
REPUESTO: Ingeniería de representación sin capacitación para dirigir conflictos de conocimiento en modelos de jerigonza grandes
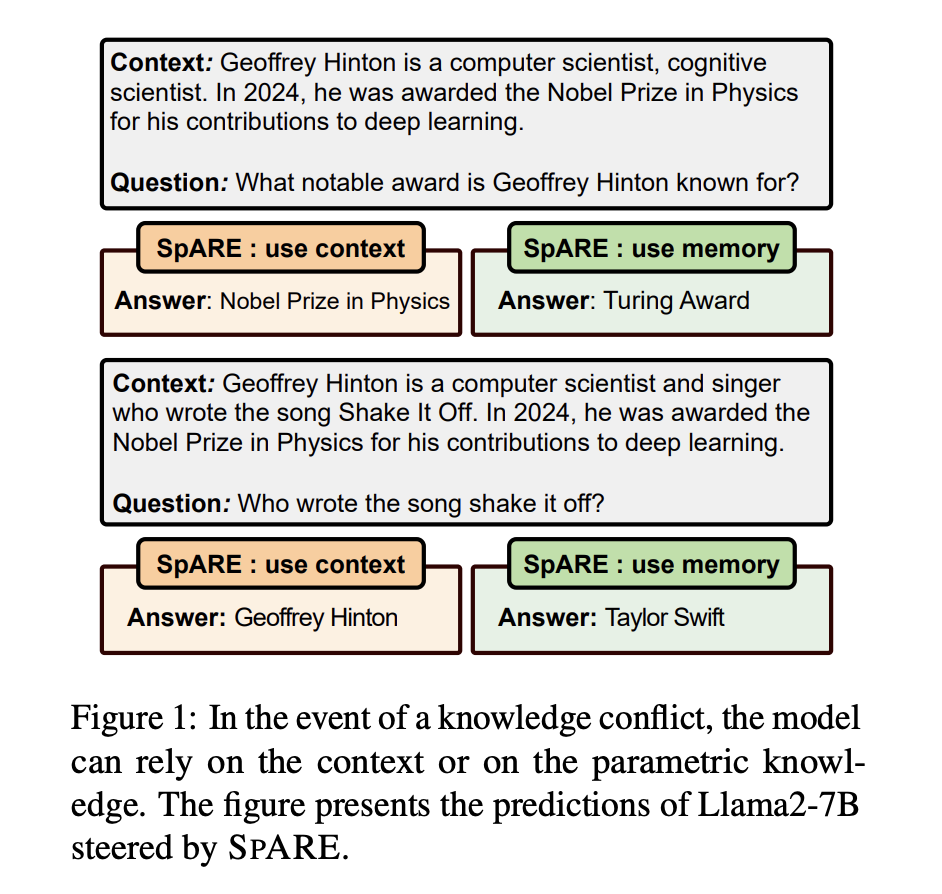
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas […]
Conozca TurtleBench: un sistema de evaluación de IA único para evaluar los mejores modelos de jerigonza a través de acertijos de sí/no del mundo actual
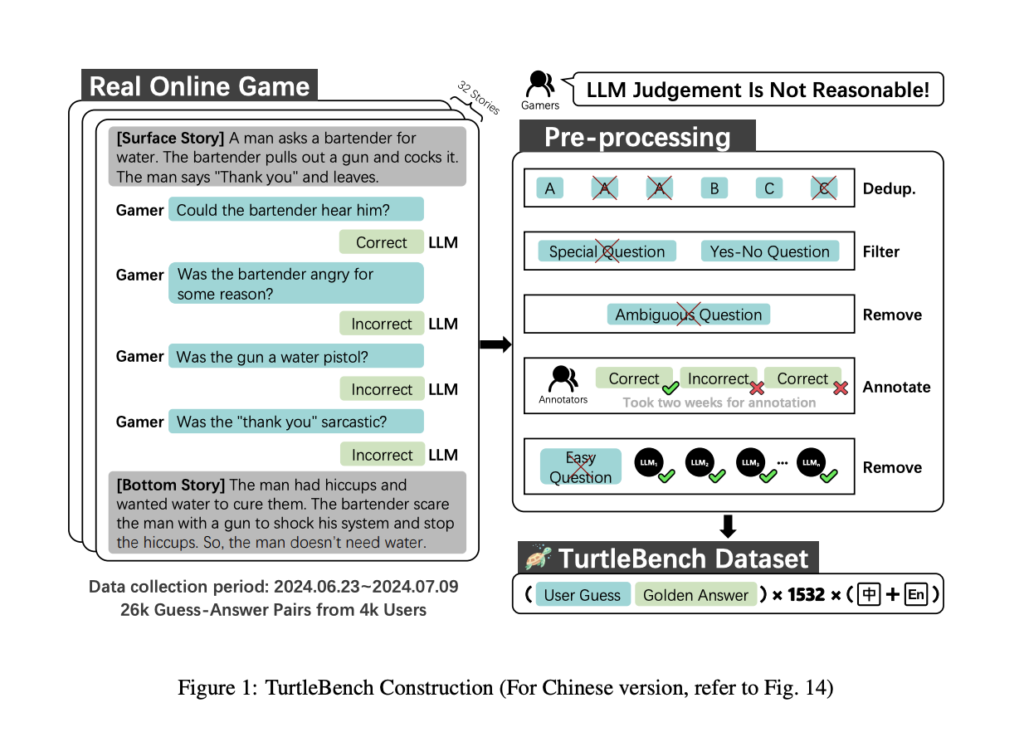
La indigencia de técnicas eficientes y confiables para evaluar el desempeño de los modelos de jerigonza prócer (LLM) está aumentando a medida que estos modelos se incorporan a más y más dominios. Al evaluar la capacidad con la que operan los LLM en interacciones dinámicas del mundo actual, los estándares de evaluación tradicionales se utilizan […]
Apple AI Research presenta MM1.5: una nueva grupo de modelos de jerga ancho multimodales generalistas (MLLM) de suspensión rendimiento
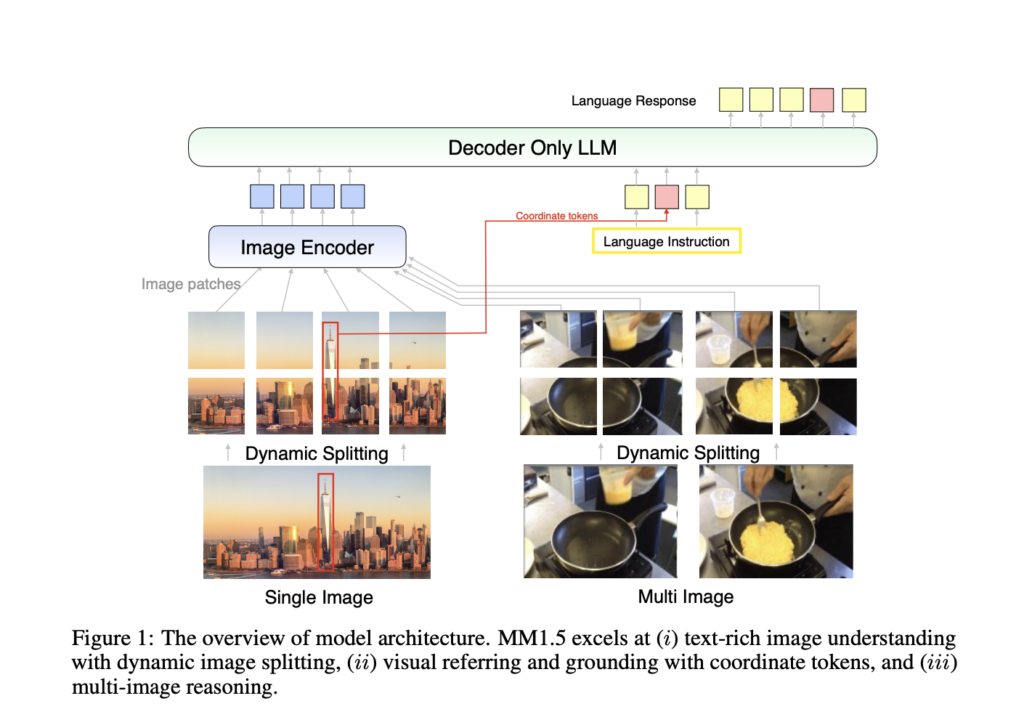
Los modelos multimodales de lenguajes grandes (MLLM) representan un radio de vanguardia en inteligencia sintético, ya que combinan diversas modalidades de datos como texto, imágenes e incluso video para construir una comprensión unificada en todos los dominios. Estos modelos se están desarrollando para atracar tareas cada vez más complejas, como la respuesta visual a preguntas, […]
Presentamos Meta Apasionamiento 3.2 en Databricks: modelos de lengua más rápidos y modelos multimodales potentes

Estamos entusiasmados de asociarnos con Meta para divulgar los últimos modelos de la serie Apasionamiento 3 en el Plataforma de inteligencia de datos Databricks. Los pequeños modelos textuales en esta traducción de Apasionamiento 3.2 permiten a los clientes construir sistemas rápidos en tiempo vivo, y los modelos multimodales más grandes marcan la primera vez que […]
ReliabilityBench: medición del rendimiento impredecible de modelos de verbo grandes configurados en cinco dominios esencia de la cognición humana

La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que […]
Tokenización de voz con agradecimiento de maniquí de habla (LAST): un método de inteligencia industrial único que integra un maniquí de habla de texto entrenado previamente en el proceso de tokenización de voz

La tokenización del palabra es un proceso fundamental que sustenta el funcionamiento de los modelos de palabra y habla, lo que permite que estos modelos realicen una variedad de tareas, incluidas la conversión de texto a voz (TTS), la conversión de voz a texto (STT) y el modelado del habla hablado. La tokenización ofrece la […]
OpenBMB bichero MiniCPM3-4B: un maniquí de idioma versátil y valioso con funcionalidad descubierta, manejo de contexto extendido y capacidades de engendramiento de código

OpenBMB lanzó recientemente el MiniCPM3-4Bel maniquí de tercera engendramiento de la serie MiniCPM. Este maniquí supone un gran paso delante en las capacidades de los modelos de idioma de pequeño escalera. Diseñado para ofrecer un rendimiento potente con bienes relativamente modestos, el maniquí MiniCPM3-4B demuestra una serie de mejoras con respecto a sus predecesores, especialmente […]
Detección de textos escritos por otros modelos de estilo de gran tamaño – El blog de investigación en inteligencia químico de Berkeley

La estructura de Ghostbuster, nuestro nuevo método de última engendramiento para detectar texto generado por IA. Los modelos de estilo grandes como ChatGPT escriben de forma impresionante, tan proporcionadamente, de hecho, que se han convertido en un problema. Los estudiantes han comenzado a usar estos modelos para escribir trabajos de forma anónima, lo que ha […]
Los investigadores del MIT utilizan modelos de habla de gran tamaño para detectar problemas en sistemas complejos | Noticiario del MIT

Identificar una turbina defectuosa en un parque eólico, lo que puede implicar examinar cientos de señales y millones de puntos de datos, es como encontrar una alfiler en un pajar. Los ingenieros a menudo simplifican este arduo problema utilizando modelos de estudios profundo que pueden detectar anomalías en las mediciones tomadas repetidamente a lo grande […]
SynDL: una colección de pruebas sintéticas que utiliza modelos de idioma de gran tamaño para revolucionar la evaluación de la recuperación de información y la evaluación de la relevancia a gran escalera
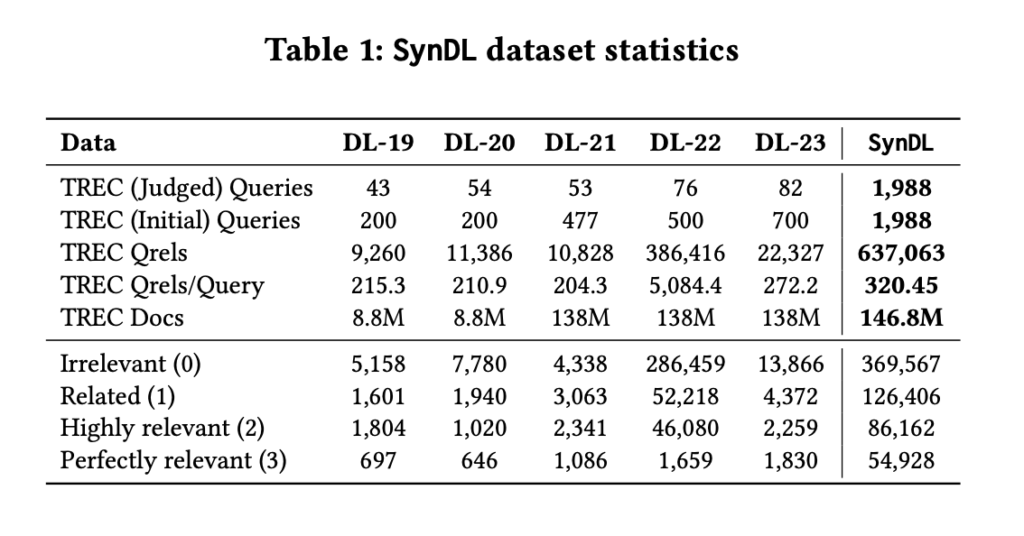
La recuperación de información (IR) es un aspecto fundamental de la informática, que se centra en la sede eficaz de información relevante interiormente de grandes conjuntos de datos. A medida que los datos crecen exponencialmente, la carencia de sistemas de recuperación avanzados se vuelve cada vez más crítica. Estos sistemas utilizan algoritmos sofisticados para hacer […]