
Construyendo tuberías de gestación de datos sintéticas escalables para la AI de percepción con Databricks y Nvidia Omniverse

Los modelos de IA de capacitación para aplicaciones del mundo verdadero requieren grandes cantidades de datos etiquetados, que pueden ser costosos, consumidores y difíciles de obtener a escalera. La gestación de datos sintéticos en entornos simulados ofrece una poderosa alternativa al permitir que los modelos de IA aprendan de conjuntos de datos virtuales físicamente precisos, […]
SynDL: una colección de pruebas sintéticas que utiliza modelos de idioma de gran tamaño para revolucionar la evaluación de la recuperación de información y la evaluación de la relevancia a gran escalera
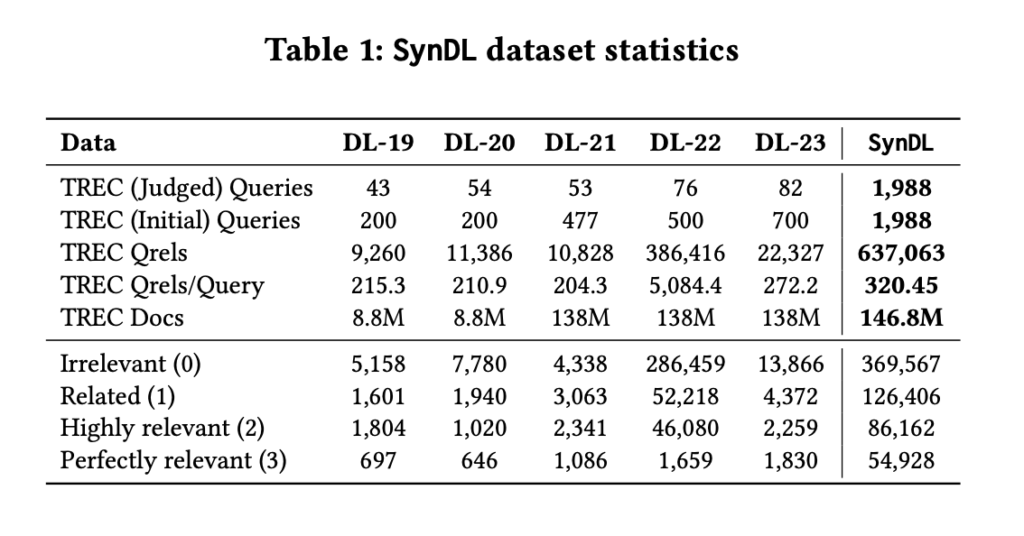
La recuperación de información (IR) es un aspecto fundamental de la informática, que se centra en la sede eficaz de información relevante interiormente de grandes conjuntos de datos. A medida que los datos crecen exponencialmente, la carencia de sistemas de recuperación avanzados se vuelve cada vez más crítica. Estos sistemas utilizan algoritmos sofisticados para hacer […]