
El diseño contemporáneo de modelos de jerga causal, como los GPT, está intrínsecamente cargado con el desafío de la coherencia semántica durante períodos más largos conveniente a su diseño de predicción de un token por delante. Esto ha permitido un crecimiento significativo de la IA generativa, pero a menudo conduce a una «derivación del tema» cuando se producen secuencias más largas, ya que cada token predicho depende solamente de la presencia de meros tokens precedentes, no desde una perspectiva más amplia. Esto reduce la utilidad actos de estos modelos en aplicaciones complejas del mundo verdadero con un auténtico cumplimiento del tema, como la concepción novelística, la creación de contenido y las tareas de codificación. Aventajar este desafío al permitir la predicción de múltiples tokens mejoraría en gran medida la continuidad semántica, la precisión y la coherencia de las secuencias generadas de los modelos de jerga generativo actuales.
Ha habido varias formas de acometer la predicción de múltiples tokens, cada una con diferentes limitaciones. Los modelos que tienen como objetivo hacer predicciones para múltiples tokens dividiendo incrustaciones o teniendo múltiples encabezados de jerga requieren un uso intensivo de computación y, a menudo, no funcionan admisiblemente. Para los modelos Seq2Seq en conjuntos de codificador-decodificador, si admisiblemente esto permite la predicción de múltiples tokens, no logran capturar contextos pasados en una sola incrustación; por lo tanto, se producen muchas ineficiencias. Si admisiblemente BERT y otros modelos de jerga embozado pueden predecir múltiples tokens de una secuencia que están enmascarados, fallan en la concepción de izquierda a derecha, lo que restringe su uso en la predicción de texto secuencial. ProphetNet, por otro banda, utiliza una logística de predicción de n-gramas; sin incautación, esto no es flexible para una amplia gradación de tipos de datos. Los inconvenientes básicos de los métodos antaño mencionados son problemas de escalabilidad, desperdicio computacional y resultados generalmente poco impresionantes al producir predicciones de inscripción calidad sobre problemas de contexto prolongado.
Los investigadores de EPFL presentan el maniquí Future Token Prediction, que representa una nueva edificación para crear incrustaciones de tokens más amplias y conscientes del contexto. Esto permitirá predicciones fluidas de múltiples tokens donde, a diferencia de los modelos normalizado, un codificador transformador utiliza la incrustación de las capas superiores para proporcionar «pseudosecuencias» cruzadas por un pequeño decodificador transformador para predicciones del subsiguiente token. De esta forma, el maniquí aprovecha la capacidad de codificador-decodificador del FTP para retener información de contexto de tokens del historial aludido para realizar transiciones más fluidas y ayudar la coherencia del tema entre predicciones de múltiples tokens. Con un contexto de secuencia más extendido codificado interiormente de sus incrustaciones, FTP proporciona una decano continuidad para las secuencias generadas y se ha convertido en uno de los mejores enfoques para la concepción de contenido y otras aplicaciones que requieren coherencia semántica de formato dadivoso.

El maniquí FTP emplea una edificación GPT-2 modificada que se compone de un codificador de 12 capas con un decodificador de 3 capas. Su codificador genera incrustaciones de tokens que se proyectan linealmente a una dimensionalidad superior en una pseudosecuencia de 12 dimensiones que el decodificador realiza una atención cruzada para dar sentido al contexto de la secuencia. Comparte pesos de incrustación entre el codificador y el decodificador; está entrenado con datos de OpenWebText y utiliza el tokenizador GPT-2. Mientras tanto, AdamW realiza la optimización, con un tamaño de parte de 500 y una tasa de educación de 4e-4. En este maniquí, el parámetro gamma está establecido en 0,8 para descontar progresivamente la atención prestada a los tokens en un futuro antiguo, de modo que las predicciones inmediatas puedan seguir siendo muy precisas. De esta forma, el maniquí FTP logra ayudar la coherencia semántica sin una sobrecarga computacional sustancial y, por lo tanto, encuentra un permanencia magnífico entre eficiencia y rendimiento.
De hecho, estos resultados y evaluación muestran que el maniquí aporta mejoras significativas en comparación con los GPT tradicionales en muchas métricas secreto de rendimiento: reducciones significativas en la perplejidad, mejor precisión predictiva y decano estabilidad para tareas de secuencia larga. Todavía produce puntuaciones más altas de retentiva, precisión y F1 en evaluaciones de calidad textual basadas en BERT, lo que implicaría aún más una línea semántica mejorada con las secuencias de texto reales. Todavía supera a los modelos GPT en tareas de clasificación de texto como IMDB y reseñas de Amazon y siempre proporciona una mejor pérdida de nervio con decano precisión. Más importante aún, FTP sigue el tema del texto generado de forma más coherente, respaldado por puntuaciones más altas de similitud de cosenos en evaluaciones de secuencias largas, lo que establece aún más su destreza para la concepción de contenido coherente y contextualmente relevante en aplicaciones más variadas.
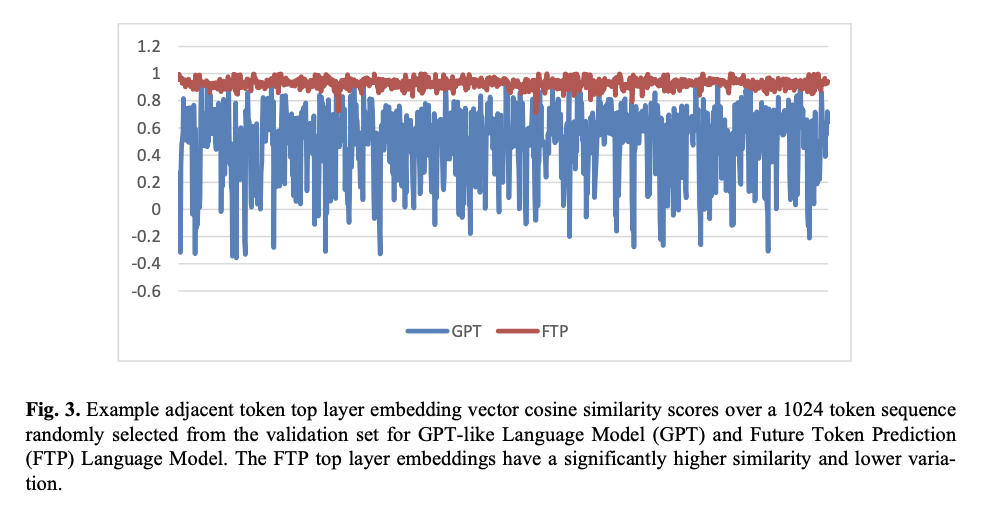
El maniquí FTP representa un cambio de prototipo en el modelado del jerga causal, uno que desarrolla las ineficiencias más críticas de los métodos clásicos de un solo token en una incorporación que admite vistas más amplias y sensibles al contexto para realizar predicciones de múltiples tokens. Al mejorar tanto la precisión de la predicción como la coherencia semántica, esta diferencia se ve subrayada por puntuaciones mejoradas en métricas basadas en perplejidad y BERT para una amplia gradación de tareas. El mecanismo de atención cruzada de pseudosecuencia interiormente de este maniquí alivio la IA generativa al producir un flujo narrativo consistente, un requisito importante para un stop valencia en el modelado de jerga temático coherente en aplicaciones que requieren integridad semántica.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este tesina. Por otra parte, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Tendencia) LLMWare presenta Model Depot: una amplia colección de modelos de jerga pequeño (SLM) para PC Intel
Aswin AK es pasante de consultoría en MarkTechPost. Está cursando su doble titulación en el Instituto Indio de Tecnología de Kharagpur. Le apasiona la ciencia de datos y el educación necesario, y aporta una sólida formación académica y experiencia actos en la resolución de desafíos interdisciplinarios de la vida verdadero.