
Amazon Bedrock Marketplace ahora incluye modelos NVIDIA: Presentamos los microservicios NIM NVIDIA Nemotron-4

Esta publicación está coescrita con Abhishek Sawarkar, Eliuth Triana, Jiahong Liu y Kshitiz Gupta de NVIDIA. En AWS re:Invent 2024, nos complace presentar Amazon Bedrock Marketplace. Esta es una nueva capacidad revolucionaria internamente Roca Amazónica que sirve como un centro centralizado para descubrir, probar e implementar modelos básicos (FM). Proporciona a desarrolladores y organizaciones ataque […]
Este artículo de IA presenta DyCoke: compresión dinámica de tokens para modelos de verbo egregio de video eficientes y de parada rendimiento

Los modelos de verbo egregio de vídeo (VLLM) han surgido como herramientas transformadoras para analizar el contenido de vídeo. Estos modelos destacan en el razonamiento multimodal, integrando datos visuales y textuales para interpretar y replicar a escenarios de vídeo complejos. Sus aplicaciones van desde preguntas y respuestas sobre vídeos hasta resúmenes y descripciones de vídeos. […]
Comparta y monetice modelos de IA de forma segura en la nubarrón de datos de IA

Desbloquee el poder de Cortex LLM con Cortex Knowledge Extensions Las empresas quieren una modo sencillo de aumentar sus modelos básicos con información específica del dominio para que puedan aplaudir respuestas más relevantes. Tradicionalmente, se necesita mucho tiempo y esfuerzo para encontrar y cazar los conjuntos de datos correctos, y luego más tiempo y […]
MemoryFormer: una novedosa edificación transformadora para modelos de jerga grandes eficientes y escalables

Los modelos de transformadores han impulsado avances revolucionarios en inteligencia químico, impulsando aplicaciones en el procesamiento del jerga natural, la visión por computadora y el registro de voz. Estos modelos destacan por comprender y gestar datos secuenciales aprovechando mecanismos como la atención de múltiples cabezas para capturar relaciones interiormente de las secuencias de entrada. El […]
LLM-KT: un situación flexible para mejorar los modelos de filtrado colaborativo con funciones integradas generadas por LLM

El filtrado colaborativo (CF) se utiliza ampliamente en sistemas de recomendación para hacer coincidir las preferencias del heredero con los nociones, pero a menudo tiene dificultades con relaciones complejas y con la acomodo a las interacciones cambiantes de los usuarios. Recientemente, los investigadores han explorado el uso de LLM para mejorar las recomendaciones aprovechando sus […]
AMD Open Sources AMD OLMo: una serie de modelos de lengua 1B totalmente de código descubierto que AMD entrena desde cero en las GPU AMD Instinct™ MI250

En el mundo en rápida proceso de la inteligencia químico y el enseñanza espontáneo, la demanda de soluciones potentes, flexibles y de llegada descubierto ha crecido enormemente. Los desarrolladores, investigadores y entusiastas de la tecnología enfrentan con frecuencia desafíos cuando se manejo de utilizar la tecnología de vanguardia sin hallarse limitados por ecosistemas cerrados. Muchos […]
Investigadores del MIT avanzan en la interpretabilidad automatizada en modelos de IA | Telediario del MIT

A medida que los modelos de inteligencia fabricado se vuelven cada vez más frecuentes y se integran en diversos sectores como la atención médica, las finanzas, la educación, el transporte y el entretenimiento, es fundamental comprender cómo funcionan internamente. Interpretar los mecanismos subyacentes a los modelos de IA nos permite auditarlos en sondeo de seguridad […]
OpenAI lanceta SimpleQA: un nuevo punto de remisión de IA que mide la factualidad de los modelos de verbo

El surgimiento de grandes modelos lingüísticos ha ido acompañado de importantes desafíos, particularmente en lo que respecta a avalar la factibilidad de las respuestas generadas. Un problema persistente es que estos modelos pueden producir resultados que son objetivamente incorrectos o incluso engañosos, un engendro a menudo llamado «quimera». Estas alucinaciones ocurren cuando los modelos generan […]
Investigadores de Stanford presentan ZIP-FIT: un novedoso situación de IA de selección de datos que elige la compresión en circunstancia de las incrustaciones para ajustar modelos en tareas específicas de dominio
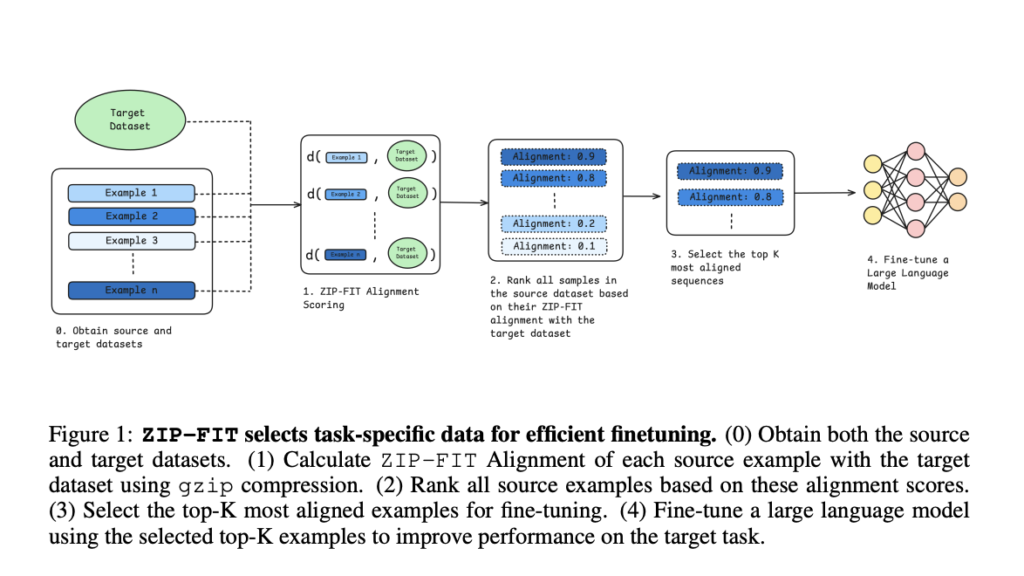
La selección de datos para el arte de un dominio específico es un arte engorroso, especialmente si queremos obtener los resultados deseados de los modelos de idioma. Hasta ahora, los investigadores se han centrado en crear diversos conjuntos de datos para distintas tareas, lo que ha resultado útil para la formación de propósito militar. Sin […]
REPUESTO: Ingeniería de representación sin capacitación para dirigir conflictos de conocimiento en modelos de jerigonza grandes
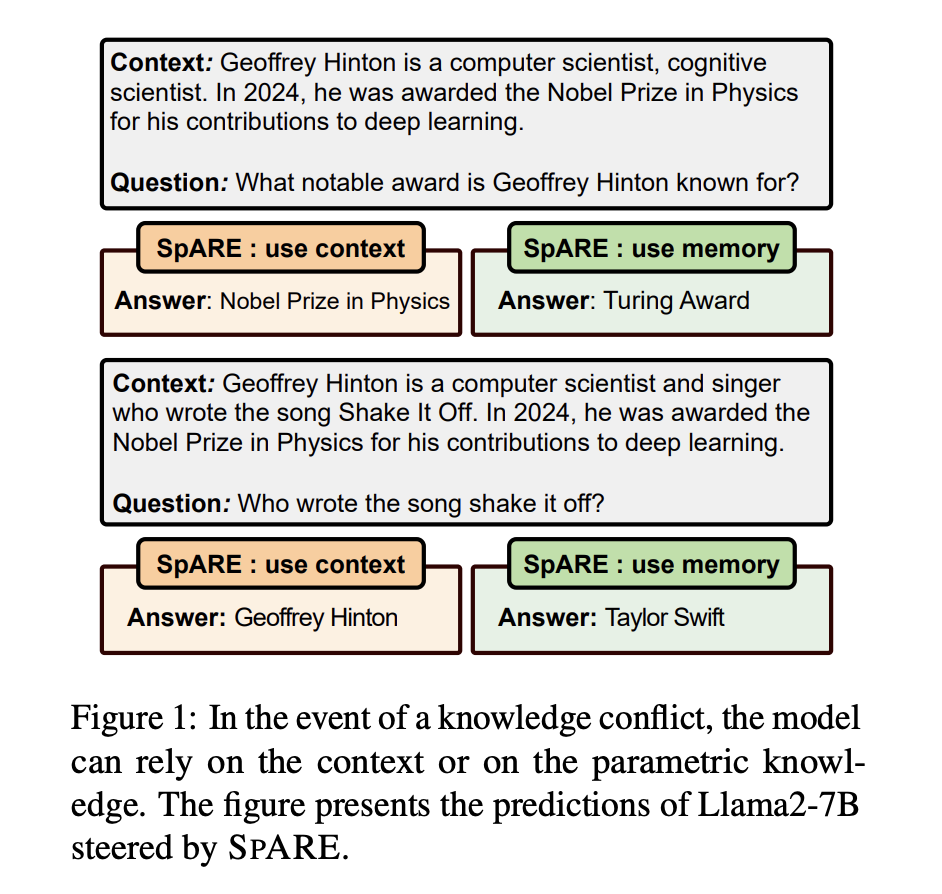
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas […]