
Medrar la anotación de datos utilizando modelos de visión y lengua para impulsar sistemas físicos de IA

La escasez crítica de mano de obra está limitando el crecimiento en los sectores de manufactura, provisión, construcción y agricultura. El problema es particularmente moribundo en la construcción: casi 500.000 puestos siguen sin cubrir en los Estados Unidos, con 40% de la fuerza profesional presente que se aproxima a la renta internamente de la plazo. […]
DeepSeek mHC: Estabilización del entrenamiento de modelos de jerigonza grandes

Los grandes modelos de IA están escalando rápidamente, con arquitecturas más grandes y ciclos de entrenamiento más largos convirtiéndose en la norma. Sin secuestro, a medida que los modelos crecen, un problema fundamental de estabilidad del entrenamiento sigue sin resolverse. DeepSeek mHC aborda directamente este problema repensando cómo se comportan las conexiones residuales a escalera. […]
Diligencia simplificada de Amazon MSK con lengua natural mediante Kiro CLI y Amazon MSK MCP Server

Administrar y ampliar los flujos de datos de forma competente es la piedra angular del éxito de muchas organizaciones. Apache Kafka es una plataforma líder para la transmisión de datos en tiempo auténtico y ofrece escalabilidad y confiabilidad inigualables. Sin requisa, configurar y ampliar los clústeres de Kafka puede ser un desafío y requiere mucho […]
Una nueva forma de aumentar las capacidades de los modelos de habla grandes | Parte del MIT

La mayoría de los idiomas utilizan la posición de las palabras y la estructura de las oraciones para extraer el significado. Por ejemplo, “El sagaz se sentó sobre la caja” no es lo mismo que “La caja estaba sobre el sagaz”. A lo extenso de un texto extenso, como un documento financiero o una novelística, […]
Una forma más inteligente para que los modelos de estilo grandes piensen en problemas difíciles | Parte del MIT

Para que los modelos de lenguajes grandes (LLM) sean más precisos al reponer preguntas más difíciles, los investigadores pueden dejar que el maniquí dedique más tiempo a pensar en posibles soluciones. Pero los enfoques comunes que brindan a los LLM esta capacidad establecen un presupuesto computacional fijo para cada problema, independientemente de cuán complicado sea. […]
Conjuntos de datos para entrenar un maniquí de jerga

Un maniquí de jerga es un maniquí matemático que describe un jerga humano como una distribución de probabilidad sobre su vocabulario. Para entrenar una red de estudios profundo para modelar un idioma, es necesario identificar el vocabulario y instruirse su distribución de probabilidad. No puedes crear el maniquí de la nadie. Necesita un conjunto de […]
Desidentificación de imágenes médicas de forma rentable con modelos de habla de visión en Databricks

Por qué la aprieto de una desidentificación de imágenes escalable Las imágenes médicas, como los rayos X y las resonancias magnéticas, adicionalmente de ayudar en el dictamen, la planificación del tratamiento y el seguimiento de enfermedades, se utilizan cada vez más más allá de la atención individual del paciente para informar investigaciones médicas más amplias, […]
El panorama del maniquí de verbo extenso de Australia: evaluación técnica
Puntos secreto No ha surgido un buque insignia, competitivo conjuntamente competitivo (como GPT-4, Claude 3.5, Candela 3.1) de Australia. La investigación y el comercio de Australia actualmente dependen principalmente de las LLM internacionales, que se usan con frecuencia pero tienen limitaciones medibles en el contexto cultural y inglés australiano. Kangaroo LLM es el único plan […]
NVIDIA AI resuelto Jet-Nemotron: 53x Serie de maniquí de jerigonza híbrido-arquitectura híbrido que se traduce en una reducción de costos del 98% para la inferencia a escalera
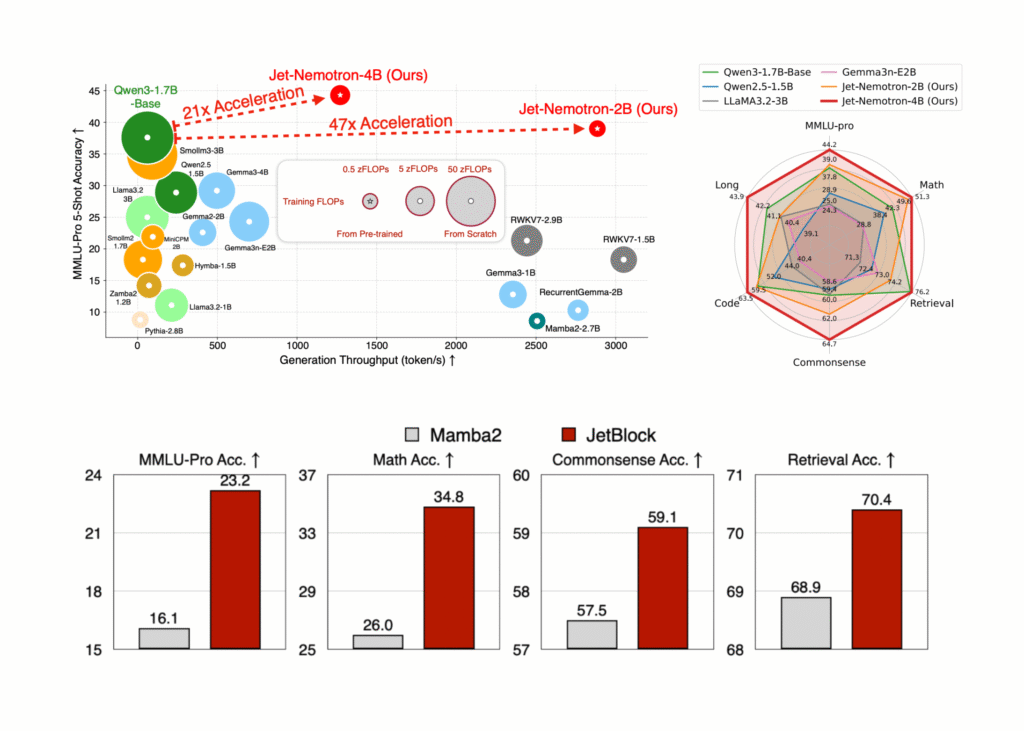
Los investigadores de NVIDIA han destrozado el obstáculo de eficiencia de larga data en la inferencia del maniquí de idioma excelso (LLM), liberando Jet-nemotrón—Un comunidad de modelos (2b y 4b) que ofrece hasta 53.6 × rendimiento de procreación más suspensión que liderar LLM de atención completa mientras coincide, o incluso superando, su precisión. Lo más […]
Los investigadores vislumbran el funcionamiento interno de los modelos de estilo de proteínas | MIT News

En los últimos abriles, los modelos que pueden predecir la estructura o función de las proteínas se han utilizado ampliamente para una variedad de aplicaciones biológicas, como identificar objetivos fármacos y diseñar nuevos anticuerpos terapéuticos. Estos modelos, que se basan en modelos de idiomas grandes (LLM), pueden hacer predicciones muy precisas de la idoneidad de […]