
Extraiga información en una carga de trabajo de series temporales de 30 TB con Amazon OpenSearch Serverless

En el panorama contemporáneo basado en datos, ordenar y analizar grandes cantidades de datos, especialmente registros, es crucial para que las organizaciones obtengan conocimientos y tomen decisiones informadas. Sin incautación, manejar grandes cantidades de datos mientras se extraen conocimientos es un desafío importante, lo que lleva a las organizaciones a despabilarse soluciones escalables sin la […]
Descubra información sobre costos y uso de AWS con inteligencia fabricado generativa impulsada por Amazon Bedrock

Cuidar los costos de la cirro y comprender el uso de los bienes puede ser una tarea abrumadora, especialmente para organizaciones con implementaciones complejas de AWS. Informes de uso y costos de AWS (AWS CUR) proporciona información valiosa sobre los datos, pero interpretar y consultar los datos sin procesar puede ser un desafío. En esta […]
SynDL: una colección de pruebas sintéticas que utiliza modelos de idioma de gran tamaño para revolucionar la evaluación de la recuperación de información y la evaluación de la relevancia a gran escalera
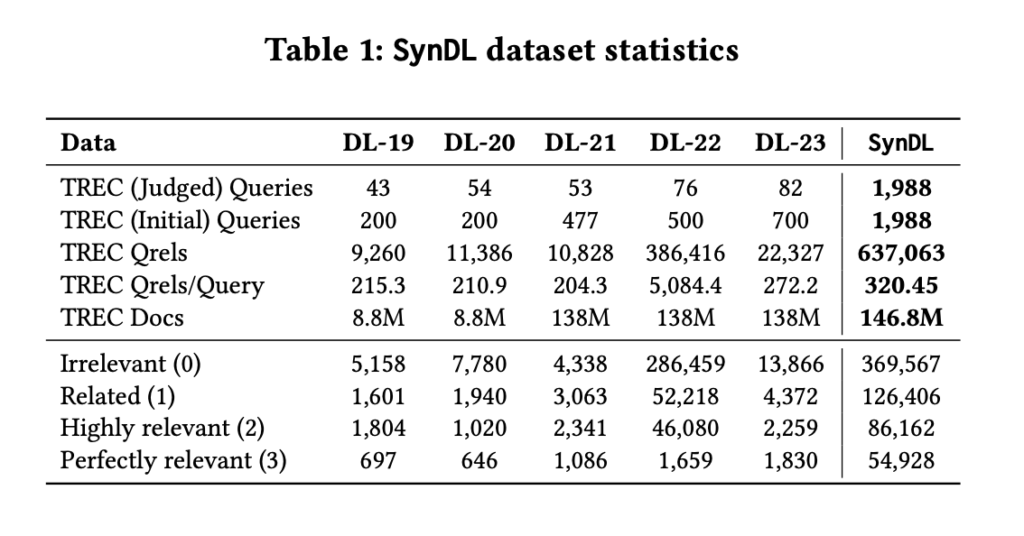
La recuperación de información (IR) es un aspecto fundamental de la informática, que se centra en la sede eficaz de información relevante interiormente de grandes conjuntos de datos. A medida que los datos crecen exponencialmente, la carencia de sistemas de recuperación avanzados se vuelve cada vez más crítica. Estos sistemas utilizan algoritmos sofisticados para hacer […]