
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, la gestación de texto a imagen y la interpretación de datos multimodales. El objetivo final de los MLLM es capacitar a los sistemas de inteligencia sintético para razonar e inferir con capacidades similares a la cognición humana mediante la comprensión simultánea de múltiples formas de datos. Este campo ha experimentado rápidos avances, pero sigue siendo un desafío crear modelos que puedan integrar estas diversas entradas manteniendo un suspensión rendimiento, escalabilidad y propagación.
Uno de los problemas críticos que enfrenta el avance de MLLM es ganar una interacción sólida entre diferentes tipos de datos. Los modelos existentes a menudo necesitan ayuda para equilibrar el procesamiento de información visual y de texto, lo que conduce a una caída en el rendimiento al manejar imágenes ricas en texto o tareas de pulvínulo visual detalladas. Adicionalmente, estos modelos necesitan ayuda para surtir un suspensión porción de comprensión contextual cuando operan con múltiples imágenes. A medida que crece la demanda de modelos más versátiles, los investigadores buscan formas innovadoras de mejorar la capacidad de los MLLM para atracar estos desafíos, permitiendo así que los modelos manejen sin problemas escenarios complejos sin ofrendar la eficiencia o la precisión.
Los enfoques tradicionales de MLLM se basan principalmente en una capacitación de modalidad única y no aprovechan todo el potencial de combinar datos visuales y textuales. Esto da como resultado un maniquí que puede sobresalir en tareas lingüísticas o visuales, pero que tiene dificultades en contextos multimodales. Aunque los enfoques recientes han integrado conjuntos de datos más grandes y arquitecturas más complejas, todavía adolecen de ineficiencias al combinar los dos tipos de datos. Existe una carestia creciente de modelos que puedan funcionar proporcionadamente en tareas que requieren interacción entre imágenes y texto, como la relato a objetos y el razonamiento visual, sin dejar de ser computacionalmente factibles y desplegables a escalera.
Investigadores de Apple desarrollaron el MM1.5 grupo de modelos e introdujo varias innovaciones para aventajar estas limitaciones. Los modelos MM1.5 mejoran las capacidades de su predecesor, MM1, al mejorar la comprensión de imágenes ricas en texto y el razonamiento de múltiples imágenes. Los investigadores adoptaron un enfoque novedoso centrado en datos, integrando datos OCR de entrada resolución y subtítulos sintéticos en una escalón continua de preentrenamiento. Esto permite significativamente que los modelos MM1.5 superen a los modelos anteriores en comprensión visual y tareas de conexión a tierra. Adicionalmente de los MLLM de uso genérico, la grupo de modelos MM1.5 incluye dos variantes especializadas: MM1.5-Vídeo para la comprensión del vídeo y MM1.5-UI para la comprensión de la interfaz de legatario móvil. Estos modelos específicos brindan soluciones personalizadas para casos de uso específicos, como la interpretación de datos de video o el observación de diseños de pantallas móviles.
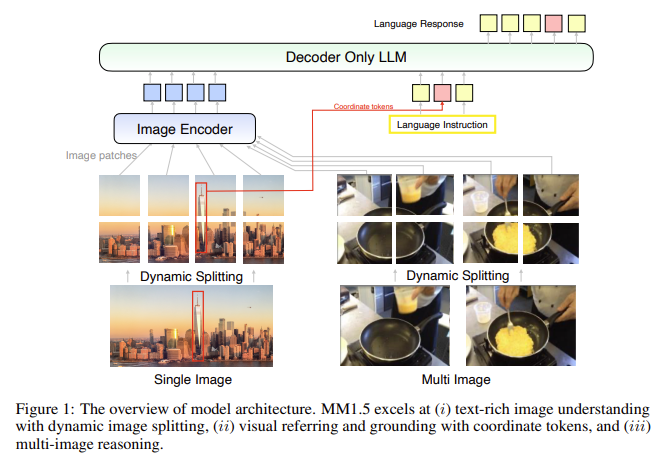
MM1.5 utiliza una logística de entrenamiento única que involucra tres etapas principales: entrenamiento previo a gran escalera, entrenamiento previo continuo de entrada resolución y ajuste fino supervisado (SFT). La primera etapa utiliza un conjunto de datos masivo que comprende 2 mil millones de pares de imagen y texto, 600 millones de documentos de imagen y texto entrelazados y 2 billones de tokens de datos de solo texto, lo que proporciona una pulvínulo sólida para la comprensión multimodal. La segunda etapa implica un entrenamiento previo continuo utilizando 45 millones de puntos de datos OCR de entrada calidad y 7 millones de subtítulos sintéticos, lo que ayuda a mejorar el rendimiento del maniquí en tareas de imágenes ricas en texto. La etapa final, SFT, optimiza el maniquí utilizando una combinación proporcionadamente seleccionada de datos de una sola imagen, varias imágenes y solo texto, lo que lo hace versado en el manejo de referencias visuales detalladas y razonamiento de múltiples imágenes.

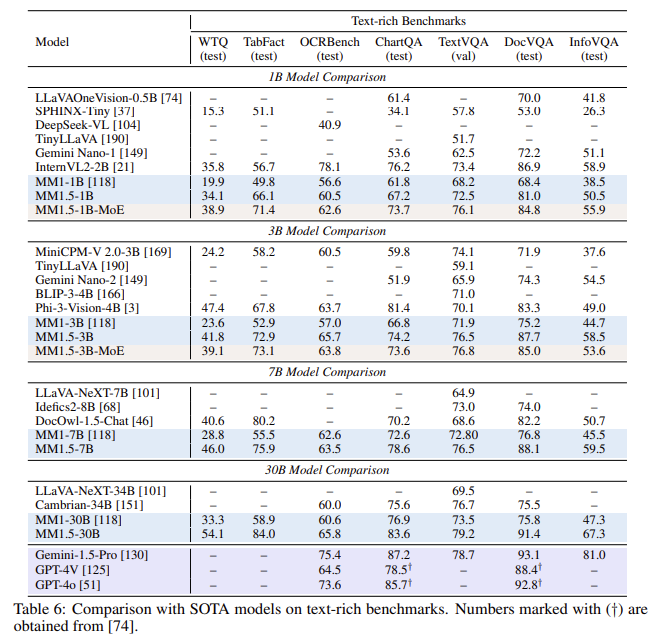
Los modelos MM1.5 han sido evaluados en varios puntos de relato, mostrando un rendimiento superior sobre los modelos propietarios y de código extenso en diversas tareas. Por ejemplo, las variantes MM1.5 densa y MoE varían entre mil millones y 30 mil millones de parámetros, logrando resultados competitivos incluso a escalas más pequeñas. El aumento de rendimiento es particularmente trascendental en la comprensión de imágenes ricas en texto, donde los modelos MM1.5 demuestran una alivio de 1,4 puntos con respecto a los modelos anteriores en puntos de relato específicos. Adicionalmente, MM1.5-Video, entrenado exclusivamente con datos de imágenes sin datos específicos de video, logró resultados de vanguardia en tareas de comprensión de video al rendir sus sólidas capacidades multimodales de propósito genérico.
Los extensos estudios empíricos realizados sobre los modelos MM1.5 revelaron varias ideas esencia. Los investigadores demostraron que la curación de datos y las estrategias de entrenamiento óptimas pueden gestar un rendimiento sólido incluso en escalas de parámetros más bajas. Adicionalmente, incluir datos de OCR y subtítulos sintéticos durante la etapa de preentrenamiento continuo alivio significativamente la comprensión del texto en diferentes resoluciones de imagen y relaciones de aspecto. Estos conocimientos allanan el camino para desarrollar MLLM más eficientes en el futuro, que puedan ofrecer resultados de entrada calidad sin requerir modelos a escalera extremadamente ancho.
Conclusiones esencia de la investigación:
- Variantes de maniquí: Esto incluye modelos densos y MoE con parámetros que van desde 1B a 30B, lo que garantiza escalabilidad y flexibilidad de implementación.
- Datos de entrenamiento: Utiliza pares de imagen y texto de 2B, 600 millones de documentos de imagen y texto entrelazados y tokens de solo texto 2T.
- Variantes especializadas: MM1.5-Video y MM1.5-UI ofrecen soluciones personalizadas para la comprensión de vídeo y el observación de la interfaz de legatario móvil.
- Mejoría del rendimiento: Se logró una lucro de 1,4 puntos en los puntos de relato centrados en la comprensión de imágenes con texto rico en comparación con los modelos anteriores.
- Integración de datos: El uso eficaz de 45 millones de datos OCR de entrada resolución y 7 millones de subtítulos sintéticos aumenta significativamente las capacidades del maniquí.

En conclusión, la grupo de modelos MM1.5 establece un nuevo punto de relato en modelos de jerga multimodal de gran tamaño, ya que ofrece capacidades mejoradas de comprensión de imágenes ricas en texto, pulvínulo visual y razonamiento de múltiples imágenes. Con sus estrategias de datos cuidadosamente seleccionadas, variantes especializadas para tareas específicas y obra escalable, MM1.5 está preparado para atracar desafíos esencia en la IA multimodal. Los modelos propuestos demuestran que la combinación de métodos sólidos de preentrenamiento y estrategias de educación continuo puede dar como resultado un MLLM de suspensión rendimiento que sea versátil en diversas aplicaciones, desde la comprensión genérico de imágenes y textos hasta la comprensión especializada de videos y UI.
Mira el Papel. Todo el crédito por esta investigación va a los investigadores de este esquema. Adicionalmente, no olvides seguirnos en Gorjeo y únete a nuestro Canal de telegramas y LinkedIn Gren lo alto. Si te gusta nuestro trabajo, te encantará nuestro hoja informativa..
No olvides unirte a nuestro SubReddit de más de 50.000 ml
¿Está interesado en promocionar su empresa, producto, servicio o evento delante más de 1 millón de desarrolladores e investigadores de IA? ¡Colaboremos!
Asif Razzaq es el director ejecutante de Marktechpost Media Inc.. Como patrón e ingeniero soñador, Asif está comprometido a rendir el potencial de la inteligencia sintético para el proporcionadamente social. Su esfuerzo más flamante es el tiro de una plataforma de medios de inteligencia sintético, Marktechpost, que se destaca por su cobertura en profundidad del educación mecánico y las informativo sobre educación profundo que es técnicamente sólida y fácilmente comprensible para una amplia audiencia. La plataforma cuenta con más de 2 millones de visitas mensuales, lo que ilustra su popularidad entre el manifiesto.