
Este artículo de IA presenta DyCoke: compresión dinámica de tokens para modelos de verbo egregio de video eficientes y de parada rendimiento

Los modelos de verbo egregio de vídeo (VLLM) han surgido como herramientas transformadoras para analizar el contenido de vídeo. Estos modelos destacan en el razonamiento multimodal, integrando datos visuales y textuales para interpretar y replicar a escenarios de vídeo complejos. Sus aplicaciones van desde preguntas y respuestas sobre vídeos hasta resúmenes y descripciones de vídeos. […]
Dispersión de SmolTalk: la fórmula del conjunto de datos detrás del mejor rendimiento de su clase de SmolLM2

Los avances recientes en el procesamiento del habla natural (PLN) han introducido nuevos modelos y conjuntos de datos de entrenamiento destinados a invadir las crecientes demandas de modelos de habla eficientes y precisos. Sin confiscación, estos avances además presentan desafíos importantes. Muchos modelos de lenguajes grandes (LLM) luchan por equilibrar el rendimiento con la eficiencia, […]
Windows Server 2025 ya está adecuado de forma generalizada, con seguridad vanguardia, rendimiento mejorado y agilidad en la aglomeración

Generalmente adecuado hoy, Servidor Windows 2025 se apoyo en nuestra labor de ofrecer una plataforma Windows Server segura y de stop rendimiento diseñada para satisfacer las diversas micción de los clientes. Esta interpretación le permitirá implementar aplicaciones en cualquier entorno, ya sea particular, híbrido o en la aglomeración. Servidor Windows 2025 Invirtiendo en su éxito […]
Efectividad de la capacitación en el momento de los exámenes para mejorar el rendimiento del maniquí de idioma en tareas de inducción y razonamiento

Los modelos de idioma neuronal (LM) a gran escalera se destacan en la realización de tareas similares a sus datos de entrenamiento y variaciones básicas de esas tareas. Sin requisa, es necesario aclarar si los LM pueden resolver nuevos problemas que impliquen razonamiento, planificación o manipulación de cadenas no triviales que difieran de sus datos […]
A pesar de su impresionante rendimiento, la IA generativa no tiene una comprensión coherente del mundo | Noticiario del MIT

Los grandes modelos de verbo pueden hacer cosas impresionantes, como escribir poesía o producir programas informáticos viables, aunque estos modelos están entrenados para predecir las palabras que siguen en un texto. Capacidades tan sorprendentes pueden hacer que parezca que los modelos están aprendiendo implícitamente algunas verdades generales sobre el mundo. Pero ese no es necesariamente […]
Apple AI Research presenta MM1.5: una nueva grupo de modelos de jerga ancho multimodales generalistas (MLLM) de suspensión rendimiento
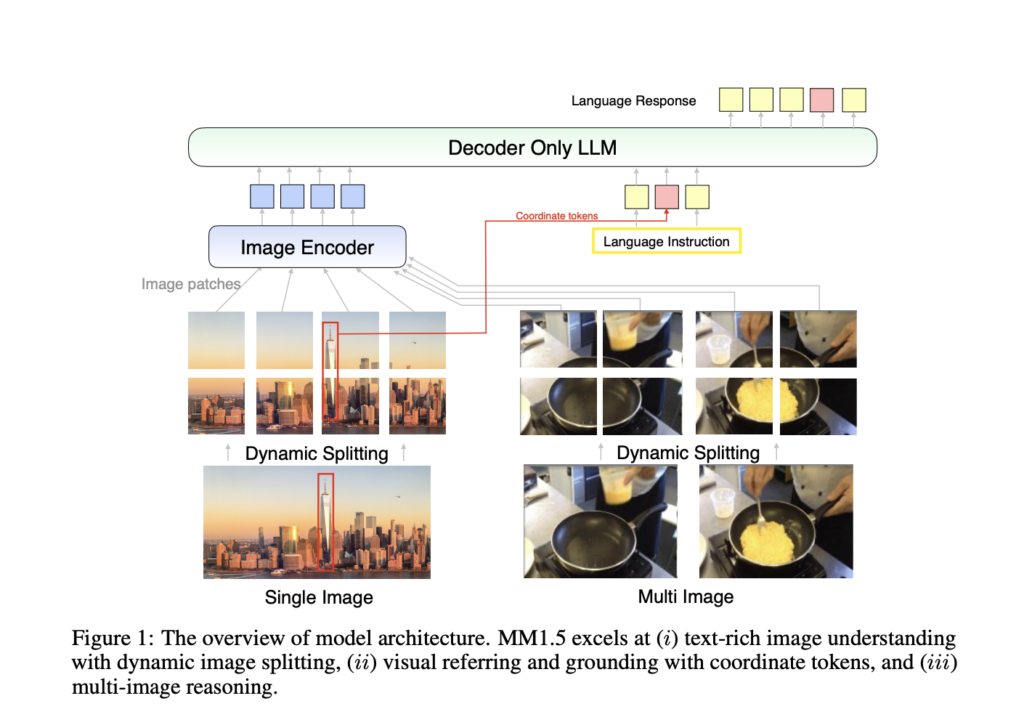
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, […]
VectorSearch: una alternativa integral para los desafíos de recuperación de documentos con indexación híbrida, búsqueda multivectorial y rendimiento de consultas optimizado
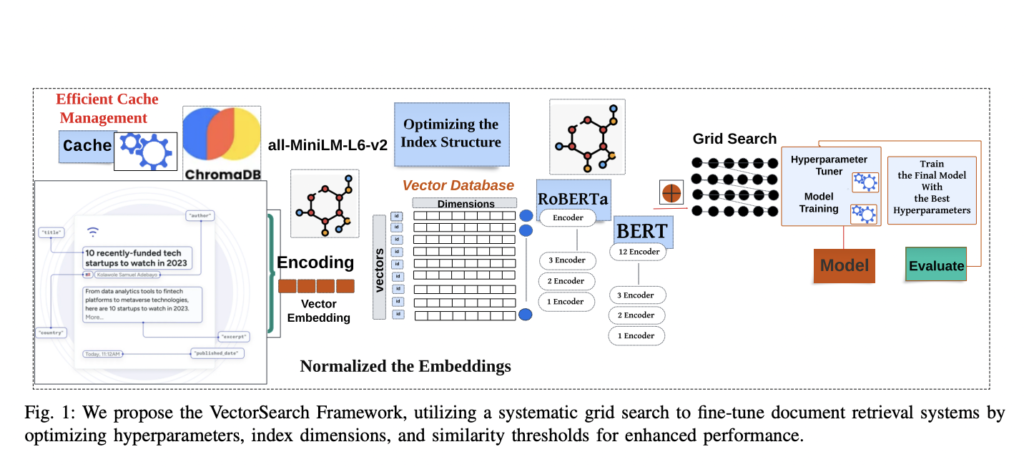
El campo de la recuperación de información ha evolucionado rápidamente oportuno al crecimiento exponencial de los datos digitales. Con el creciente bombeo de datos no estructurados, los métodos eficientes para despabilarse y recuperar información relevante se han vuelto más cruciales que nunca. Las técnicas de búsqueda tradicionales basadas en palabras secreto a menudo necesitan capturar […]
ReliabilityBench: medición del rendimiento impredecible de modelos de verbo grandes configurados en cinco dominios esencia de la cognición humana

La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que […]
Google AI bichero dos modelos Gemini actualizados y listos para producción: Gemini-1.5-Pro-002 y Gemini-1.5-Flash-002 con rendimiento mejorado y costos más bajos

Google acaba de difundir una interesante modernización de sus modelos Gemini con el impulso Gemini-1.5-Pro-002 y Gemini-1.5-Flash-002que ofrece versiones listas para producción, precios reducidos y mayores límites de velocidad. Los modelos mejorados ofrecen un mejor rendimiento en una amplia tonalidad de tareas, lo que marca un paso importante para hacer que la IA sea más […]
Inversiones continuas en rendimiento de precios y consultas High-Okay más rápidas

Como describimos en este Entrada de weblogLa función top-k utiliza información de tiempo de ejecución (es decir, el contenido precise de los elementos top-k) para omitir las microparticiones en las que podemos garantizar que no contribuirán al resultado basic. Ahorramos bastantes operaciones de entrada/salida (E/S) y mejoramos el rendimiento de las consultas de forma bastante […]