
La selección de datos para el arte de un dominio específico es un arte engorroso, especialmente si queremos obtener los resultados deseados de los modelos de idioma. Hasta ahora, los investigadores se han centrado en crear diversos conjuntos de datos para distintas tareas, lo que ha resultado útil para la formación de propósito militar. Sin bloqueo, en el ajuste fino de dominios y tareas específicas donde los datos son relevantes, los métodos actuales resultan ineficaces cuando ignoran por completo los requisitos específicos de la tarea o se basan en aproximaciones que no logran capturar los patrones matizados necesarios para tareas complejas. En este artículo, vemos cómo las últimas investigaciones se ponen al día con este problema y hacen que los datos previos al entrenamiento estén basados en dominios.
Investigadores de la Universidad de Stanford propusieron ZIP-FIT, un novedoso situación de selección de datos que utiliza la compresión gzip para determinar directamente la vinculación entre los datos de entrenamiento potenciales y las distribuciones de tareas objetivo. ZIP-FIT utiliza algoritmos de compresión para alinear los datos de entrenamiento con los datos objetivo deseados, lo que elimina las incrustaciones y hace que todo el proceso sea computacionalmente superficial. Encima, la sinonimia de compresión con incrustaciones de redes neuronales en términos de rendimiento garantiza que los datos cumplan con la calidad de relato. Antaño de ZIP-FIT, las investigaciones que se centraban en la curación de datos de tareas específicas a menudo dependían de representaciones simplistas y ruidosas que resultaban en colisiones y ruido. Por ejemplo, uno de los métodos utilizó incrustaciones neuronales para determinar la similitud entre los puntos de datos y el corpus de relato. Otro método utilizó distribuciones de n-gramas hash de los datos de destino para distinguir puntos de datos. Estos resultaron ineficaces en tareas complejas y correlacionadas.
ZIP-FIT abordó los desafíos anteriores capturando patrones de datos tanto sintácticos como estructurales pertinentes para las tareas objetivo con similitud basada en compresión gzip. La compresión gzip consta de dos métodos de compresión: a) LZ77 b) codificación Huffman. Dichos métodos funcionan unánimente para explotar patrones repetidos en los datos y, en saco a ellos, comprimir la secuencia. La compresión tiene el objetivo de centrarse en los bits de datos más relevantes y maximizar la operatividad del entrenamiento del maniquí.
Zip-Fit se evaluó en dos tareas centradas en el dominio, a asimilar, Autoformalización y Coexistentes de código Python.
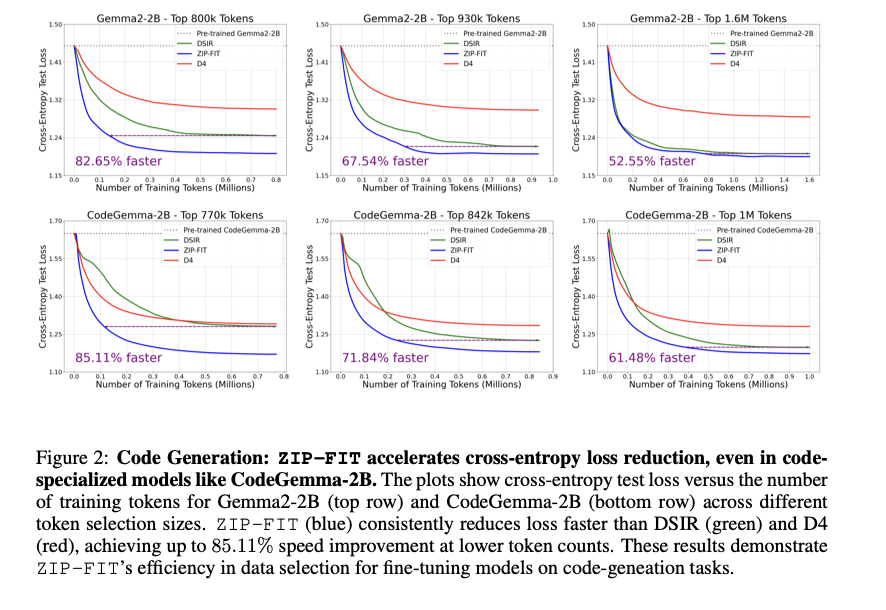
Antaño de profundizar más, sería prudente comprender qué es la autoformalización y por qué se eligió como métrica de evaluación. Es la tarea de traducir enunciados matemáticos en idioma natural a lenguajes de programación matemáticos formales. La autoformalización requiere experiencia en el dominio y una comprensión muy clara de las matemáticas y las sintaxis de programación, lo que la hace adecuada para probar el rendimiento del dominio de los LLM. Cuando se utilizó ZIP-FIT para ajustar conjuntos de datos en LLM como GPT 2 y Mistral, los autores descubrieron que las pérdidas disminuyeron rápida y significativamente al aumentar la vinculación con los datos de las tareas. Los modelos entrenados con datos seleccionados por ZIP-FIT logran su pérdida de entropía cruzada más devaluación hasta un 85,1% más rápido que las líneas de saco.
Para la tarea de autoformalización, superó a otros métodos de vinculación al ganar una convergencia hasta un 65,8% más rápida que DSIR, otro método de selección de datos. El tiempo de procesamiento todavía se redujo hasta en un 25%. De forma similar, en las tareas de gestación de código, los datos ZIP FIT ajustados CodeGemma2 y Gemma2 tuvieron un rendimiento significativamente mejor. Una idea importante que el equipo de investigación presentó en la investigación fue la supremacía de los conjuntos de datos más pequeños pero admisiblemente alineados con los dominios, que tuvieron un mejor rendimiento que los conjuntos de datos extensos pero menos alineados.
ZIP-FIT demostró que la selección de datos específicos puede mejorar drásticamente el rendimiento de tareas específicas en comparación con un enfoque de capacitación generalizado. ZIP-FIT presenta un enfoque de capacitación especializada en un dominio competente y rentable. Sin bloqueo, este método tenía algunas deficiencias, como la incapacidad de la compresión para capturar relaciones semánticas matizadas entre representaciones densas y una suscripción dependencia de datos textuales. Sería interesante ver si ZIP-FIT inicia una investigación más sólida en el ajuste de dominios y si sus deficiencias podrían superarse para incluir datos más caóticos y desestructurados.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este tesina. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Tendencia) LLMWare presenta Model Depot: una amplia colección de modelos de idioma pequeño (SLM) para PC Intel
Adeeba Alam Ansari actualmente está cursando su doble titulación en el Instituto Indio de Tecnología (IIT) Kharagpur, donde obtuvo una diploma en Ingeniería Industrial y una arte en Ingeniería Financiera. Con un gran interés en el enseñanza inevitable y la inteligencia químico, es una lectora ávida y una persona curiosa. Adeeba cree firmemente en el poder de la tecnología para empoderar a la sociedad y promover el bienestar a través de soluciones innovadoras impulsadas por la empatía y una profunda comprensión de los desafíos del mundo auténtico.