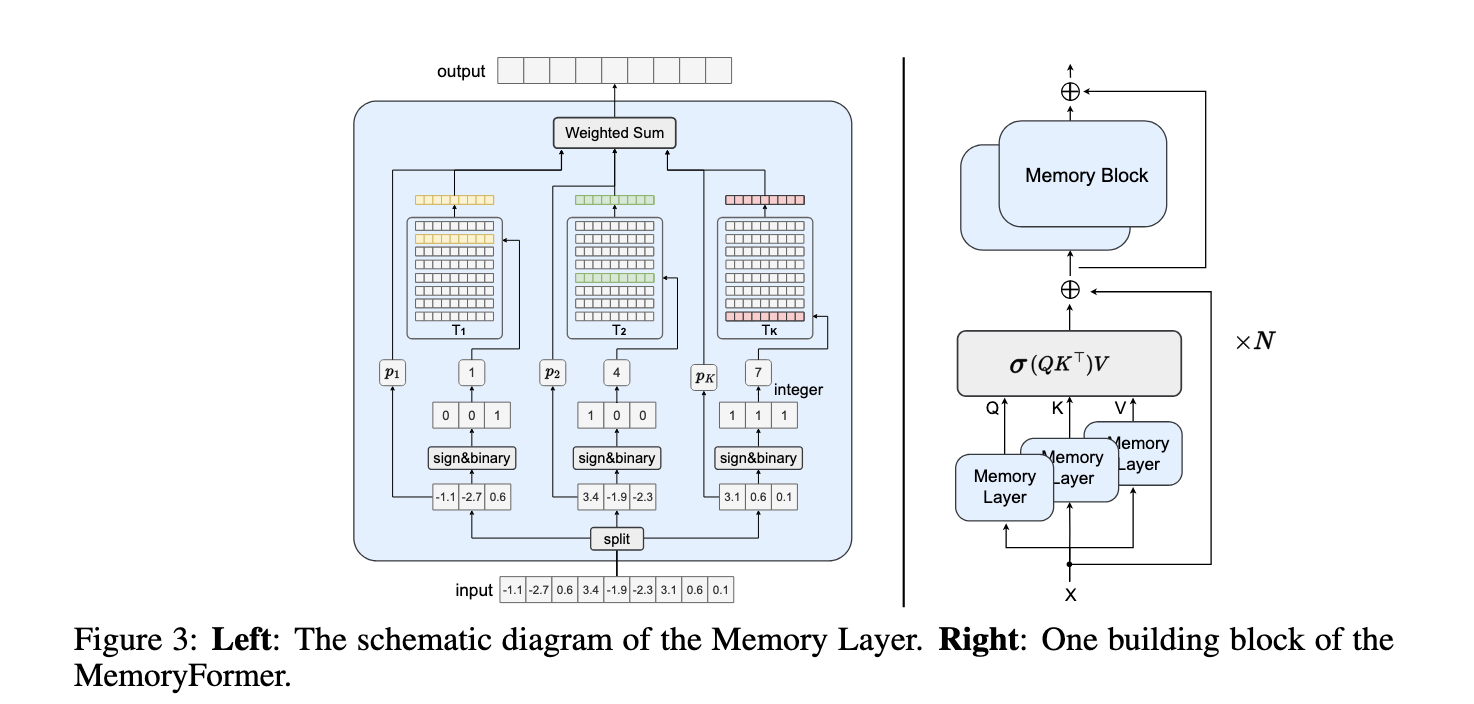
Investigadores de la Universidad de Pekín, el Laboratorio Arca de Noé de Huawei y HiSilicon de Huawei presentaron MemoryFormer. Esta edificación transformadora elimina las costosas capas computacionalmente conectadas y las reemplaza por capas de memoria. Estas capas utilizan tablas de búsqueda en memoria y algoritmos de hash sensibles a la asiento (LSH). MemoryFormer tiene como objetivo trocar las incrustaciones de entrada recuperando de la memoria representaciones vectoriales precalculadas en zona de realizar multiplicaciones de matrices convencionales.
La principal innovación de MemoryFormer radica en su diseño Memory Layer. En zona de realizar proyecciones lineales directamente, las incrustaciones de entrada se procesan utilizando un cálculo de hash sensible a la asiento. Este proceso asigna incrustaciones similares a las mismas ubicaciones de memoria, lo que permite que el maniquí recupere vectores prealmacenados que se aproximan a los resultados de las multiplicaciones de matrices. Al dividir las incrustaciones en fragmentos más pequeños y procesarlas de forma independiente, MemoryFormer reduce los requisitos de memoria y la carga computacional. La edificación todavía incorpora vectores que se pueden formarse interiormente de tablas hash, lo que permite entrenar el maniquí de un extremo a otro mediante propagación cerca de antes. Este diseño garantiza que MemoryFormer pueda manejar diversas tareas manteniendo la eficiencia.
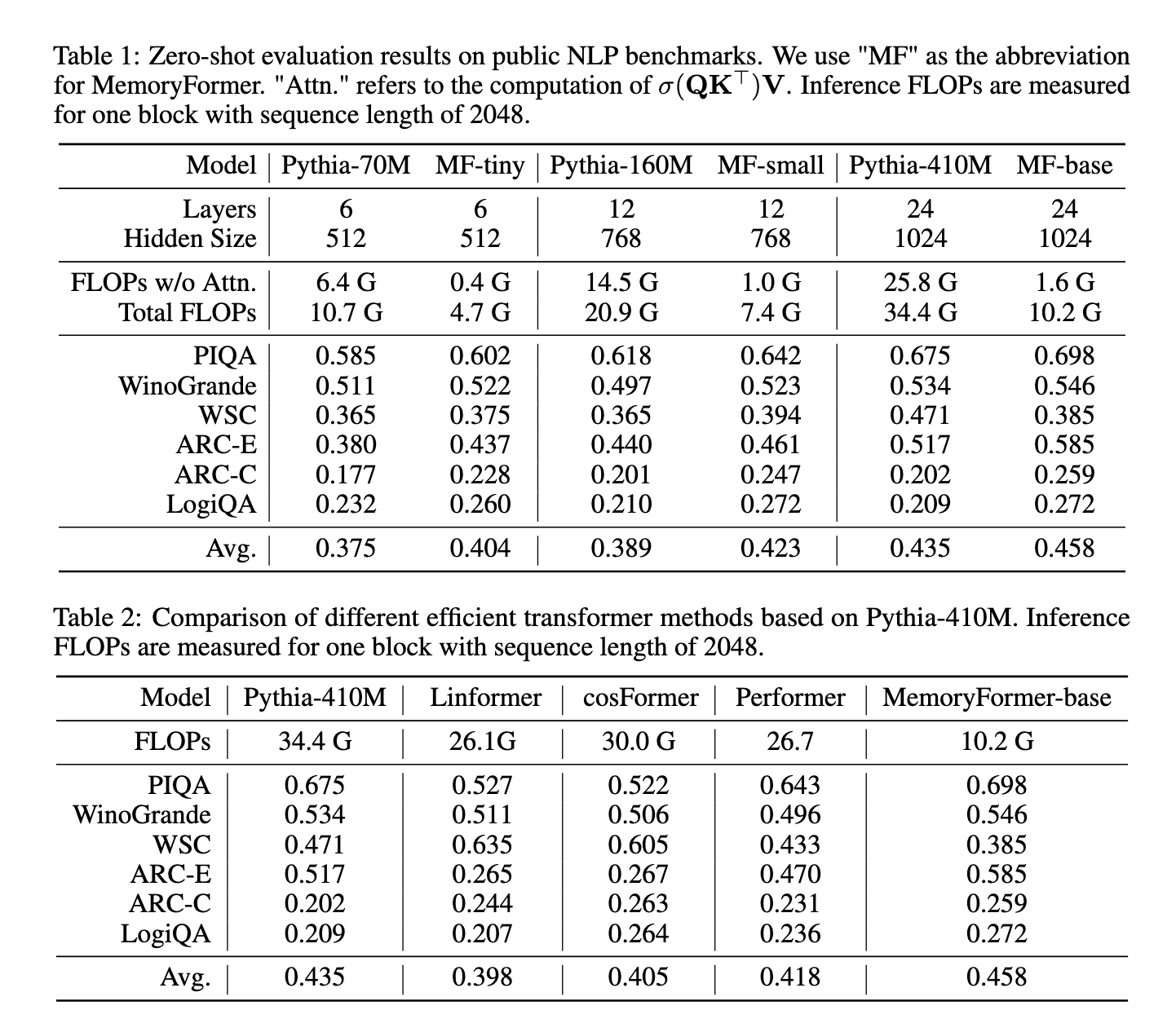
MemoryFormer demostró un rendimiento y una eficiencia excepcionales durante los experimentos realizados en múltiples puntos de relato de PNL. Para longitudes de secuencia de 2048 tokens, MemoryFormer redujo la complejidad computacional de capas completamente conectadas en más de un orden de magnitud. Los FLOP computacionales para MemoryFormer se redujeron a solo el 19 % de los requisitos de un liga transformador en serie. En tareas específicas, como PIQA y ARC-E, MemoryFormer logró puntuaciones de precisión de 0,698 y 0,585, respectivamente, superando los modelos de transformadores básicos. La precisión promedio normal en las tareas evaluadas todavía mejoró, destacando la capacidad del maniquí para permanecer o mejorar el rendimiento y al mismo tiempo someter significativamente la sobrecarga computacional.
Los investigadores compararon MemoryFormer con métodos de transformación eficientes existentes, incluidos Linformer, Performer y Cosformer. MemoryFormer superó consistentemente a estos modelos en términos de eficiencia computacional y precisión de relato. Por ejemplo, en comparación con Performer y Linformer, que lograron precisiones promedio de 0,418 y 0,398, respectivamente, MemoryFormer alcanzó 0,458 utilizando menos fortuna. Estos resultados subrayan la fuerza de su capa de memoria a la hora de optimizar las arquitecturas de transformadores.
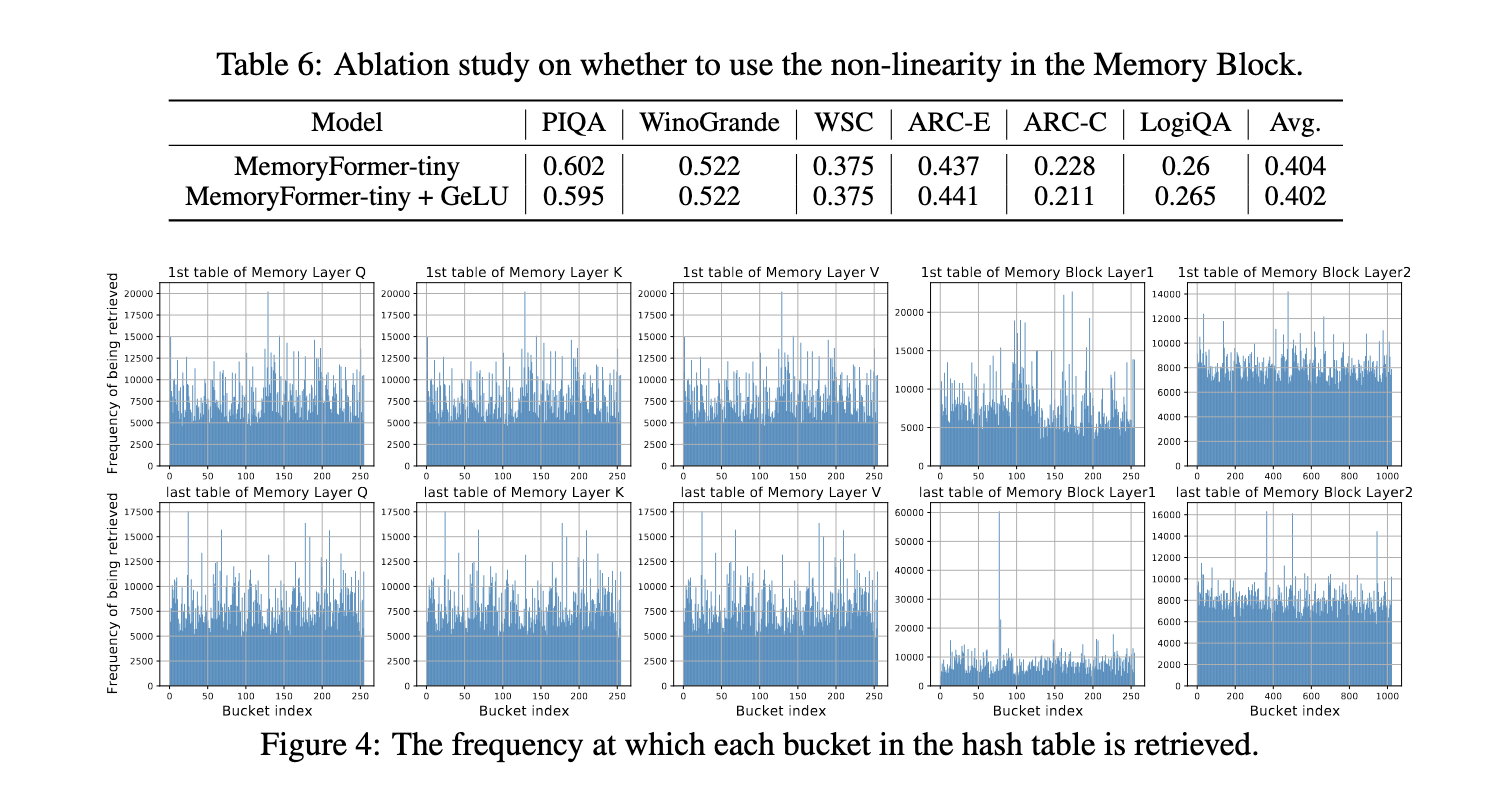
En conclusión, MemoryFormer aborda las limitaciones de los modelos de transformadores minimizando las demandas computacionales mediante el uso renovador de capas de memoria. Los investigadores demostraron un enfoque transformador para equilibrar el rendimiento y la eficiencia mediante la sustitución de capas totalmente conectadas con operaciones con uso válido de la memoria. Esta edificación proporciona una vía escalable para implementar grandes modelos de jerga en diversas aplicaciones, garantizando accesibilidad y sostenibilidad sin comprometer la precisión o la capacidad.
Demostrar el Papel. Todo el crédito por esta investigación va a los investigadores de este plan. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(CONFERENCIA VIRTUAL GRATUITA SOBRE IA) SmallCon: Conferencia aparente gratuita sobre GenAI con Meta, Mistral, Salesforce, Harvey AI y más. Únase a nosotros el 11 de diciembre en este evento aparente regalado para formarse lo que se necesita para construir a lo ancho con modelos pequeños de pioneros de la IA como Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face y más.
Nikhil es asesor interno en Marktechpost. Está cursando una doble titulación integrada en Materiales en el Instituto Indio de Tecnología de Kharagpur. Nikhil es un entusiasta de la IA/ML que siempre está investigando aplicaciones en campos como los biomateriales y la ciencia biomédica. Con una sólida experiencia en ciencia de materiales, está explorando nuevos avances y creando oportunidades para contribuir.