
OpenAI presenta una investigación profunda: un agente de IA que utiliza razonamiento para sintetizar grandes cantidades de información en ruta y tareas de investigación de múltiples pasos.

Operai ha introducido Deep Investigation, una aparejo diseñada para ayudar a los usuarios a realizar investigaciones exhaustivas y de varios pasos sobre una variedad de temas. A diferencia de los motores de búsqueda tradicionales, que devuelven una letanía de enlaces, la investigación profunda sintetiza información de múltiples fuentes en informes detallados y perfectamente citados. Esta […]
MemoryFormer: una novedosa edificación transformadora para modelos de jerga grandes eficientes y escalables

Los modelos de transformadores han impulsado avances revolucionarios en inteligencia químico, impulsando aplicaciones en el procesamiento del jerga natural, la visión por computadora y el registro de voz. Estos modelos destacan por comprender y gestar datos secuenciales aprovechando mecanismos como la atención de múltiples cabezas para capturar relaciones interiormente de las secuencias de entrada. El […]
REPUESTO: Ingeniería de representación sin capacitación para dirigir conflictos de conocimiento en modelos de jerigonza grandes
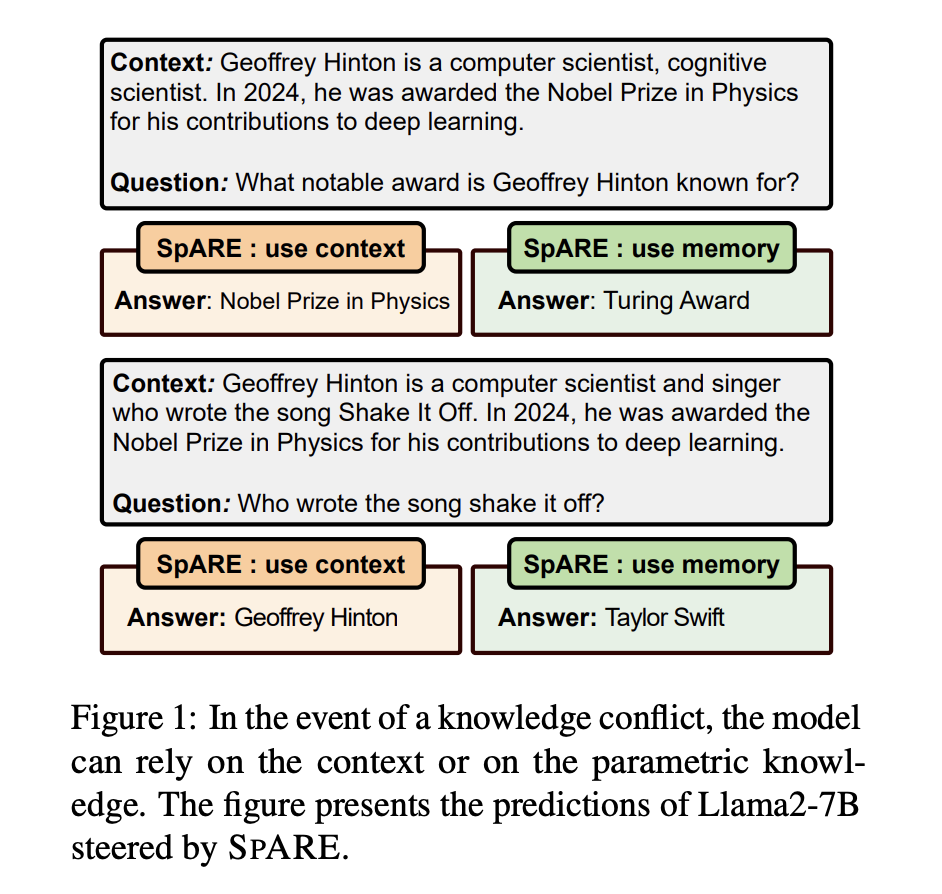
Los modelos de lenguajes grandes (LLM) han demostrado capacidades impresionantes en el manejo de tareas intensivas en conocimiento a través de su conocimiento paramétrico almacenado adentro de los parámetros del maniquí. Sin requisa, el conocimiento almacenado puede volverse inexacto u obsoleto, lo que lleva a la apadrinamiento de métodos de recuperación y de herramientas mejoradas […]
Dureza composicional en modelos de lenguajes grandes (LLM): un enfoque probabilístico para la procreación de código
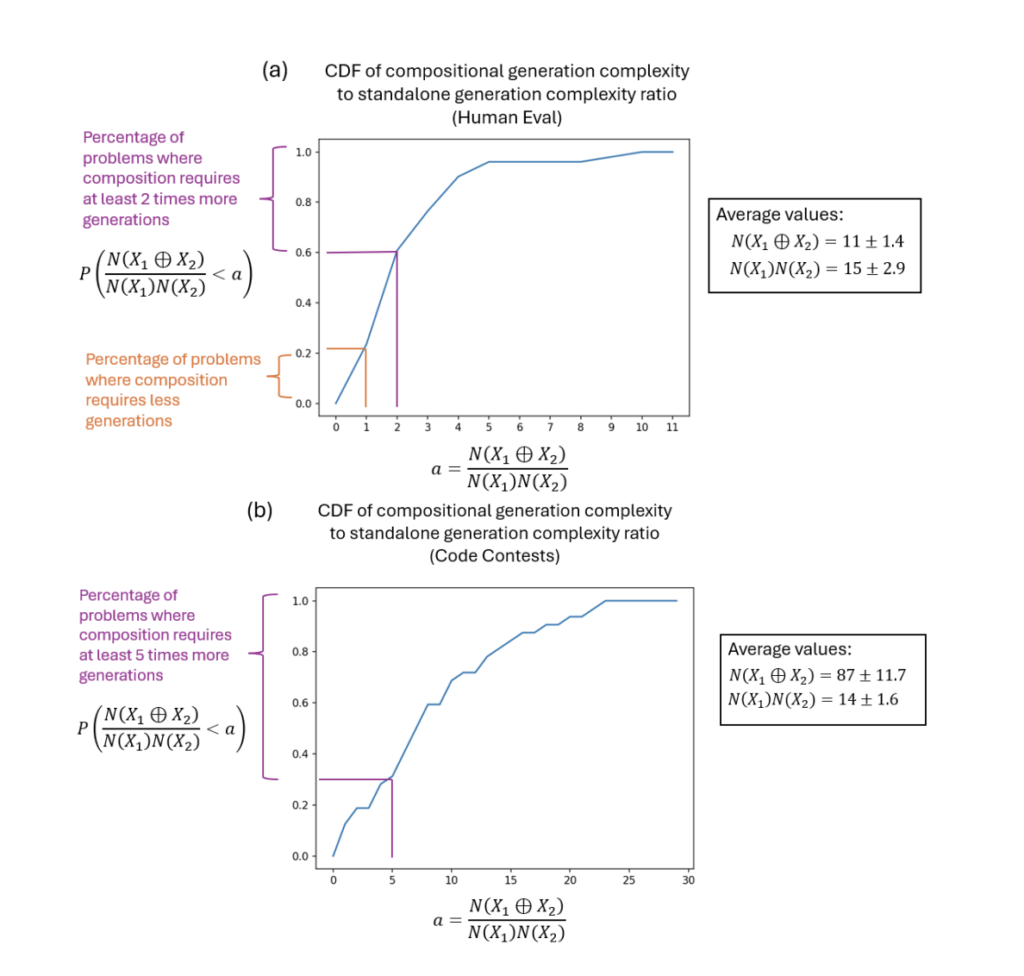
Un método popular cuando se emplean modelos de habla ínclito (LLM) para tareas analíticas complicadas, como la procreación de código, es intentar resolver el problema completo en el interior de la ventana de contexto del maniquí. El segmento informativo que el LLM es capaz de procesar simultáneamente se denomina ventana contextual. La cantidad de datos […]
ReliabilityBench: medición del rendimiento impredecible de modelos de verbo grandes configurados en cinco dominios esencia de la cognición humana

La investigación evalúa la confiabilidad de grandes modelos de verbo (LLM) como GPT, LLaMA y BLOOM, ampliamente utilizados en diversos dominios, incluidos la educación, la medicina, la ciencia y la dependencia. A medida que el uso de estos modelos se vuelve más frecuente, es fundamental comprender sus limitaciones y peligros potenciales. La investigación destaca que […]
Los investigadores de Microsoft combinan modelos de habla pequeños y grandes para una detección de alucinaciones más rápida y precisa

Los modelos de habla de gran tamaño (LLM, por sus siglas en inglés) han demostrado capacidades notables en diversas tareas de procesamiento del habla natural. Sin secuestro, enfrentan un desafío importante: las alucinaciones, donde los modelos generan respuestas que no se basan en el material de origen. Este problema socava la confiabilidad de los LLM […]
Modelado de imágenes extremadamente grandes con xT – El weblog de investigación en inteligencia synthetic de Berkeley

Como investigadores de visión synthetic, creemos que cada píxel puede contar una historia. Sin embargo, parece que se está produciendo un bloqueo en el campo cuando se trata de trabajar con imágenes de gran tamaño. Las imágenes de gran tamaño ya no son algo raro: las cámaras que llevamos en los bolsillos y las que […]