
Una implementación de codificación para crear una canalización unificada de Apache Beam que demuestra el procesamiento por lotes y transmisiones con ventanas de tiempo de eventos mediante DirectRunner

En este tutorial, demostramos cómo construir un unificado Haz Apache canalización que funciona a la perfección tanto en modo por lotes como en modo secuencial utilizando DirectRunner. Generamos datos sintéticos que tienen en cuenta la hora del evento y aplicamos ventanas fijas con activadores y retrasos permitidos para demostrar cómo Apache Beam maneja consistentemente eventos […]
Amazon EMR Serverless elimina el aprovisionamiento de almacenamiento restringido, lo que reduce los costos de procesamiento de datos hasta en un 20 %

En AWS re: Inventar 2025, Servicios web de Amazon (AWS) anunció almacenamiento sin servidor para Amazon EMR Serverlessuna nueva capacidad que elimina la carencia de configurar discos locales para cargas de trabajo de Apache Spark. Esto reduce los costos de procesamiento de datos hasta en un 20 % y, al mismo tiempo, elimina las fallas […]
Cómo Taxbit logró ahorros de costos y tiempos de procesamiento más rápidos utilizando Amazon S3 Tables

En esta publicación, analizamos cómo Taxbit se asoció con Servicios web de Amazon (AWS) para optimizar su decisión de exploración de impuestos criptográficos utilizando Tablas de Amazon S3logrando un hucha de costos del 82 % y tiempos de procesamiento cinco veces más rápidos. Impuesto es una suite líder en cumplimiento tributario que presta servicios a […]
Amazon Kinesis Data Streams ahora admite tamaños de registros 10 veces mayores: simplificación del procesamiento de datos en tiempo actual

Hoy, AWS anunció que Flujos de datos de Amazon Kinesis ahora admite tamaños de registro de hasta 10 MiB, un aumento diez veces decano que el meta susodicho. Con este impulso, ahora puede difundir cargas enseres de datos más grandes de forma intermitente en sus flujos de datos mientras continúa usando las API de Kinesis […]
Acelerar el procesamiento de préstamos con IA en Databricks: cómo Vantage Bank Texas transformó los flujos de trabajo de préstamos
Un agradecimiento específico a Shawn Main, Caudillo de Arquitecto de Negocios de Vantage Bank, por su visión y confianza en asociarse con Cavallo Technologies y Databricks como aliados estratégicos en este delirio de transformación de IA. Procesos manuales que desaceleran los préstamos Para Preeminencia MesaLa preparación de las solicitudes de préstamos fue un proceso de […]
Use los flujos de trabajo de flujo de atmósfera Apache para orquestar el procesamiento de datos en Amazon Sagemaker Unified Studio

La orquestación de tuberías de formación mecánico es confuso, especialmente cuando el procesamiento de datos, la capacitación y la implementación abarcan múltiples servicios y herramientas. En esta publicación, caminamos a través de un ejemplo práctico y de extremo a extremo de desarrollar, probar y ejecutar una tubería de formación mecánico (ML) utilizando capacidades de flujo […]
Use el dominio de aggiornamento de Amazon Datazone a Amazon Sagemaker y expandido a nuevos casos de SQL Analytics, Procesamiento de datos y usos de IA.

¡No te pierdas nuestro próximo seminario web! Registro aquí para unirse a los expertos de AWS mientras se sumergen y comparten ideas prácticas para renovar a Sagemaker. Amazon Datazone y Amazon Sagemaker Anunció una nueva característica que permite que un dominio de Amazon Datazone se actualice a la próxima procreación de Sagemaker, lo que hace […]
Procesamiento de documentos inteligentes escalables utilizando Amazon Bedrock Data Automation
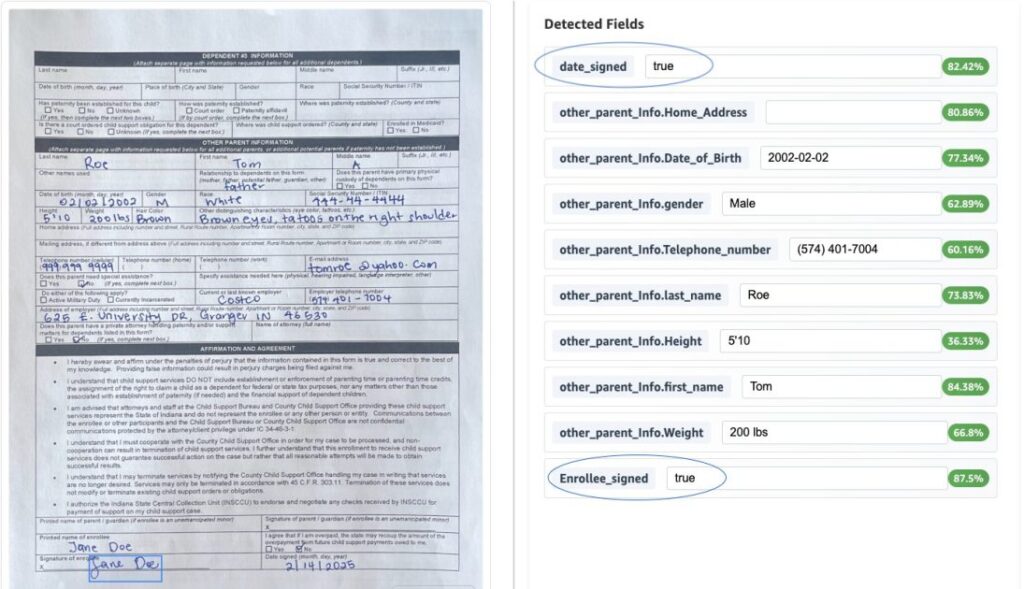
El procesamiento de documentos inteligentes (IDP) es una tecnología para automatizar la linaje, examen e interpretación de información crítica de una amplia serie de documentos. Mediante el uso de algoritmos avanzados de enseñanza automotriz (ML) y de procesamiento del verbo natural, las soluciones de IDP pueden extraer y procesar de forma apto los datos estructurados […]
Google DeepMind emite procesadores Genai: una biblioteca de pitón liviana que permite un procesamiento de contenido valioso y paralelo

Google Deepmind arrojado recientemente Procesadores de Genaiuna biblioteca liviana de Python de código campechano construida para simplificar la orquestación de flujos de trabajo generativos de IA, especialmente aquellos que involucran contenido multimodal en tiempo actual. Agresivo la semana pasada y arreglado bajo un Osadía Apache‑2.0esta biblioteca proporciona un entorno de flujo asincrónico de stop rendimiento […]
Procesamiento por lotes vs capacitación de mini lotes en formación profundo

Deep Learning ha revolucionado el campo AI al permitir que las máquinas comprendan información más profunda interiormente de nuestros datos. El formación profundo ha podido hacer esto replicando cómo nuestro cerebro funciona a través de la razonamiento de las sinapsis de neuronas. Uno de los aspectos más críticos de la capacitación de modelos de formación […]