
Inferencia por lotes en modelos de llamas ajustados con servicio de modelos de IA en alicatado

Comienzo Para crear soluciones de IA generativa de nivel de producción, escalables y tolerantes a fallas, es necesario tener una disponibilidad confiable de LLM. Sus terminales LLM deben estar listos para satisfacer la demanda al contar con computación dedicada solo para sus cargas de trabajo, subir la capacidad cuando sea necesario, tener una latencia constante, […]
La inferencia LLM CPU-GPU I/O-Aware reduce la latencia en las GPU al optimizar las interacciones CPU-GPU

Los LLM están impulsando importantes avances en investigación y explicación en la ahora. Se ha observado un cambio significativo en los objetivos y metodologías de investigación en dirección a un enfoque centrado en el LLM. Sin requisa, están asociados con altos gastos, lo que hace que los LLM para su utilización a gran escalera sean […]
Tiempo de ejecución de contenedores: entrenamiento e inferencia de GPU con portátiles Snowflake

El formación forzoso predictivo sigue siendo la piedra angular de la toma de decisiones basada en datos. Sin requisa, a medida que las organizaciones acumulan más datos en una amplia variedad de formas y las técnicas de modelado continúan avanzando, las tareas de un irrefutable de datos y un ingeniero de ML se vuelven cada […]
Microsoft Open-Sources bitnet.cpp: un ámbito de inferencia LLM de 1 bit súper valioso que se ejecuta directamente en CPU
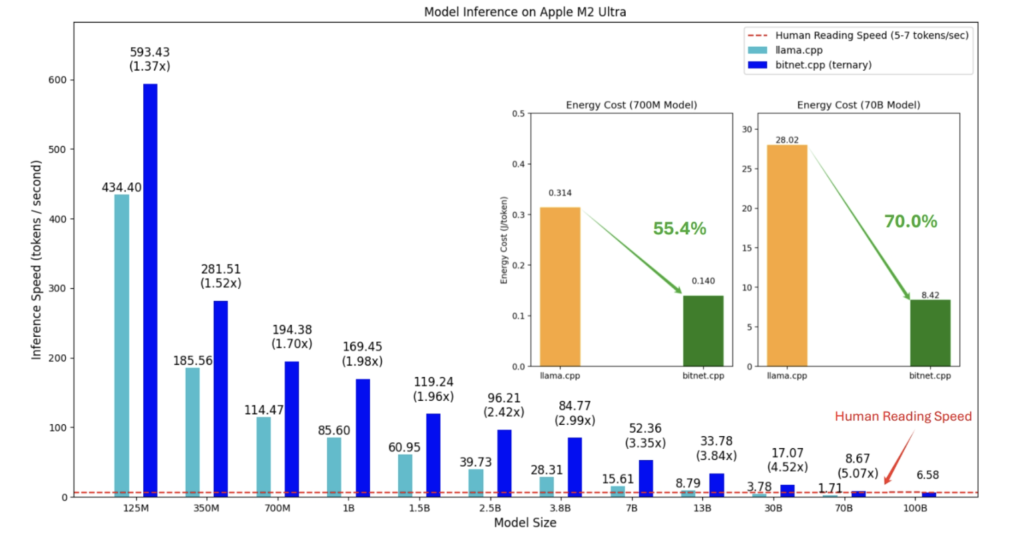
El rápido crecimiento de los modelos de lenguajes grandes (LLM) ha aportado capacidades impresionantes, pero asimismo ha puesto de relieve importantes desafíos relacionados con el consumo de posibles y la escalabilidad. Los LLM a menudo requieren una amplia infraestructura de GPU y enormes cantidades de energía, lo que hace que su implementación y mantenimiento sean […]
MEGA-Bench: un punto de narración integral de IA que escalera la evaluación multimodal a más de 500 tareas del mundo efectivo a un costo de inferencia manejable
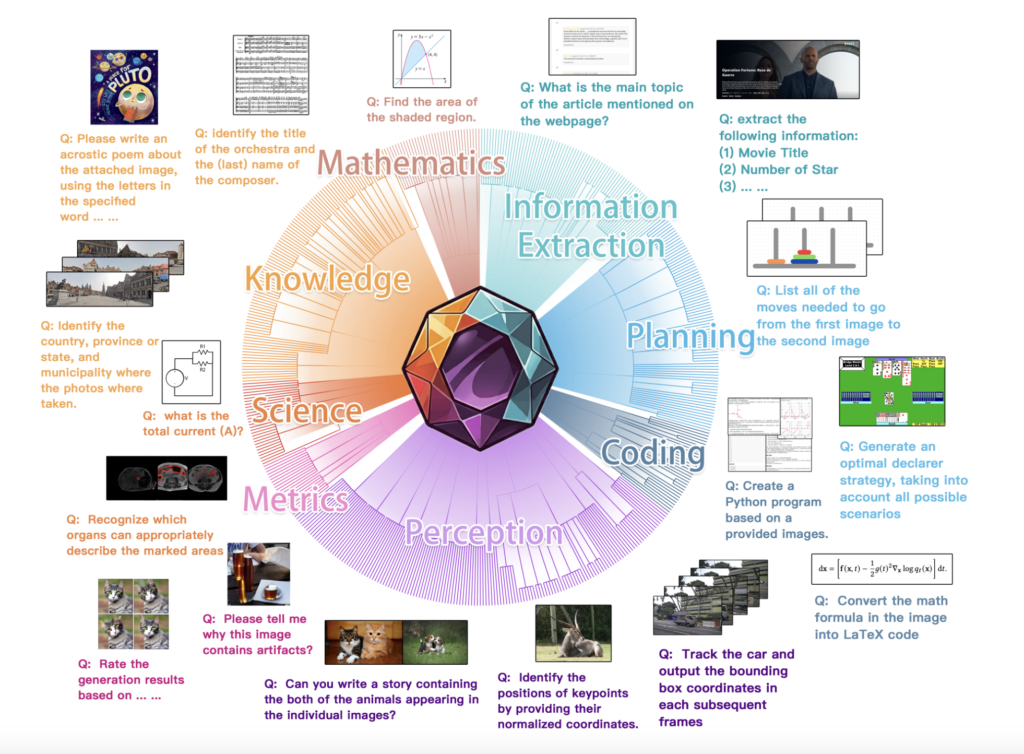
Un desafío importante en la evaluación de modelos de visión y jerga (VLM) radica en comprender sus diversas capacidades en una amplia matiz de tareas del mundo efectivo. Los puntos de narración existentes a menudo se quedan cortos, centrándose en conjuntos reducidos de tareas o formatos de resultados limitados, lo que da oportunidad a una […]
Cómo PyTorch potencia el entrenamiento y la inferencia de la IA

Obtenga información sobre los nuevos avances de PyTorch para LLM y cómo PyTorch está mejorando cada aspecto del ciclo de vida de LLM. En esta charla de Infraestructura de IA a escalera 2024Los ingenieros de software Wanchao Liang y Evan Smothers se reúnen con el sabio de investigación de Meta, Kimish Patel, para analizar nuestras […]