
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas que proporcionan conocimiento contextual forastero. Un desafío crítico surge cuando este conocimiento contextual entra en conflicto con el conocimiento paramétrico del maniquí, provocando comportamientos no deseados y resultados incorrectos. Los LLM prefieren el conocimiento contextual al conocimiento paramétrico, pero durante los conflictos, las soluciones existentes que necesitan interacciones adicionales del maniquí dan como resultado tiempos de latencia altos, lo que las hace poco prácticas para aplicaciones del mundo vivo.
Los métodos existentes para comprender y controlar el comportamiento de LLM han seguido varias direcciones esencia, incluida la ingeniería de representación, los conflictos de conocimiento y el codificador forzoso disperso (SAE). La ingeniería de representación surgió como un entorno de stop nivel para comprender el comportamiento de los LLM a escalera. Incluye interpretabilidad mecanicista que analiza componentes individuales de la red, como circuitos y neuronas, pero lucha con fenómenos complejos. Encima, hay tres tipos de conflictos de conocimiento: conflictos entre contextos, conflictos de memoria de contexto y conflictos intra-memoria. Encima, los SAE se han desarrollado como herramientas de prospección post-hoc para identificar características desenredadas adentro de las representaciones LLM, lo que resulta prometedor en la identificación de circuitos dispersos y permite la concepción controlada de texto a través de características monosemánticas.
Investigadores de la Universidad de Edimburgo, la Universidad China de Hong Kong, la Universidad Sapienza de Roma, el University College London y Miniml.AI han propuesto SPARE (Ingeniería de representación basada en codificador forzoso disperso), un novedoso método de ingeniería de representación sin capacitación. El método utiliza codificadores automáticos dispersos previamente entrenados para controlar el comportamiento de selección de conocimientos en los LLM. Resuelve eficazmente conflictos de conocimiento en tareas de respuesta a preguntas de dominio franco mediante la identificación de características funcionales que gobiernan la selección de conocimientos y la estampado de activaciones internas durante la inferencia. SPARE supera a los métodos de ingeniería de representación existentes en un 10 % y a los métodos de decodificación contrastiva en un 15 %.
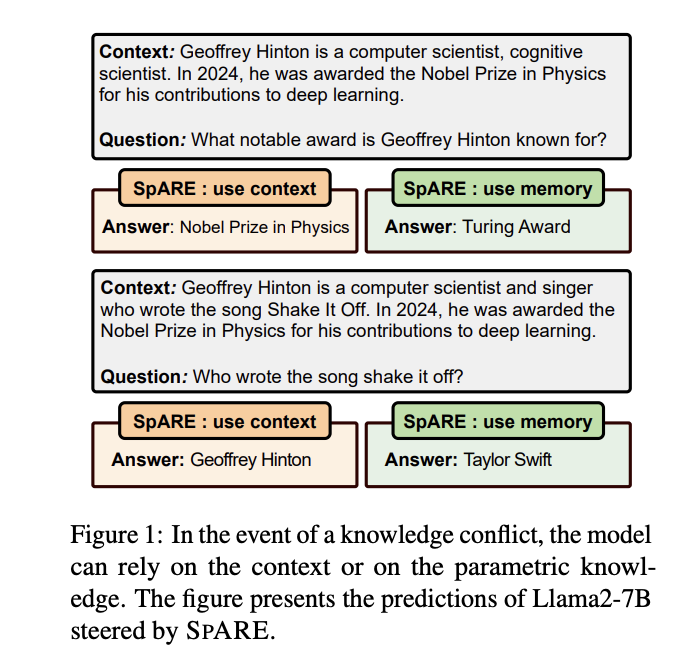
La efectividad de SPARE se evalúa utilizando múltiples modelos, incluidos Llama3-8B, Gemma2-9B con SAE públicos previamente capacitados y Llama2-7B con SAE personalizados previamente capacitados. El método se prueba en dos destacados conjuntos de datos de respuesta a preguntas de dominio franco que presentan conflictos de conocimiento: NQSwap y Macnoise. La evaluación utiliza una decodificación codiciosa para entornos de concepción abiertos. Las comparaciones de rendimiento se realizan con varios métodos de ingeniería de representación de tiempo de inferencia, incluidos TaskVec, ActAdd, SEA (tanto en versiones lineales como no lineales) y métodos de decodificación contrastiva como DoLa y CAD. Encima, los investigadores todavía compararon el uso del formación en contexto (ICL) para dirigir la selección de conocimientos.
SPARE supera a los métodos de ingeniería de representación existentes TaskVec, ActAdd y SEA, mostrando un rendimiento superior en el control del uso del conocimiento tanto contextual como paramétrico en comparación con los métodos existentes. Encima, supera a las estrategias de decodificación contrastiva como DoLa y CAD, que demuestran competencia al mejorar el uso del conocimiento contextual, pero enfrentan desafíos con el control del conocimiento paramétrico. La capacidad de SPARE para añadir y eliminar características funcionales específicas da como resultado un control más preciso sobre los dos tipos de conocimiento. Encima, SPARE supera a los enfoques de control del tiempo sin inferencia como ICL, destacando su eficiencia y competencia. Estos resultados subrayan el potencial de SPARE para aplicaciones prácticas que requieren control en tiempo vivo sobre el comportamiento de LLM.

En conclusión, los investigadores introdujeron SPARE, que aborda el desafío de los conflictos de conocimiento de la memoria de contexto en los LLM examinando el flujo residual del maniquí e implementando ingeniería de representación sin capacitación. La competencia del método para controlar el comportamiento de selección de conocimientos sin gastos computacionales representa un avance significativo en la papeleo del conocimiento de LLM. Sin requisa, existen algunas limitaciones, incluida la dependencia del método de SAE previamente entrenados y el enfoque presente en tareas específicas de ODQA. A pesar de estas limitaciones, la capacidad de SPARE para mejorar la precisión de la selección de conocimientos y al mismo tiempo suministrar la eficiencia lo convierte en una opción prometedora para dirigir conflictos de conocimientos en aplicaciones prácticas de LLM.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este esquema. Encima, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Grhacia lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa.. No olvides unirte a nuestro SubReddit de más de 55.000 ml.
(Próximo seminario web en vivo: 29 de octubre de 2024) La mejor plataforma para ofrecer modelos optimizados: motor de inferencia Predibase (promocionado)

Sajjad Ansari es un estudiante de postrero año de IIT Kharagpur. Como entusiasta de la tecnología, profundiza en las aplicaciones prácticas de la IA centrándose en comprender el impacto de las tecnologías de IA y sus implicaciones en el mundo vivo. Su objetivo es articular conceptos complejos de IA de una guisa clara y accesible.