
Las uniones espaciales de Databricks ahora son 17 veces más rápidas y listas para usar
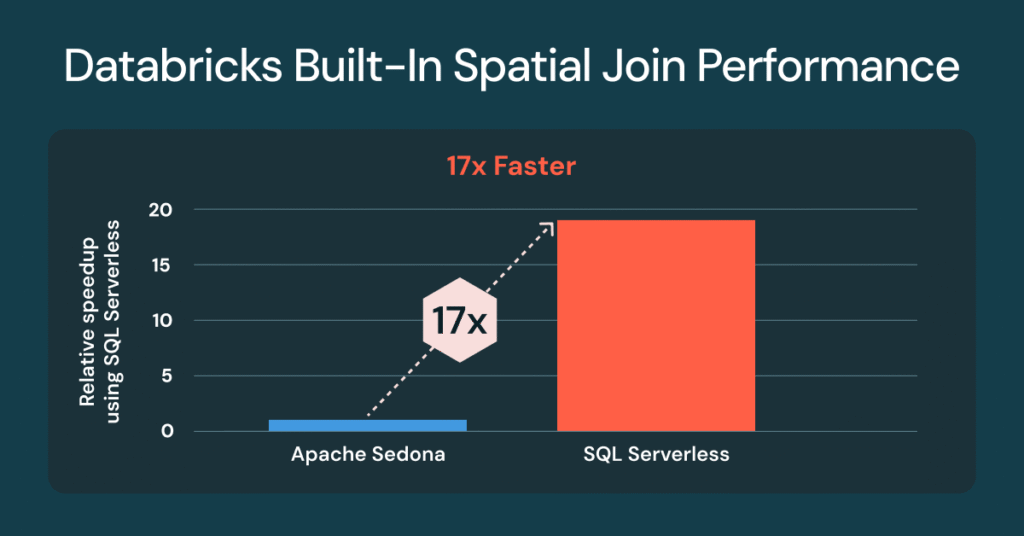
El procesamiento y examen de datos espaciales es fundamental para las cargas de trabajo geoespaciales en Databricks. Muchos equipos dependen de bibliotecas externas o extensiones de Spark como Apache Sedona, Geopandas, el plan Mosaic de Databricks Lab, para manejar estas cargas de trabajo. Si adecuadamente los clientes han tenido éxito, estos enfoques añaden gastos operativos […]
Logre un rendimiento de consultas del charcal de datos 2 veces más rápido con Apache Iceberg en Amazon Redshift

Con la creciente admisión de formatos de mesa abierta como Iceberg apache, Desplazamiento al rojo del Amazonas continúa avanzando en sus capacidades para lagos de datos de formato descubierto. En 2025, Amazon Redshift realizó varias optimizaciones de rendimiento que duplicaron el rendimiento de las consultas para las cargas de trabajo de Iceberg en Amazon Redshift […]
Ejecute trabajos de escritura de Apache Spark y Apache Iceberg 2 veces más rápido con Amazon EMR

Tiempo de ejecución de Amazon EMR para Apache Spark ofrece un entorno de ejecución de stop rendimiento al tiempo que mantiene la compatibilidad de API con código amplio chispa apache y Iceberg apache formato de tabla. Amazon EMR en EC2, Amazon EMR sin servidor, Amazon EMR en Amazon EKS, Amazon EMR en puestos avanzados de […]
Ejecute Apache Spark e Iceberg 4,5 veces más rápido que Spark de código descubierto con Amazon EMR

Esta publicación muestra cómo Amazon EMR 7.12 puede hacer que sus cargas de trabajo de Apache Spark e Iceberg tengan un rendimiento hasta 4,5 veces más rápido. El Tiempo de ejecución de Amazon EMR para Apache Spark proporciona un entorno de ejecución de detención rendimiento con compatibilidad API total con código descubierto chispa apache y […]
Amazon Kinesis Data Streams ahora admite tamaños de registros 10 veces mayores: simplificación del procesamiento de datos en tiempo actual

Hoy, AWS anunció que Flujos de datos de Amazon Kinesis ahora admite tamaños de registro de hasta 10 MiB, un aumento diez veces decano que el meta susodicho. Con este impulso, ahora puede difundir cargas enseres de datos más grandes de forma intermitente en sus flujos de datos mientras continúa usando las API de Kinesis […]
Acelerar la IA y las bases de datos con almacenamiento de contenedores de Azure, ahora 7 veces más rápido y de código campechano

La próxima divulgación principal del almacenamiento de contenedores de Azure ofrece IOP hasta 7 veces más parada y 4 veces menos latencia en comparación con las versiones anteriores. Más empresas que nunca antiguamente eligen ejecutar cargas de trabajo con estado, como bases de datos relacionales, inferencias de IA y colas de correo, en Kubernetes. Para […]
Express Brokers para Amazon MSK: escalado de kafka con carga turbo con un rendimiento hasta 20 veces más rápido

La trámite y el escalera de los flujos de datos de modo válido es una piedra angular de éxito para muchas organizaciones. Apache Kafka ha surgido como una plataforma líder para la transmisión de datos en tiempo actual, ofreciendo una escalabilidad y confiabilidad inigualables. Sin incautación, configurar y esquilar los grupos de Kafka puede ser […]
Cómo DeNA Co., Ltd. aceleró las pruebas de calidad de datos anónimos hasta 100 veces más rápido utilizando Amazon Redshift Serverless y dbt

Este blog fue coautor de DeNA Co., Ltd. y Amazon Web Services Japón. DeNA Co., Ltd. (DeNA) participa en una variedad de negocios, desde juegos y comunidades en vivo hasta deportes y la comunidad y atención médica y de sanidad, bajo nuestra delegación de deleitar a las personas más allá de sus sueños más locos. […]
El tiempo de ejecución de Amazon EMR 7.5 para Apache Spark e Iceberg puede ejecutar cargas de trabajo de Spark 3,6 veces más rápido que Spark 3.5.3 y Iceberg 1.6.1.

El Tiempo de ejecución de Amazon EMR para Apache Spark ofrece un entorno de ejecución de parada rendimiento y al mismo tiempo mantiene una compatibilidad API del 100 % con el formato de tabla de código descubierto Apache Spark y Apache Iceberg. Amazon EMR en EC2, Amazon EMR sin servidor, Amazon EMR en Amazon EKS, […]