
Los desarrolladores de IA y ML suelen trabajar con conjuntos de datos locales mientras preprocesan los datos. Las funciones de ingeniería y la creación de prototipos hacen que esto sea realizable sin la sobrecarga de un servidor completo. La comparación más popular es entre SQLite, una pulvínulo de datos sin servidor rejonazo en 2000 y ampliamente utilizada para transacciones ligeras, y DuckDB, presentada en 2019 como el SQLite del estudio, centrado en consultas analíticas rápidas durante el proceso. Si correctamente los dos están integrados, sus objetivos difieren. En este artículo, compararemos DuckDB y SQLite para ayudarlo a designar la útil adecuada para cada etapa de su flujo de trabajo de IA.
¿Qué es SQLite?
SQLite es un motor de pulvínulo de datos autónomo sin servidor. Crea un capullo directamente a partir de un archivo de disco. No tiene configuración cero y ocupa poco espacio. Toda la pulvínulo de datos está almacenada en un archivo que es.sqlite y todas las tablas e índices están contenidos en ese archivo. El motor en sí es una biblioteca C integrada en su aplicación.
SQLite es un ÁCIDO-base de datos compatible, aunque es simple. Esto lo hace confiable en las transacciones y la integridad de los datos.
Las características secreto incluyen:
- Almacenamiento orientado a filas: Los datos se almacenan fila por fila. Esto hace que renovar o recuperar una fila individual sea conveniente valioso.
- Cojín de datos de un solo archivo: Toda la pulvínulo de datos está en un solo archivo. Esto permite copiarlo o transferirlo fácilmente.
- Sin proceso de servidor: La leída y escritura directa en el archivo de pulvínulo de datos se realizan en su aplicación. No se necesita ningún servidor separado.
- Amplio soporte de SQL: Se fundamento en la mayoría de SQL-2 y admite fundamentos como uniones, funciones de ventana e índices.
SQLite se selecciona con frecuencia en aplicaciones móviles y Internet de las cosasasí como pequeñas aplicaciones web. Es radiante cuando necesita una posibilidad sencilla para juntar datos estructurados localmente y cuando necesita numerosas operaciones breves de leída y escritura.
¿Qué es DuckDB?
DuckDB es una pulvínulo de datos en proceso de estudio de datos. Lleva la solidez de la pulvínulo de datos SQL a las aplicaciones integradas. Ejecutará consultas analíticas complicadas de forma eficaz sin un servidor. Este enfoque analítico es frecuentemente la pulvínulo de comparación entre DuckDB y SQLite.
Las características importantes de PatoDB son:
- Formato de almacenamiento en columnas: DuckDB almacena columnas de datos. En este formato, es capaz de escanear y fusionar enormes conjuntos de datos a un ritmo mucho maduro. Solo lee las columnas que requiere.
- Ejecución de consultas vectorizadas: DuckDB está diseñado para realizar cálculos en fragmentos o vectores, en sitio de en una sola fila. Este método implica la aplicación de las capacidades actuales de la CPU para calcular a una velocidad maduro.
- Consulta directa de archivos: DuckDB puede consultar archivos Parquet, CSV y Arrow directamente. No es necesario incluirlos en la pulvínulo de datos.
- Integración profunda de la ciencia de datos: Es compatible con Pandas, NumPy y R. A DataFrame se le pueden hacer preguntas como tablas de bases de datos.
DuckDB se puede utilizar para procesar rápidamente estudio de datos interactivos en portátiles Jupyter y acelerar los flujos de trabajo de Pandas. Requiere capacidades de almacenamiento de datos en un paquete pequeño y almacén.
Diferencias secreto
Primero, aquí hay una tabla extracto que compara SQLite y DuckDB en aspectos importantes.
| Aspecto | SQLite (desde 2000) | DuckDB (desde 2019) |
| Propósito principal | Cojín de datos OLTP integrada (transacciones) | Cojín de datos OLAP integrada (estudio) |
| Maniquí de almacenamiento | Basado en filas (almacena filas enteras juntas) | Columnar (almacena columnas juntas) |
| Ejecución de consultas | Procesamiento iterativo fila a fila | Procesamiento por lotes vectorizado |
| Proceder | Excelente para transacciones pequeñas y frecuentes | Excelente para consultas analíticas sobre grandes datos |
| Tamaño de datos | Optimizado para conjuntos de datos pequeños y medianos | Maneja conjuntos de datos grandes y sin memoria |
| concurrencia | Leyente múltiple, escritor único (mediante candados) | Leyente múltiple, escritor único; ejecución de consultas paralelas |
| Uso de la memoria | Huella de memoria mínima de forma predeterminada | Aprovecha la memoria para aumentar la velocidad; puede usar más RAM |
| Funciones SQL | SQL primordial robusto con algunas limitaciones | Amplio soporte de SQL para estudio avanzados |
| Índices | A menudo se necesitan índices de árbol B | Se fundamento en escaneos de columnas; la indexación es menos popular |
| Integración | Compatible con casi todos los idiomas | Integración nativa con Pandas, Arrow, NumPy |
| Formatos de archivo | Archivo propietario; puede importar/exportar archivos CSV | Puede consultar directamente Parquet, CSV, JSON, Arrow |
| Actas | Totalmente compatible con ACID | ACID en el interior de un solo proceso |
| Paralelismo | Ejecución de consultas de un solo subproceso | Ejecución multiproceso para una sola consulta |
| Casos de uso típicos | Aplicaciones móviles, dispositivos IoT, almacenamiento de aplicaciones locales | Cuadernos de ciencia de datos, experimentos locales de ML |
| Deshonestidad | Dominio sabido | Deshonestidad MIT (código despejado) |
Esta tabla revela que SQLite se centra en la confiabilidad y las operaciones de las transacciones. DuckDB está optimizado para aposentar consultas analíticas rápidas sobre big data. Ahora vamos a comentar cada uno de ellos.
Actos en Python: de la teoría a la ejercicio
Veremos cómo utilizar ambas bases de datos en Pitón. Es un entorno de incremento de IA de código despejado.
Usando SQLite
Esta es una representación sencilla de SQLite Python. Desarrollaremos una tabla, ingresaremos datos y ejecutaremos una consulta.
import sqlite3
# Connect to a SQLite database file
conn = sqlite3.connect("example.db")
cur = conn.cursor()
# Create a table
cur.execute(
"""
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT,
age INTEGER
);
"""
)
# Insert records into the table
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Alice", 30)
)
cur.execute(
"INSERT INTO users (name, age) VALUES (?, ?);",
("Bob", 35)
)
conn.commit()
# Query the table
for row in cur.execute(
"SELECT name, age FROM users WHERE age > 30;"
):
print(row)
# Expected output: ('Bob', 35)
conn.close()Producción:
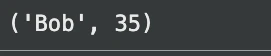
La pulvínulo de datos en este caso se mantiene en el ejemplo.db archivo. Creamos una tabla, le agregamos dos filas y ejecutamos una consulta simple. SQLite te permite cargar datos en las tablas y luego realizar consultas. En caso de que tengas un archivo CSV, primero debes importar la información.
Usando DuckDB
Aún así, toca repetir esta opción con DuckDB. Todavía llamaremos su atención sobre las ventajas de la ciencia de datos.
import duckdb
import pandas as pd
# Connect to an in-memory DuckDB database
conn = duckdb.connect()
# Create a table and insert data
conn.execute(
"""
CREATE TABLE users (
id INTEGER,
name VARCHAR,
age INTEGER
);
"""
)
conn.execute(
"INSERT INTO users VALUES (1, 'Alice', 30), (2, 'Bob', 35);"
)
# Run a query on the table
result = conn.execute(
"SELECT name, age FROM users WHERE age > 30;"
).fetchall()
print(result) # Expected output: (('Bob', 35))Producción:
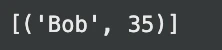
El uso simple se parece al uso primordial. Sin requisa, DuckDB asimismo puede consultar datos externos.
Generemos un conjunto de datos azaroso para consultar:
import pandas as pd
import numpy as np
# Generate random sales data
np.random.seed(42)
num_entries = 1000
data = {
"category": np.random.choice(
("Electronics", "Clothing", "Home Goods", "Books"),
num_entries
),
"price": np.round(
np.random.uniform(10, 500, num_entries),
2
),
"region": np.random.choice(
("EUROPE", "AMERICA", "ASIA"),
num_entries
),
"sales_date": (
pd.to_datetime("2023-01-01")
+ pd.to_timedelta(
np.random.randint(0, 365, num_entries),
unit="D"
)
)
}
sales_df = pd.DataFrame(data)
# Save to sales_data.csv
sales_df.to_csv("sales_data.csv", index=False)
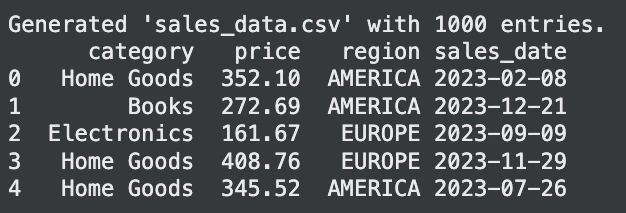
print("Generated 'sales_data.csv' with 1000 entries.")
print(sales_df.head())Producción:
Ahora, consultemos esta tabla:
# Assume 'sales_data.csv' exists
# Example 1: Querying a CSV file directly
avg_prices = conn.execute(
"""
SELECT
category,
AVG(price) AS avg_price
FROM 'sales_data.csv'
WHERE region = 'EUROPE'
GROUP BY category;
"""
).fetchdf() # Returns a Pandas DataFrame
print(avg_prices.head())
# Example 2: Querying a Pandas DataFrame directly
df = pd.DataFrame({
"id": range(1000),
"value": range(1000)
})
result = conn.execute(
"SELECT COUNT(*) FROM df WHERE value % 2 = 0;"
).fetchone()
print(result) # Expected output: (500,)Producción:
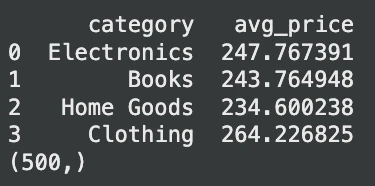
En este caso, DuckDB lee el archivo CSV sobre la marcha. No se requiere ningún paso importante. Todavía es capaz de consultar un pandas Entorno de datos. Esta flexibilidad elimina gran parte del código de carga de datos y simplifica los procesos de IA.
Edificación: por qué se desempeñan de modo tan diferente
Las diferencias en el rendimiento de SQLite y DuckDB tienen que ver con sus motores de consulta y almacenamiento.
- Maniquí de almacenamiento: SQLite se fundamento en filas. Agrupa todos los datos de una fila en él. Esto es muy bueno para renovar un solo registro. Sin requisa, no es rápido con el estudio. Suponiendo que solo necesita una sola columna, SQLite aún tendrá que ojear todos los datos de cada fila. DuckDB está orientado a columnas. Pone todos los títulos de una columna en una sola columna. Esto es ideal para estudio. Una consulta como
SELECT AVG(age)solo lee el existencia columna que es mucho más rápida. - Ejecución de consultas: SQLite una consulta por fila. Esto ahorra memoria cuando se negociación de consultas pequeñas. DuckDB se fundamento en una ejecución vectorizada. Funciona con datos de grandes lotes. Esta técnica utiliza CPU actuales para realizar aceleraciones significativas en escaneos y uniones grandes. Todavía es capaz de ejecutar numerosos subprocesos para ejecutar una única consulta a la vez.
- Comportamiento de la memoria y en el disco: SQLite está diseñado para utilizar una memoria mínima. Lee desde el disco según sea necesario. DuckDB utiliza la memoria para mejorar la velocidad. Puede ejecutar datos más grandes que la RAM acondicionado en ejecución fuera del núcleo. Esto implica que DuckDB puede consumir RAM adicional, pero es mucho más rápido en una tarea analítica. Se ha demostrado que en DuckDB, las consultas de agregación son entre 10 y 100 veces más rápidas que en SQLite.
El veredicto: cuándo usar DuckDB frente a SQLite
Esta es una buena recorrido a seguir en sus proyectos de inteligencia fabricado y estudios instintivo.
| Aspecto | Utilice SQLite cuando | Utilice DuckDB cuando |
|---|---|---|
| Propósito principal | Necesita una pulvínulo de datos transaccional liviana | Necesita estudio locales rápidos |
| Tamaño de datos | Grosor de datos bajo, hasta unos pocos cientos de MB | Conjuntos de datos medianos a grandes |
| Tipo de carga de trabajo | Inserciones, actualizaciones y búsquedas simples | Agregaciones, uniones y escaneos de tablas grandes |
| Deposición de transacción | Pequeñas actualizaciones frecuentes con integridad transaccional | Consultas analíticas con mucha leída |
| Manejo de archivos | Datos almacenados en el interior de la pulvínulo de datos. | Consultar archivos CSV o Parquet directamente |
| Enfoque en el desempeño | Huella mínima y simplicidad | Rendimiento analítico de entrada velocidad |
| Integración | Aplicaciones móviles, sistemas integrados, IoT | Acelerar el estudio basado en Pandas |
| Ejecución paralela | No es una prioridad | Utiliza múltiples núcleos de CPU |
| Caso de uso representativo | Estado de la aplicación y almacenamiento voluble. | Exploración y estudio de datos locales |
Conclusión
Tanto SQLite como DuckDB son sólidas bases de datos integradas. SQLite es una muy buena útil de transacciones sencilla y de almacenamiento de datos liviana. Sin requisa, DuckDB puede acelerar significativamente el procesamiento de datos y la creación de prototipos por parte de los desarrolladores de IA que operan con big data. Esto se debe a que cuando sea consciente de sus diferencias, sabrá cuál es la útil adecuada para utilizar en diferentes tareas. En el caso de procesos contemporáneos de estudio de datos y estudios instintivo, DuckDB puede ahorrarle mucho tiempo con un beneficio de rendimiento considerable.
Preguntas frecuentes
R. No, son para otros usos. DuckDB se utiliza para lograr a estudio rápidos (OLAP), mientras que SQLite se utiliza para realizar transacciones confiables. Selecciona según tu carga de trabajo.
R. SQLite suele ser más adecuado para aplicaciones web que tienen una gran cantidad de lecturas y escrituras pequeñas y comunicadas porque tiene un maniquí transaccional sólido y un modo WAL.
R. Sí, con la mayoría de los trabajos a gran escalera, como agrupaciones y uniones, DuckDB puede ser mucho más rápido que Pandas correcto a su motor vectorizado paralelo.
Harsh Mishra es un ingeniero de IA/ML que pasa más tiempo hablando con modelos de jerigonza grandes que con humanos reales. Apasionado por GenAI, PNL y hacer que las máquinas sean más inteligentes (para que no lo reemplacen todavía). Cuando no optimiza modelos, probablemente esté optimizando su consumo de café. 🚀☕
Inicie sesión para continuar leyendo y disfrutar de contenido seleccionado por expertos.