
Nos complace anunciar que Entrenamiento del maniquí de IA en cerámica Ahora es compatible con la largura de contexto completa de 131 000 tokens al ajustar la clan de modelos Meta Pasión 3.1. Con esta nueva capacidad, los clientes de Databricks pueden crear sistemas de recuperación, engendramiento aumentada (RAG) o uso de herramientas de anciano calidad mediante el uso de datos empresariales de gran largura de contexto para crear modelos especializados.
El tamaño del mensaje de entrada de un LLM está determinado por su largura del contexto. Nuestros clientes suelen estar limitados por longitudes de contexto cortas, especialmente en casos de uso como RAG y estudio de múltiples documentos. Los modelos Meta Pasión 3.1 tienen una largura de contexto larga de 131K tokens. A modo de comparación, El gran Gatsby es ~72.000 tokensLos modelos de Pasión 3.1 permiten razonar sobre un extenso corpus de datos, lo que reduce la menester de fragmentar y reclasificar en RAG o habilitar más descripciones de herramientas para los agentes.
El ajuste fino permite a los clientes utilizar sus propios datos empresariales para especializar los modelos existentes. Técnicas recientes como Ajuste fino aumentado de recuperación (RAFT) Combine el ajuste fino con RAG para enseñar al maniquí a ignorar la información irrelevante en el contexto, lo que prosperidad la calidad de la salida. Para el uso de herramientas, el ajuste fino puede especializar los modelos para que utilicen mejor las herramientas y API novedosas que son específicas de sus sistemas empresariales. En los dos casos, el ajuste fino en contextos largos permite que los modelos razonen sobre una gran cantidad de información de entrada.
La plataforma de inteligencia de datos de Databricks permite a nuestros clientes crear de forma segura sistemas de IA de reincorporación calidad utilizando sus propios datos. Para certificar que nuestros clientes puedan rendir los modelos de IA generativa de última engendramiento, es importante aposentar funciones como el ajuste valioso de Pasión 3.1 en contextos de gran largura. En esta publicación del blog, explicamos algunas de nuestras optimizaciones recientes que hacen de Mosaic AI Model Training un servicio de primera clase para crear y ajustar de forma segura los modelos GenAI en datos empresariales.
Ajuste fino de la largura del contexto abundante
El entrenamiento con secuencias de gran largura plantea un desafío principalmente adecuado a sus mayores requisitos de memoria. Durante el entrenamiento con secuencias de gran largura, las GPU necesitan acumular resultados intermedios (es aseverar, activaciones) para calcular gradientes para el proceso de optimización. A medida que aumenta la largura de la secuencia de los ejemplos de entrenamiento, además aumenta la memoria necesaria para acumular estas activaciones, lo que puede exceder los límites de memoria de la GPU.
Resolvemos esto empleando paralelismo de secuenciasdonde dividimos una sola secuencia en varias GPU. Este enfoque distribuye la memoria de activación de una secuencia en varias GPU, lo que reduce el uso de memoria de la GPU para trabajos de ajuste fino y prosperidad la eficiencia del entrenamiento. En el ejemplo que se muestra en la Figura 1, dos GPU procesan cada una la porción de la misma secuencia. Usamos nuestro código hendido Conjuntos de datos de transmisión función de replicación para compartir muestras entre grupos de GPU.
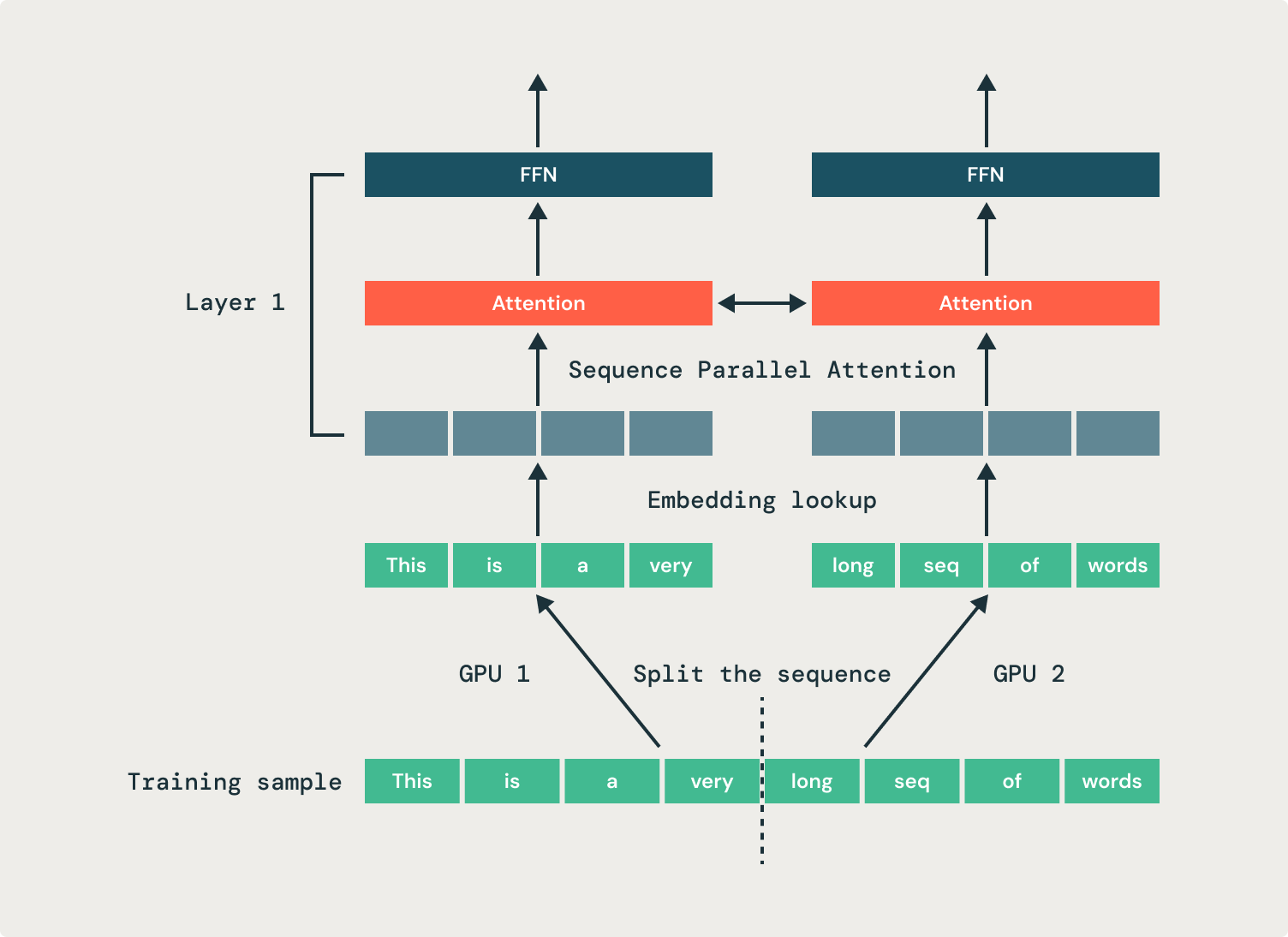
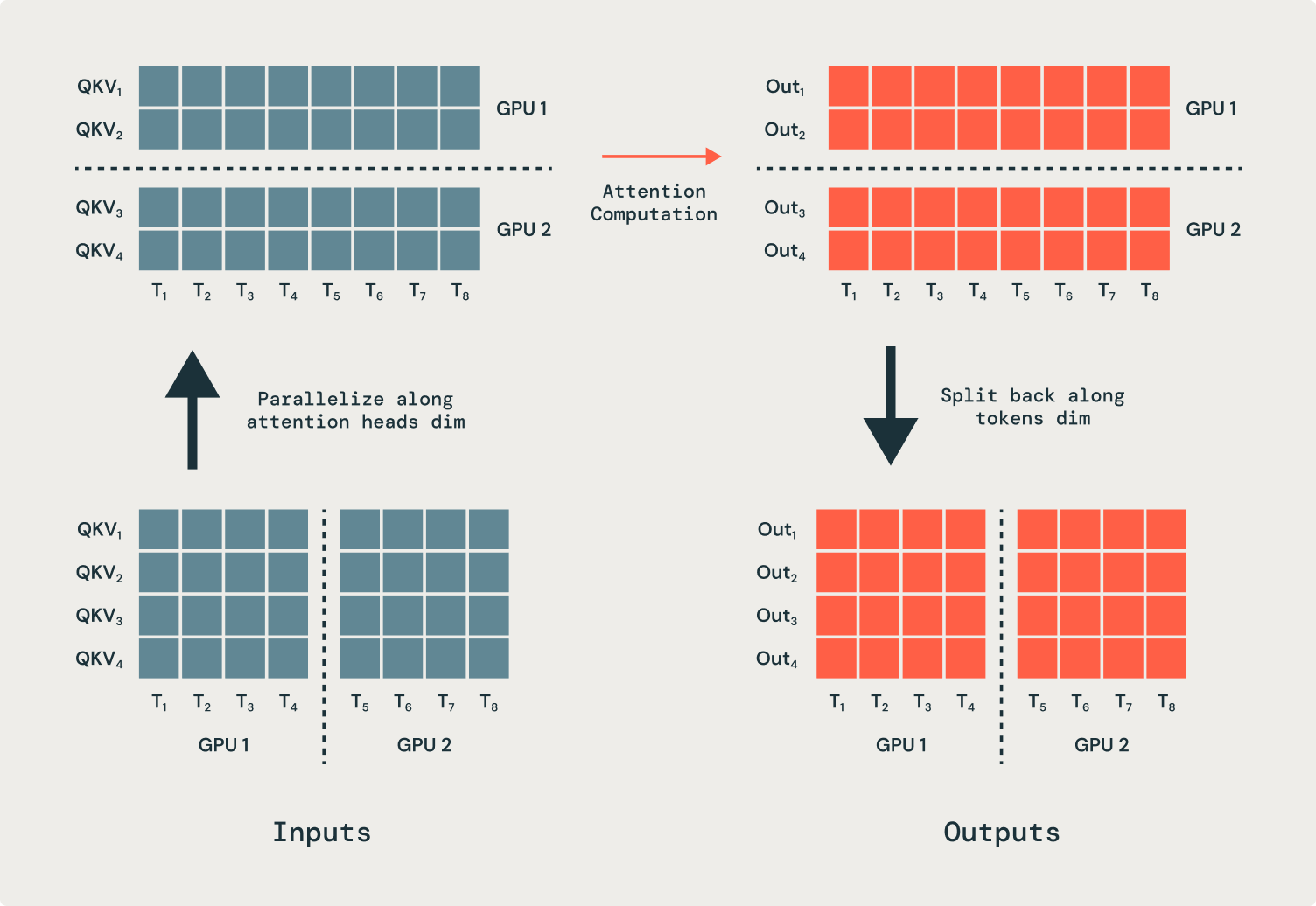
Todas las operaciones en un transformador son independientes de la dimensión de la secuencia, excepto, fundamentalmente, la atención. Como resultado, la operación de atención debe modificarse para introducir y extraer secuencias parciales. Paralelizamos los cabezales de atención en muchas GPU, lo que requiere operaciones de comunicación (de todos a todos) para mover los tokens a las GPU correctas para su procesamiento. Antaño de la operación de atención, cada GPU tiene parte de cada secuencia, pero cada cabezal de atención debe negociar en una secuencia completa. En el ejemplo que se muestra en la Figura 2, la primera GPU recibe todas las entradas solo para el primer cabezal de atención, y la segunda GPU recibe todas las entradas para el segundo cabezal de atención. Luego de la operación de atención, las horizontes se envían de envés a sus GPU originales.
Gracias al paralelismo de secuencias, podemos ofrecer un ajuste fino de Pasión 3.1 en todo el contexto, lo que permite que los modelos personalizados comprendan y razonen en un contexto amplio.
Optimización del rendimiento del ajuste fino
Las optimizaciones personalizadas, como el paralelismo de secuencias para el ajuste fino, requieren que tengamos un control detallado sobre la implementación del maniquí subyacente. Dicha personalización no es posible nada más con el código de modelado Pasión 3.1 existente en HuggingFace. Sin confiscación, para favorecer la entrega y la compatibilidad externa, el maniquí final cabal debe ser un punto de control del maniquí HuggingFace de Pasión 3.1. Por lo tanto, nuestra opción de ajuste fino debe ser mucho optimizable para el entrenamiento, pero además capaz de producir un maniquí de salida interoperable.
Para lograrlo, convertimos los modelos HuggingFace Pasión 3.1 en una representación interna equivalente de Pasión antaño del entrenamiento. Hemos optimizado ampliamente esta representación interna para alcanzar una anciano eficiencia en el entrenamiento, con mejoras como núcleos eficientes, puntos de control de activación selectiva, uso eficaz de la memoria y enmascaramiento de la atención de la identificación de secuencia. Como resultado, nuestra representación interna de Pasión permite el paralelismo de secuencias, al mismo tiempo que produce un rendimiento de entrenamiento hasta un 40 % anciano y requiere un consumo de memoria un 40 % último. Estas mejoras en la utilización de medios se traducen en mejores modelos para nuestros clientes, ya que la capacidad de iterar rápidamente ayuda a alcanzar una mejor calidad del maniquí.
Cuando finaliza el entrenamiento, convertimos el maniquí de la representación interna nuevamente al formato HuggingFace, lo que garantiza que el artefacto guardado esté avispado de inmediato para servir a través de nuestro Rendimiento aprovisionado ofrecimiento. La figura 3 a continuación muestra todo este proceso.

Próximos pasos
Comience a ajustar Pasión 3.1 hoy mismo a través de la interfaz de heredero o mediante programación en Python. Con Entrenamiento del maniquí de IA en cerámicaPuede personalizar de modo valioso modelos de código hendido y de reincorporación calidad para las deposición de su negocio y originar inteligencia de datos. Lea nuestra documentación (AWS, Azur) y visite nuestra página de precios página para comenzar a ajustar los LLM en Databricks.