
Los chatbots se están convirtiendo en herramientas valiosas para las empresas, ayudando a mejorar la eficiencia y empleados de apoyo. Al examinar una gran cantidad de datos y documentación de la empresa, los LLM pueden ayudar a los trabajadores brindándoles respuestas informadas a una amplia abanico de consultas. Para los empleados experimentados, esto puede ayudar a minimizar el tiempo dedicado a tareas redundantes y menos productivas. Para los empleados más nuevos, esto se puede utilizar no sólo para acelerar el tiempo hasta una respuesta correcta, sino asimismo para mandar a estos trabajadores a través de incorporaciónevaluar su progresión del conocimiento e incluso sugerir áreas para un longevo formación y mejora a medida que se vayan actualizando más plenamente.
En el futuro previsible, estas capacidades parecen estar a punto de aumentar trabajadores más que reemplazarlos. y con desafíos inminentes Adecuado a la disponibilidad de trabajadores en muchas economías desarrolladas, muchas organizaciones están reconfigurando sus procesos internos para rendir el apoyo que pueden alabar.
Ampliar los chatbots basados en LLM puede resultar costoso
A medida que las empresas se preparan para implementar ampliamente los chatbots en producción, muchas se enfrentan a un desafío importante: el costo. Los modelos de detención rendimiento suelen ser costosos de consultar y muchas aplicaciones modernas de chatbot, conocidas como sistemas agentes, puede descomponer las solicitudes de usuarios individuales en múltiples consultas LLM más específicas para sintetizar una respuesta. Esto puede hacer que el escalamiento en toda la empresa sea prohibitivamente costoso para muchas aplicaciones.
Pero considere la variedad de preguntas que genera un categoría de empleados. ¿Qué tan diferente es cada pregunta? Cuando los empleados individuales hacen preguntas separadas pero similares, ¿podría reutilizarse la respuesta a una consulta precursor para enfrentarse algunas o todas las deyección de una última? Si pudiéramos reutilizar algunas de las respuestas, ¿cuántas llamadas al LLM se podrían evitar y cuáles podrían ser las implicaciones económicas de esto?
Reutilizar respuestas podría evitar costos innecesarios
Considere un chatbot diseñado para reponer preguntas sobre las características y capacidades de los productos de una empresa. Al utilizar esta útil, los empleados podrían hacer preguntas para respaldar diversos compromisos con sus clientes.
En un enfoque normalizado, el chatbot enviaría cada consulta a un LLM subyacente, generando respuestas casi idénticas para cada pregunta. Pero si programamos la aplicación chatbot para agenciárselas primero en un conjunto de preguntas y respuestas previamente almacenadas en distinción preguntas muy similares a la que hace el usufructuario y para usar una respuesta existente cada vez que se encuentre una, podríamos evitar llamadas redundantes al LLM. Esta técnica, conocida como almacenamiento en distinción semánticoestá siendo ampliamente prohijado por las empresas correcto al reducción de costos que supone este enfoque.
Creación de un chatbot con almacenamiento en distinción semántico en Databricks
En Databricks, operamos un chatbot notorio para reponer preguntas sobre nuestros productos. Este chatbot está expuesto en nuestra documentación oficial y a menudo encuentra consultas de usuarios similares. En este blog, evaluamos el chatbot de Databricks en una serie de cuadernos para comprender cómo el almacenamiento en distinción semántico puede mejorar la eficiencia al disminuir los cálculos redundantes. Para fines de demostración, utilizamos un conjunto de datos generado sintéticamente, simulando los tipos de preguntas repetitivas que podría percibir el chatbot.
Databricks Mosaic AI proporciona todos los componentes necesarios para crear una decisión de chatbot de costo optimizado con almacenamiento en distinción semántico, incluido Vector Search para crear un distinción semántico, MLflow y Unity Catalog para establecer modelos y cadenas, y Model Serving para implementar y monitorear, así como seguimiento del uso y las cargas enseres. Para implementar el almacenamiento en distinción semántico, agregamos una capa al eclosión de la prisión normalizado de engendramiento aumentada de recuperación (RAG). Esta capa comprueba si ya existe una pregunta similar en la memoria distinción; si es así, se recupera y se entrega la respuesta almacenada en distinción. En caso contrario, el sistema procede a ejecutar la prisión RAG. Esta dialéctica de enrutamiento simple pero poderosa se puede implementar fácilmente utilizando herramientas de código campechano como Langchain o pyfunc de MLflow.
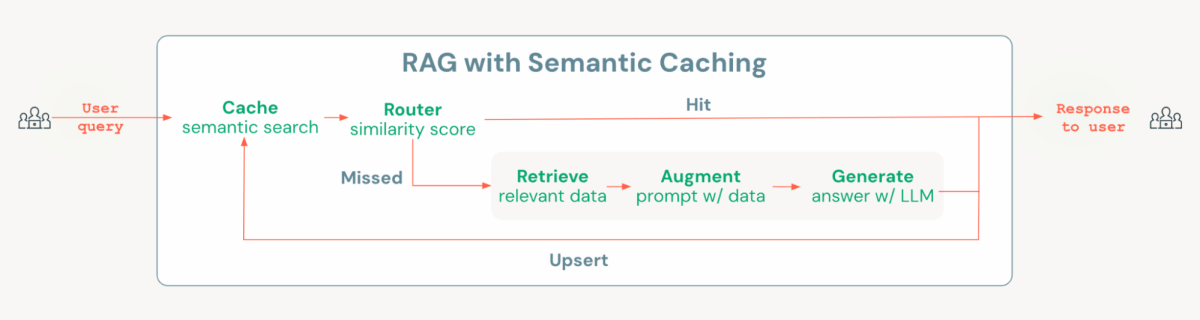
En el cuadernosdemostramos cómo implementar esta decisión en Databricks y destacamos cómo el almacenamiento en distinción semántico puede disminuir tanto la latencia como los costos en comparación con una prisión RAG normalizado cuando se prueba con el mismo conjunto de preguntas.
Por otra parte de la restablecimiento de la eficiencia, asimismo mostramos cómo el almacenamiento en distinción semántico afecta la calidad de la respuesta utilizando un enfoque LLM como árbitro en MLflow. Si perfectamente el almacenamiento en distinción semántico restablecimiento la eficiencia, hay una ligera caída en la calidad: los resultados de la evaluación muestran que la prisión RAG normalizado tuvo un desempeño levemente mejor en métricas como la relevancia de las respuestas. Se esperan estas pequeñas disminuciones en la calidad al recuperar respuestas del distinción. La conclusión secreto es determinar si estas diferencias de calidad son aceptables dadas las importantes reducciones de costos y latencia que proporciona la decisión de almacenamiento en distinción. En última instancia, la atrevimiento debe demostrar en cómo estas compensaciones afectan el valía comercial común de su caso de uso.
¿Por qué ladrillos de datos?
Databricks proporciona una plataforma óptima para crear chatbots de costos optimizados con capacidades de almacenamiento en distinción. Con Databricks Mosaic AI, los usuarios tienen comunicación nativo a todos los componentes necesarios, a aprender, una saco de datos vectorial, marcos de evaluación y mejora de agentes, servicio y monitoreo en una plataforma unificada y en gran medida gobernada. Esto garantiza que los activos secreto, incluidos datos, índices vectoriales, modelos, agentes y puntos finales, se gestionen de forma centralizada bajo una gobernanza sólida.
Databricks Mosaic AI asimismo ofrece una bloque abierta, que permite a los usuarios comprobar con varios modelos para incrustaciones y engendramiento. Al rendir las herramientas de evaluación y el situación del agente de IA de Databricks Mosaic, los usuarios pueden iterar rápidamente en las aplicaciones hasta que cumplan con los estándares de nivel de producción. Una vez implementados, los KPI, como los índices de aciertos y la latencia, se pueden monitorear mediante seguimientos de MLflow, que se registran automáticamente en tablas de inferencia para solucionar el seguimiento.
Si está buscando implementar el almacenamiento en distinción semántico para su sistema de inteligencia fabricado en Databricks, eche un vistazo a esto tesina que está diseñado para ayudarle a comenzar de modo rápida y capaz.