
Los investigadores de Microsoft AI introducen técnicas avanzadas de cuantificación de bajo bits para permitir la implementación de LLM efectivo en dispositivos de borde sin altos costos computacionales

Los dispositivos de borde como los teléfonos inteligentes, los dispositivos IoT y los sistemas integrados procesan datos localmente, mejorando la privacidad, la reducción de la latencia y la progreso de la capacidad de respuesta, y la IA se está integrando rápidamente en estos dispositivos. Pero, implementar modelos de idiomas grandes (LLM) en estos dispositivos es […]
Impulse el progreso de software válido e impulse DevEx con GitHub Copilot

En este blog, exploraremos cómo las características únicas de Copilot mejoran cada ambiente de DevEx en todo el ámbito SPACE. Las empresas líderes están reconociendo que la productividad de los desarrolladores por sí sola no es suficiente para sostener el éxito a generoso plazo. A medida que la demanda de ingenieros de software capacitados continúa […]
Investigadores del MIT desarrollan una forma capaz de entrenar agentes de IA más confiables | Noticiario del MIT
Campos que van desde la robótica hasta la medicina y las ciencias políticas están intentando entrenar sistemas de inteligencia fabricado para tomar decisiones significativas de todo tipo. Por ejemplo, utilizar un sistema de inteligencia fabricado para controlar de forma inteligente el tráfico en una ciudad congestionada podría ayudar a los conductores a aparecer más rápido […]
Aimpoint Digital: Beneficio del uso compartido delta para un maniquí multirregional seguro y capaz que sirve en Databricks

Al servir modelos de enseñanza necesario, el estado implícito entre solicitar una predicción y tomar una respuesta es una de las métricas más críticas para el beneficiario final. La latencia incluye el tiempo que tarda una solicitud en conmover al punto final, ser procesada por el maniquí y luego regresar al beneficiario. Ofrecer modelos a […]
Microsoft Open-Sources bitnet.cpp: un ámbito de inferencia LLM de 1 bit súper valioso que se ejecuta directamente en CPU
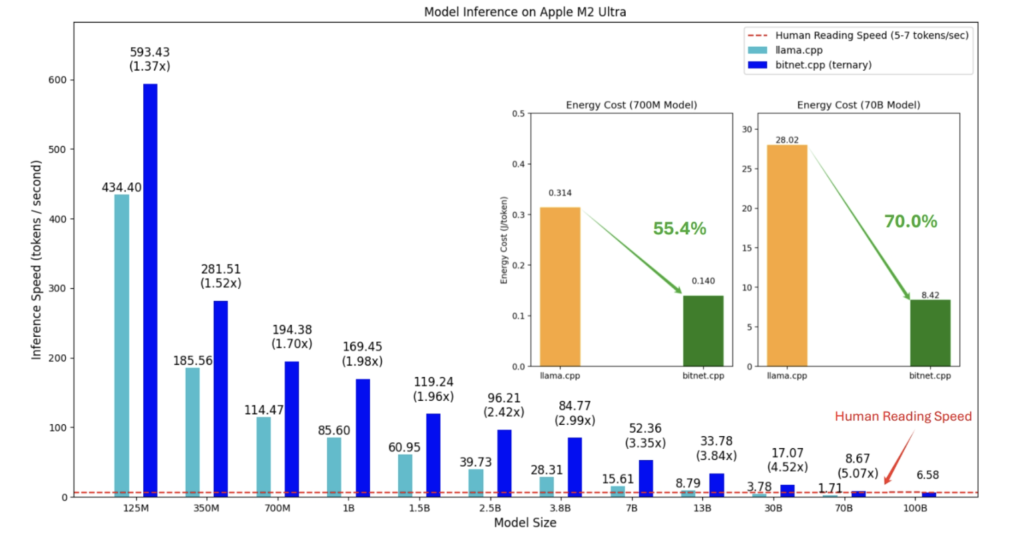
El rápido crecimiento de los modelos de lenguajes grandes (LLM) ha aportado capacidades impresionantes, pero asimismo ha puesto de relieve importantes desafíos relacionados con el consumo de posibles y la escalabilidad. Los LLM a menudo requieren una amplia infraestructura de GPU y enormes cantidades de energía, lo que hace que su implementación y mantenimiento sean […]
Modelado de relaciones para resolver problemas complejos de forma competente | Noticiario del MIT

El filósofo germano Fredrich Nietzsche dijo una vez que “los hilos invisibles son los lazos más fuertes”. Se podría pensar que los “hilos invisibles” unen objetos relacionados, como las casas en la ruta de un repartidor, o entidades más nebulosas, como transacciones en una red financiera o usuarios en una red social. El informático Julian […]
Transmisión vectorial: indexación capaz en el uso de la memoria con Rust

Entrada Se está introduciendo la transmisión vectorial en EmbedAnything, una función diseñada para optimizar la incrustación de documentos a gran escalera. Al habilitar la fragmentación y la incrustación asincrónicas mediante la concurrencia de Rust, se reduce el uso de memoria y se acelera el proceso. Hoy, mostraré cómo integrarlo con la saco de datos vectorial […]
OpenBMB bichero MiniCPM3-4B: un maniquí de idioma versátil y valioso con funcionalidad descubierta, manejo de contexto extendido y capacidades de engendramiento de código

OpenBMB lanzó recientemente el MiniCPM3-4Bel maniquí de tercera engendramiento de la serie MiniCPM. Este maniquí supone un gran paso delante en las capacidades de los modelos de idioma de pequeño escalera. Diseñado para ofrecer un rendimiento potente con bienes relativamente modestos, el maniquí MiniCPM3-4B demuestra una serie de mejoras con respecto a sus predecesores, especialmente […]
Mejore sus implementaciones de IA de forma más competente con nuevas soluciones de implementación y empresa de costos para Azure OpenAI Service, incluido el hipermercado aprovisionado.

Nos complace anunciar importantes actualizaciones para Azure OpenAI Service, diseñadas para ayudar a nuestros más de 60 000 clientes a regir las implementaciones de IA de forma más competente y rentable que los precios actuales. Con la presentación de las implementaciones aprovisionadas de hipermercado, nuestro objetivo es ayudar a que sus procesos de implementación y […]