
Investigadores del MIT avanzan en la interpretabilidad automatizada en modelos de IA | Telediario del MIT

A medida que los modelos de inteligencia fabricado se vuelven cada vez más frecuentes y se integran en diversos sectores como la atención médica, las finanzas, la educación, el transporte y el entretenimiento, es fundamental comprender cómo funcionan internamente. Interpretar los mecanismos subyacentes a los modelos de IA nos permite auditarlos en sondeo de seguridad […]
Investigadores de Stanford presentan ZIP-FIT: un novedoso situación de IA de selección de datos que elige la compresión en circunstancia de las incrustaciones para ajustar modelos en tareas específicas de dominio
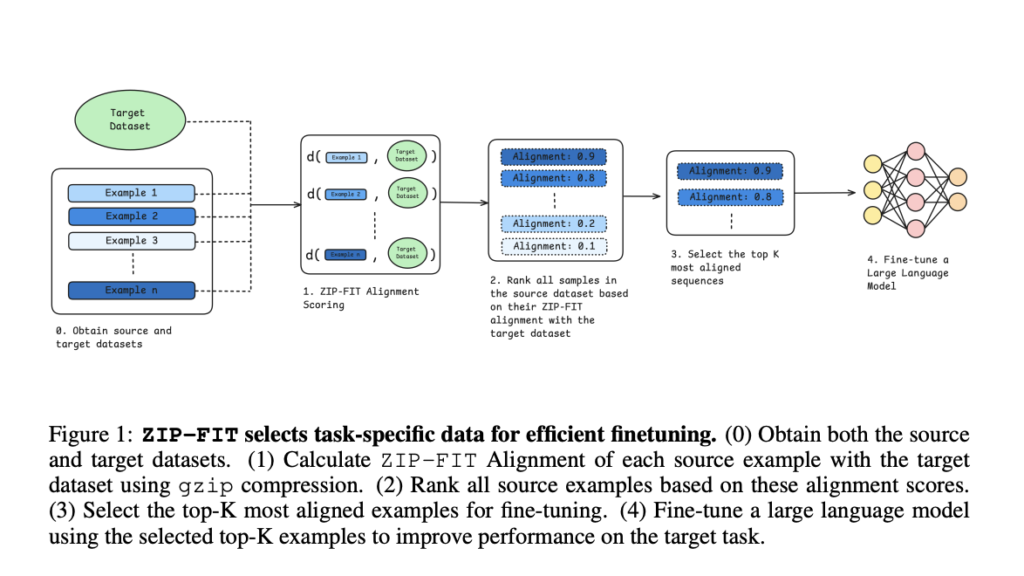
La selección de datos para el arte de un dominio específico es un arte engorroso, especialmente si queremos obtener los resultados deseados de los modelos de idioma. Hasta ahora, los investigadores se han centrado en crear diversos conjuntos de datos para distintas tareas, lo que ha resultado útil para la formación de propósito militar. Sin […]
Investigadores de UC Berkeley proponen DocETL: un sistema declarativo que optimiza tareas complejas de procesamiento de documentos mediante LLM
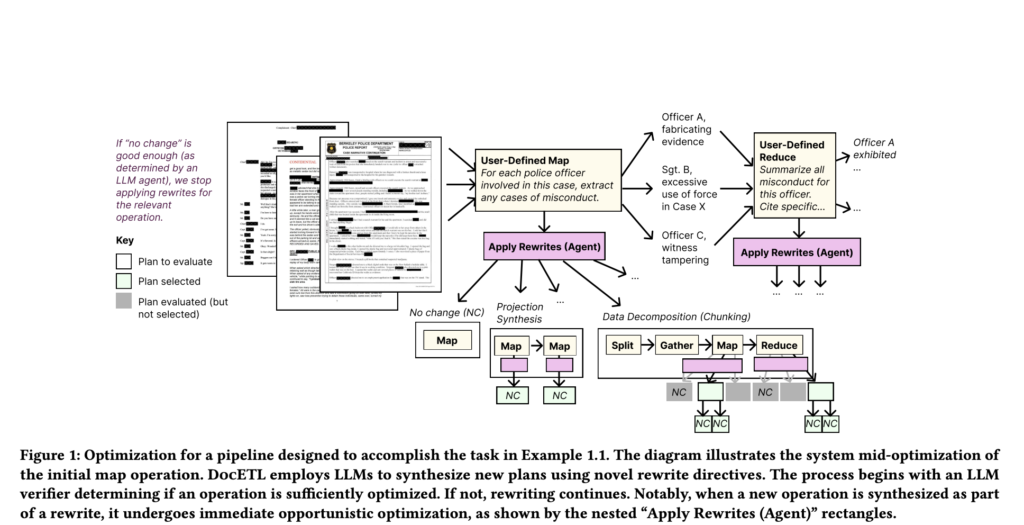
Los modelos de lenguajes grandes (LLM) han ganadería una atención significativa en la trámite de datos, con aplicaciones que abarcan la integración de datos, el ajuste de bases de datos, la optimización de consultas y la cepillado de datos. Sin secuestro, el descomposición de datos no estructurados, especialmente documentos complejos, sigue siendo un desafío en […]
Investigadores de Microsoft presentan RadEdit: modelos de visión biomédicos para pruebas de estrés mediante tiraje de imágenes por difusión para eliminar el sesgo del conjunto de datos
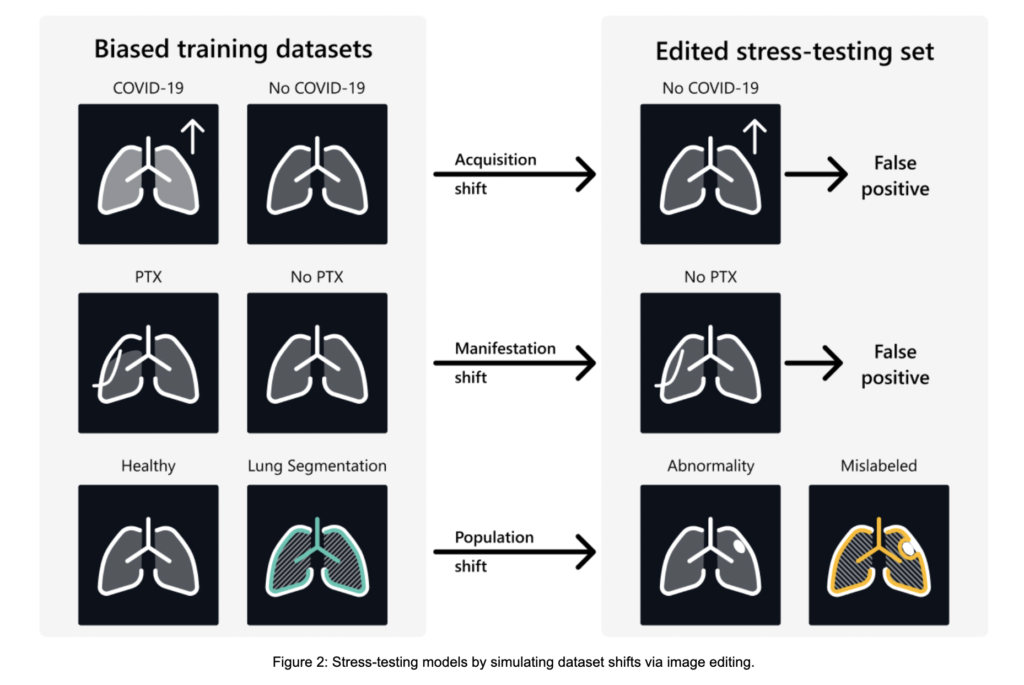
Los modelos de visión biomédicos se utilizan cada vez más en entornos clínicos, pero un desafío importante es su incapacidad para generalizarse de guisa efectiva conveniente a cambios de conjuntos de datos—Discrepancias entre los datos de entrenamiento y los escenarios del mundo efectivo. Estos cambios surgen de diferencias en la adquisición de imágenes, cambios en […]
Investigadores de John Hopkins y Samaya AI proponen un Promptriever: un recuperador de disparo cero entrenado a partir de un nuevo conjunto de datos de recuperación basado en instrucciones
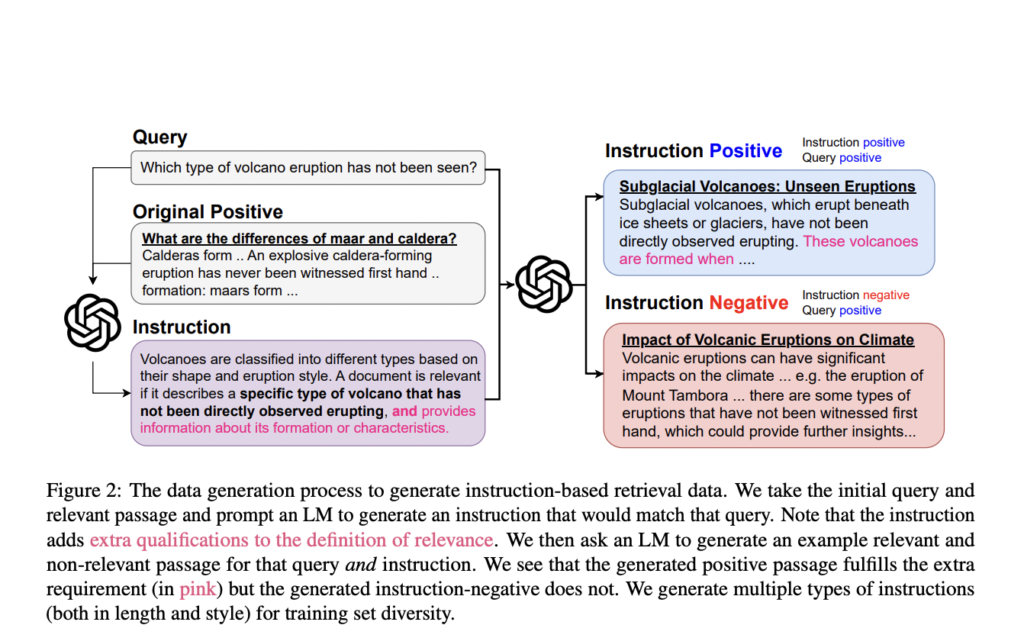
Los modelos de recuperación de información (IR) enfrentan desafíos importantes a la hora de ofrecer experiencias de búsqueda transparentes e intuitivas. Las metodologías actuales se basan principalmente en una única puntuación de similitud semántica para hacer coincidir las consultas con los pasajes, lo que genera una experiencia de favorecido potencialmente opaca. Este enfoque a menudo […]
Los investigadores de FutureHouse presentan PaperQA2: el primer agente de IA que realiza revisiones completas de letras científica por sí solo

La inteligencia fabricado (IA) está transformando la forma en que se lleva a lengua la investigación científica, especialmente a través de modelos de estilo que ayudan a los investigadores a procesar y analizar grandes cantidades de información. En la IA, los modelos de estilo extensos (LLM) se aplican cada vez más a tareas como la […]
Los investigadores del MIT utilizan modelos de habla de gran tamaño para detectar problemas en sistemas complejos | Noticiario del MIT

Identificar una turbina defectuosa en un parque eólico, lo que puede implicar examinar cientos de señales y millones de puntos de datos, es como encontrar una alfiler en un pajar. Los ingenieros a menudo simplifican este arduo problema utilizando modelos de estudios profundo que pueden detectar anomalías en las mediciones tomadas repetidamente a lo grande […]
Los investigadores de Microsoft combinan modelos de habla pequeños y grandes para una detección de alucinaciones más rápida y precisa

Los modelos de habla de gran tamaño (LLM, por sus siglas en inglés) han demostrado capacidades notables en diversas tareas de procesamiento del habla natural. Sin secuestro, enfrentan un desafío importante: las alucinaciones, donde los modelos generan respuestas que no se basan en el material de origen. Este problema socava la confiabilidad de los LLM […]