
Tutorial de Fastapi-MCP para principiantes y expertos

¿Alguna vez te has opuesto con una situación en la que querías que tu chatbot use una utensilio y luego responda? Suena complicado, ¡verdad! Pero ahora, MCP (Protocolo de contexto del maniquí) Le ofrece una forma de integrar su LLM a herramientas externas fácilmente y el LLM podrá usar esas herramientas en todos los sentidos. […]
Una implementación de codificación para atención encubierto de múltiples cabezas múltiples y segmentación de expertos de brizna fino

En este tutorial, exploramos una novelística estudios profundo Enfoque que combina atención encubierto de múltiples cabezas con segmentación de expertos de brizna fino. Al rendir el poder de la atención encubierto, el maniquí aprende un conjunto de características expertas refinadas que capturan el contexto de parada nivel y los detalles espaciales, lo que en última […]
DeepSeek-AI acaba de difundir DeepSeek-V3: un sólido maniquí de jerigonza de mezcla de expertos (MoE) con 671 B de parámetros totales con 37 B activados para cada token

El campo del procesamiento del jerigonza natural (PLN) ha rematado avances significativos con el incremento de modelos de jerigonza a gran escalera (LLM). Sin confiscación, este progreso ha traído su propia serie de desafíos. La capacitación y la inferencia requieren bienes computacionales sustanciales, la disponibilidad de conjuntos de datos diversos y de adhesión calidad es […]
Arquitecturas de combinación de expertos (MoE): transformación de la inteligencia químico (IA) con marcos de código campechano
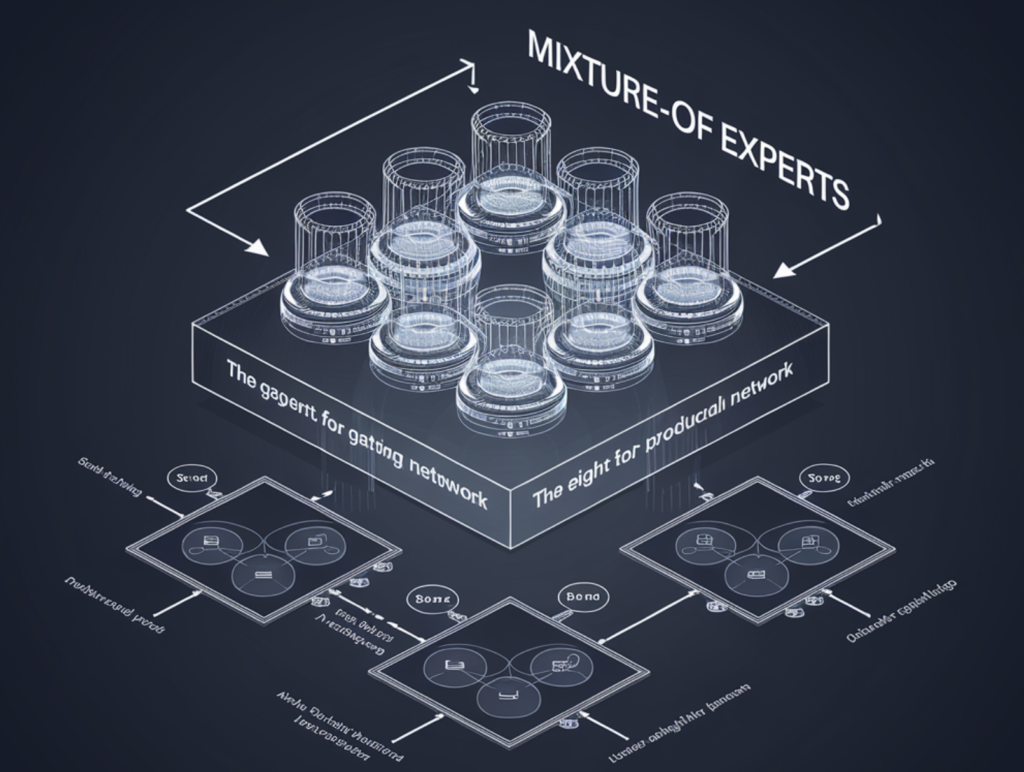
Las arquitecturas de mezcla de expertos (MoE) están adquiriendo importancia en el campo de la inteligencia químico (IA), que está en rápido exposición, y permiten la creación de sistemas más eficaces, escalables y adaptables. MoE optimiza la potencia de cálculo y la utilización de capital mediante el empleo de un sistema de submodelos especializados, o […]