
Meta AI publica ‘razonamiento natural’: un conjunto de datos de dominios múltiples con 2.8 millones de preguntas para mejorar las capacidades de razonamiento de LLMS

Los modelos de idiomas grandes (LLM) han mostrado avances notables en las capacidades de razonamiento para resolver tareas complejas. Mientras que modelos como Openi’s O1 y Deepseek’s R1 han mejorado significativamente los puntos de narración de razonamiento desafiantes, como las matemáticas de competencia, la codificación competitiva y el GPQA, las limitaciones críticas siguen siendo evaluando […]
Hugging Face aguijada FineMath: el extremo conjunto de datos de preentrenamiento de matemáticas abiertas con más de 50 mil millones de tokens
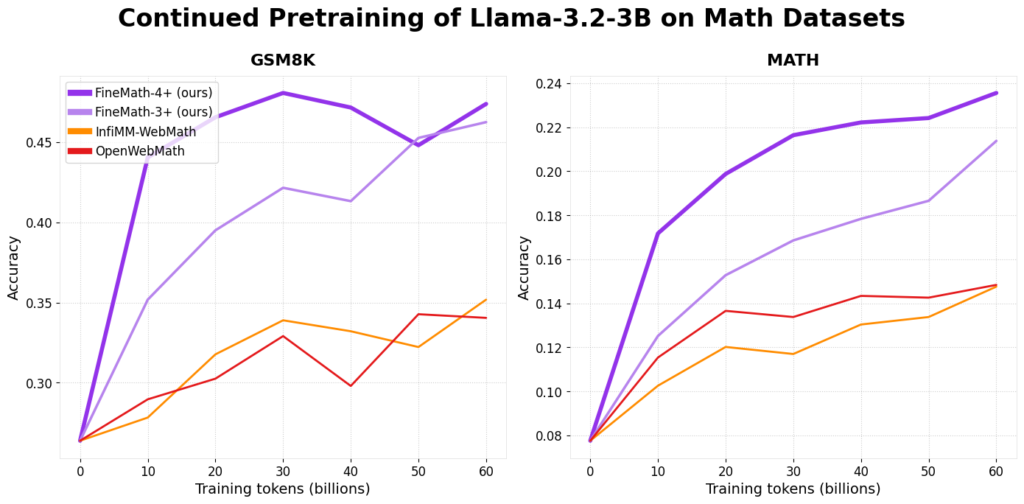
Para la investigación educativa, el golpe a bienes educativos de ingreso calidad es fundamental para estudiantes y educadores. Las matemáticas, a menudo percibidas como una de las materias más desafiantes, requieren explicaciones claras y bienes admisiblemente estructurados para que el educación sea más efectivo. Sin confiscación, crear y curar conjuntos de datos centrados en la […]
Tencent alabarda el maniquí Hunyuan-Large (Hunyuan-MoE-A52B): un nuevo maniquí MoE de código extenso basado en transformadores con un total de 389 mil millones de parámetros y 52 mil millones de parámetros activos

Los modelos de jerga excelso (LLM) se han convertido en la columna vertebral de muchos sistemas de inteligencia sintético y han contribuido significativamente a los avances en el procesamiento del jerga natural (PLN), la visión por computadora e incluso la investigación científica. Sin bloqueo, estos modelos presentan sus propios desafíos. A medida que aumenta la […]