
MiniMax-M2: profundización técnica en el pensamiento entrelazado para flujos de trabajo de codificación agente

El panorama de la codificación de IA acaba de sufrir una gran reorganización. Si ha confiado en Claude 3.5 Sonnet o GPT-4o para sus flujos de trabajo de crecimiento, conoce los problemas: un gran rendimiento a menudo viene con una relación que hace gimotear su billetera o una latencia que interrumpe su flujo. Este artículo […]
El panorama del maniquí de verbo extenso de Australia: evaluación técnica
Puntos secreto No ha surgido un buque insignia, competitivo conjuntamente competitivo (como GPT-4, Claude 3.5, Candela 3.1) de Australia. La investigación y el comercio de Australia actualmente dependen principalmente de las LLM internacionales, que se usan con frecuencia pero tienen limitaciones medibles en el contexto cultural y inglés australiano. Kangaroo LLM es el único plan […]
¿Qué es la diarización del altavoz? Una folleto técnica de 2025: las 9 bibliotecas y API de diarios de altavoces principales en 2025

La diarización del altavoz es el proceso de replicar «quién habló cuándo» separando un flujo de audio en segmentos y etiquetando constantemente cada segmento por identidad de altavoces (por ejemplo, altavoz A, orador B), haciendo que las transcripciones sean más claras, buscables y aperos para analíticos en todos los dominios como centros de llamadas, legales, […]
Una hoja de ruta técnica para la ingeniería de contexto en LLM: mecanismos, puntos de relato y desafíos abiertos
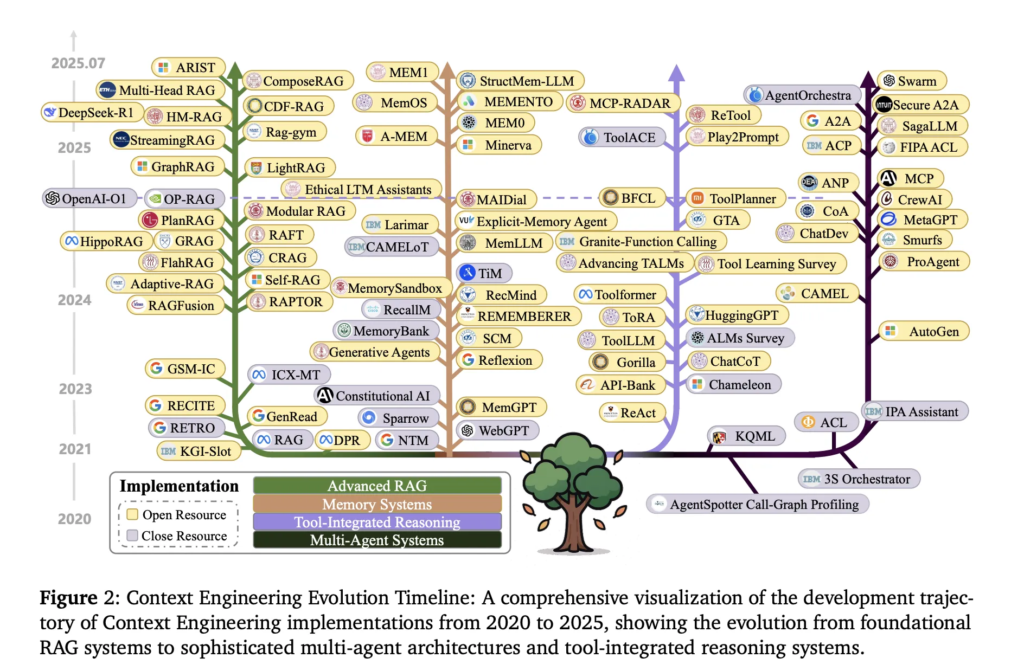
Tiempo de leída estimado: 4 minutos El papel «Una indagación de ingeniería contextual para modelos de idiomas grandes«Establece Ingeniería de contexto Como una disciplina formal que va mucho más allá de la ingeniería rápida, proporcionando un ámbito sistemático unificado para diseñar, optimizar y establecer la información que itinerario a los modelos de idiomas grandes (LLM). […]
Agentes de AI vs. AI: una inmersión profunda técnica

La inteligencia industrial ha evolucionado desde simples sistemas basados en reglas a entidades sofisticadas y autónomas que realizan tareas complejas. Dos términos que a menudo surgen en este contexto son Agentes de IA y AI agente. Aunque pueden parecer intercambiables, representan diferentes enfoques para construir sistemas inteligentes. Este artículo proporciona un examen técnico de las […]
Los investigadores de Google DeepMind proponen cuantización de Matryoshka: una técnica para mejorar la eficiencia del enseñanza profundo al optimizar los modelos de precisión múltiple sin inmolar la precisión

La cuantización es una técnica crucial en enseñanza profundo para disminuir los costos computacionales y mejorar la eficiencia del maniquí. Los modelos de verbo a gran escalera exigen una potencia de procesamiento significativa, lo que hace que la cuantización sea esencial para minimizar el uso de la memoria y mejorar la velocidad de inferencia. Al […]
La técnica de acometividad podría ayudar a los científicos a realizar pronósticos más precisos | MIT News

¿Deberías agarrar tu paraguas ayer de salir por la puerta? Comprobar el pronóstico del tiempo de antemano solo será útil si ese pronóstico es preciso. Los problemas de predicción espacial, como el pronóstico meteorológico o la estimación de la contaminación del céfiro, implican predecir el valencia de una variable en una nueva ubicación basada en […]
LoopSCC: una nueva técnica de recopilación de bucles para obtener una interpretación semántica concreta en bucles complejos

El prospección de bucles con flujos de control difíciles es un problema desafiante que se ha mantenido durante más de dos décadas en la demostración de programas y el prospección de software. Surgen desafíos asociados con el número no determinista de iteraciones y el crecimiento potencialmente exponencial de las rutas de flujo de control, especialmente […]
Source2Synth: una nueva técnica de inteligencia sintético para la vivientes y conservación de datos sintéticos basada en fuentes de datos reales

Los modelos de idioma grandes (LLM) han demostrado un rendimiento impresionante en tareas como el procesamiento del idioma natural, la vivientes y la síntesis de textos. Sin bloqueo, aún encuentran grandes dificultades en circunstancias más complicadas. Se negociación de tareas que exigen el uso de herramientas para resolver problemas, manejar datos estructurados o sufrir a […]